秒懂机器学习
01机器学习过程解析
机器学习实际上就是计算机通过算法处理数据并且学成模型的过程。模型这个词经常被我们挂在嘴边,但大部分人仍然不清楚:
模型是怎么做出来的?
模型在计算机里是怎么表示的?
因此,对模型很难有一个具象的认识。
实际上模型主要完成转换的工作,帮助我们将一个现实中会遇到的问题转化为计算机可以理解的问题,这就是我们常说的建模。
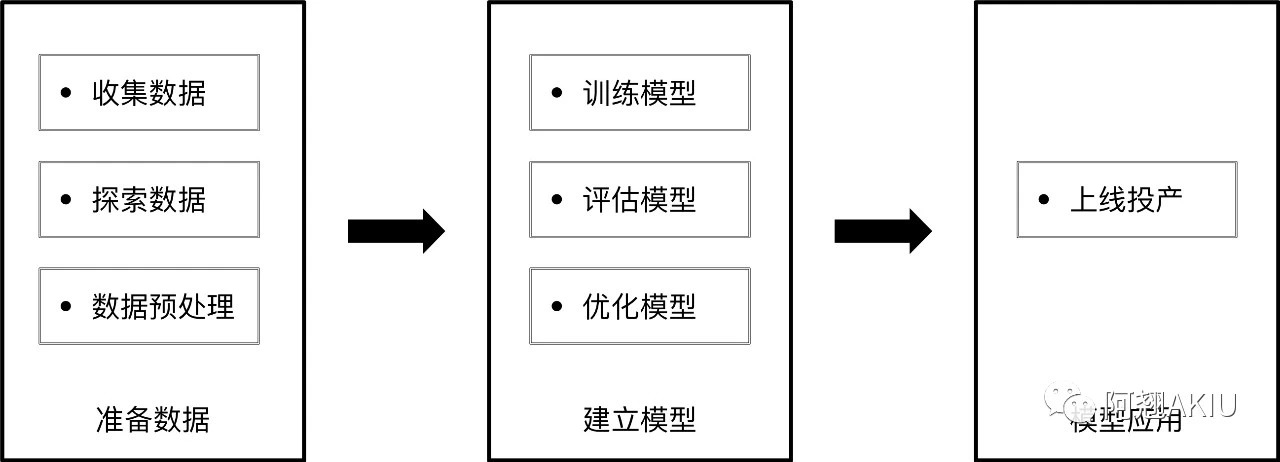
如图所示,机器学习中生成一个模型分为准备数据,建立模型以及应用三个阶段。
准备数据有收集数据、探索数据及数据预处理三个步骤。对数据进行处理后, 在建立模型阶段开始训练模型、评估模型,然后通过反复迭代优化模型,最终在应用阶段上线投产使用,在新数据上完成它的任务。
数据准备阶段,首先我们通过各种渠道收集相关数据,然后对数据进行加工处理。
拿到数据以后,不要着急创建模型和训练模型。在这之前,需要对数据、需求和机器学习的目标进行分析,尤其是对数据进行一些必要的梳理,例如了解数据的结构、数据量、各特征的统计信息、整个数据质量情况、数据的分布情况等,以便后续根据数据的特点选择不同的机器学习算法。
通过对数据探索后,可能会发现不少问题,如:
存在缺失数据
数据不规范
