设计在机器学习中的作用
如今,机器学习(ML)已成为几乎所有新软件产品的组成部分。对于设计师来说,有时会出现一个问题:“设计在机器学习中的作用是什么?” 设计人员如何参与创建机器学习动力产品的过程?我们一直在使用Salesforce的新Einstein Designer工具,该工具会自动生成设计变体以改善UX。尽管该项目专门针对设计的ML,但我们所学的内容更广泛地适用。在爱因斯坦设计师项目期间,我们的混合设计师/开发人员/数据科学家团队发现了将设计技术纳入ML项目的新方法。
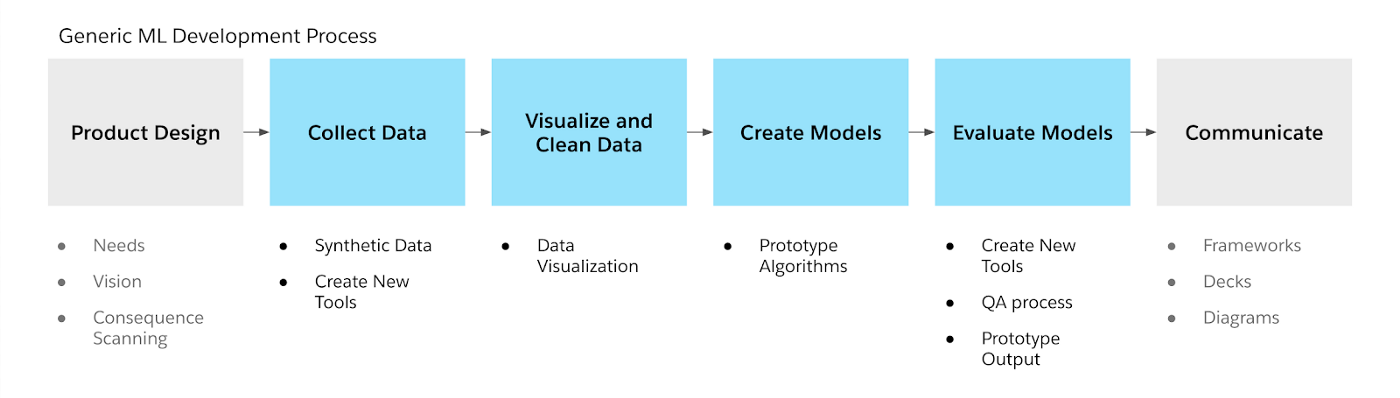
当您使用机器学习时,可以应用传统的设计功能-制定产品愿景并与利益相关者进行交流,但是ML还为表带来了新的因素。本文探讨了如何在ML开发中应用设计技术。从根本上讲,这一切都与数据有关-获取数据(大量!),清理数据,理解数据并最终在其之上构建软件。该过程如下所示:
- 收集数据
- 可视化和清理数据
- 创建模型和算法
- 评估那些模型和算法
收集数据
设计可以通过多种方式促进数据收集。最直接的是设计数据收集工具。将此视为产品设计的子集,有一些主要区别。数据收集工具通常是面向内部的,以产品团队为用户。生产力是关键,该工具需要与团队一起发展。数据收集也是发现过程的一部分。标签和可视化对团队对话和指导有巨大影响,清晰有效的用户界面至关重要。
在理想的世界中,开发团队可以访问大型,干净的公共数据集,但我们经常需要收集自己的数据。该过程的这一部分很少发布或讨论;大多数团队会创建自己的解决方案,这会增加时间和成本。有时您必须记录一段时间的数据。有时,原始字节存在,但必须将其收集到统一的数据集中,这使得收集工具非常有价值。
要弄清楚收集工具需要什么功能,请通过产品设计的角度查看问题。例如,对于Einstein Designer,我们构建了一个工具,该工具可以读取网页,截屏并使用其中的信息来创建网站设计系统的高级预览。我们已经在许多站点上运行了此过程,并在我们进一步了解重要信息时重复进行此过程,因此,提高其效率的工具至关重要。
一些设计贡献更重要。取得按钮和部分标签,这些标签通常包含关键术语。使它们清晰一致可以帮助澄清设计问题。在数据收集工具中,我们将矩阵之一和单个文本样式的列表标记为“调色板”,这有助于团队成员理解该术语的范围并将其与其他关键概念区分开。