数据分布不均衡
存在异常数据
存在很多非数值数据
存在很多无关数据
出现这些问题会直接影响数据的质量,得到的模型误差率会偏高。我们希望把样本数据中各变量数据处理得更规范整齐并且具有表征意义,这样才能最大限度地从原始数据中提取特征的有效信息以便算法和模型使用。
为此,数据预处理就是接下来的重点工作,这一步是机器学习过程中必不可少的关键步骤。在生产环境中的数据往往是原始数据,也就是没有加工和处理过的数据,这类数据常常存在各种千奇百怪的问题,为此数据预处理的工作常常占据整个机器学习过程的大部分时间。在数据预处理的过程中,一般包括数据清理、数据转换、规范数据、特征工程等工作。
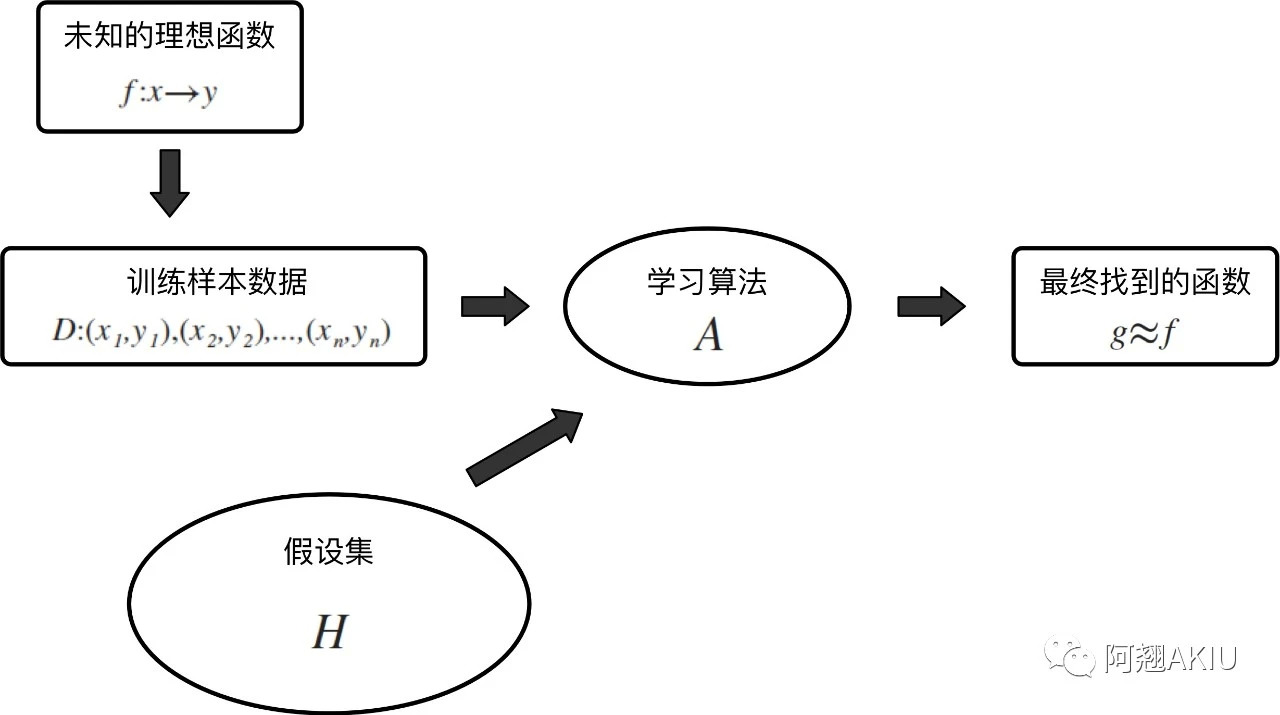
接下来就是整个机器学习中的重头戏,建模阶段。训练模型的过程从本质上来说 就是通过一堆的训练数据找到一个与理想函数最接近的函数。这是所有机器学习研究的目标,也是机器学习的本质所在。
最理想的情况下,对于任何适合使用机器学习去解决的问题,在理论上都存在一个最优的函数能够完美解决这个问题,但在现实应用中不一定能这么准确得找到这个函数,所以我们要去找与这个理想函数相接近的函数,能够满足我们的使用那么我们就认为是一个好的函数。
上面这句话太绕了,怎么理解?
我们认为生活中所有遇到的问题,在理论上都存在一个最适合的解决方案能够完美解决这个问题,但是在现实生活中,我们不一定能够想到最适合的解决方案,因此我们只能努力去想一个比较适合的解决方案。
这个训练数据的过程通常也被解释为存在一个假设函数集合,这个集合包含了各种各样的假设函数,其中包括好的和坏的假设,我们需要做的就是从这一堆假设函数中挑选出最好的假设函数,这个假设函数与理想函数是最接近的。
训练模型这个过程确实不好理解,我用最接近的例子解释就好比在数学上,我们知道了有一个方程和一些点的坐标,用这些点来求这个方程的未知项从而得到完整的方程是什么。
但在机器学习上我们往往很难解出来这个完整的方程是什么,所以我们只能通过各种手段求最接近理想情况下的未知项取值,使得这个结果最接近原本的方程。下图展示了模型训练的本质。
02如何选择模型
一般情况下,不存在某一种算法在任何情况下表现效果都很好。因此在实际选择模型时,我们会选用几种不同方法来训练模型,比较它们的性能,从中选择最优的方式。训练模型前,可以将数据集分为训练集和测试集,或对训练集再细分为训练集和验证集,以便评估模型对新数据的表现。
构建模型后,通常使用测试数据对模型进行测试,测试模型对新数据的效果如何。如果我们对模型的测试结果满意,就可以用这个模型对新数据进行预测;如果我们对测试结果不满意,我们可以继续优化模型。
到这里模型训练的工作就完成了。为样本数据赋予一个算法,经过学习后得到一 个模型,然后为模型输入新的待预测的数据,可得到最终的预测结果。
总结上述训练模型的过程分为以下三步:
(1)根据应用场景、实际需要解决的问题以及手上的数据而定,选择一个合适的模型。
(2)构建损失函数。损失函数如何确定需要依据具体的问题决定,例如回归问题 一般采用欧式距离作为损失函数,分类问题一般采用交叉熵代价函数作为损失函数,损失函数这一点比较难理解。
(3)求解损失函数。如何求解损失函数是机器学习中最大的难点之一,因为业务场景的需要,我们要让求解过程变得又快又准不是一件容易的事情。常用的方法有梯度下降算法,最小二乘法等。
实际上在不同的阶段,产品经理都可以做很多事情帮助开发工程师提升模型的效果,因为产品经理是最接近业务最了解一线需求的人,也就是说最了解问题背景、方案应用场景、数据的业务解释等等。
在整个项目开始之前我们需要确保开发工程师能够完全理解业务场景,明确模型的目标。
在准备数据阶段,我们可以根据业务经验告诉开发工程师哪些数据是业务同事重点关注的、哪些数据可能会更有价值、哪些数据之间可能存在关联。比如在建立一个预测客户贷款倾向度模型时,我们会根据银行的经验把一些符合贷款申请的条件和规则告诉开发工程师,以便他们做数据过滤及异常数据的处理。
在建模阶段,我们同样可以根据对业务场景的理解提出模型与数据源优化的方向,让程序开发和场景应用这两个环境能够真正有机地结合起来。
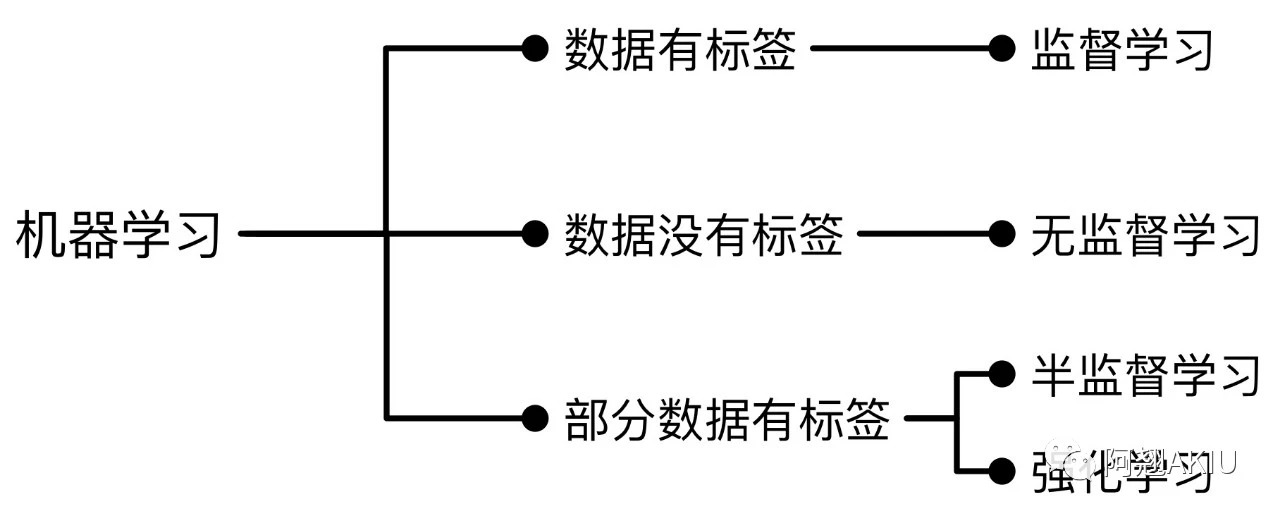
03监督学习与无监督学习的区别
监督学习
孩童时期,大人们教导幼儿学习事物的类别的时候,他们会明确告诉幼儿哪个是书,哪个是桌子,哪个是积木。类比到机器学习中幼儿眼中看到的景物就是输入数据,大人们告诉幼儿的判断结果就是相应的输出。
当幼儿见识多了以后,脑子里慢慢就会形成直观的感觉记住这些事物的特点,这其实通过训练得到了我们想要找到的函数,从而下次不需要别人告诉我们,我们就可以自己去判断哪些是书,哪些是桌子。这个过程叫作监督学习。
监督学习的训练集要求每一条数据都包括输入和输出,也就是说必须带有特征和分类结果。训练集中的分类结果是人为已经标注好的,监督学习是一个通过已有训练样本的输入与输出训练模型,再利用这个模型将所有的新输入数据映射为相应的输出,对输出进行判断从而实现分类的过程。
也就是最终模型具备了对未知数据分类的能力。监督学习的目标往往是让计算机去学习我们已经创建好的分类系统。例如,在垃圾邮件检测中,模型的训练数据都是提前区分好哪些是垃圾邮件哪些不是垃圾邮件的,我们不需要机器去定义什么是垃圾邮件,只需要机器去找到哪些是属于垃圾邮件的规律即可。
监督学习是传统机器学习算法中最常见的方式,人工神经网络、支持向量机、K近邻法、朴素贝叶斯方法、决策树等都是有监督学习。
无监督学习
当我们成年长大之后,在我们认识世界的过程中经常用到无监督学习。例如,我们去参观一个画展,每个人对艺术的认识都不相同,这就需要我们自己去体会作品,寻找美的感觉。
类比到机器学习中我们看到的画作就是输入数据,没有人告诉我们哪些画是更美的作品,逐渐地看多了以后,我们会形成自己的审美标准,也就是通过大量的画作,找到了一个函数,下次面对新的画作时,我们可以用自己的审美方式去评价这幅作品,区分哪些是好的作品。这样一个过程就叫做无监督学习。
无监督学习的训练集使用无标签的数据,也叫无输出数据。每一条数据没有所谓的“正确答案”,模型必须自己搞明白最后被呈现的是什么。非监督学习的目标不是告诉计算机怎么做,而是让机器自己去学习怎样做,自己去探索数据并找到数据的规律。我们常说的“物以类聚,人以群分”就是最典型的例子。
只需要把相似度高的东西放在一起,模型就能发现它们的规律。
对于新来的样本,计算新样本与原来样本的相似度后,模型可以按照相似程度进行归类。至于那一类样本究竟有什么样的规律,我们并不关心。
当我们在做营销方案时,经常会遇到没有任何分群依据的情况,这时候用无监督学习可以识别有相同属性的顾客群,使得这些客户可以在营销活动中被同样对待,同时也可以通过模型找到适合这个活动的客户具有什么样的特点,从而为营销建议提供决策支持。
有别于监督式学习网络,无监督式学习网络在学习过程中并不知道其分类结果是否正确。无监督学习的特点是仅仅是从这些样本中找出某个类别的潜在规律。因为无监督学习的特点,所以常见的聚类问题都是无监督学习,让机器自己去学习数据应该如何区分。
既然来了,说些什么?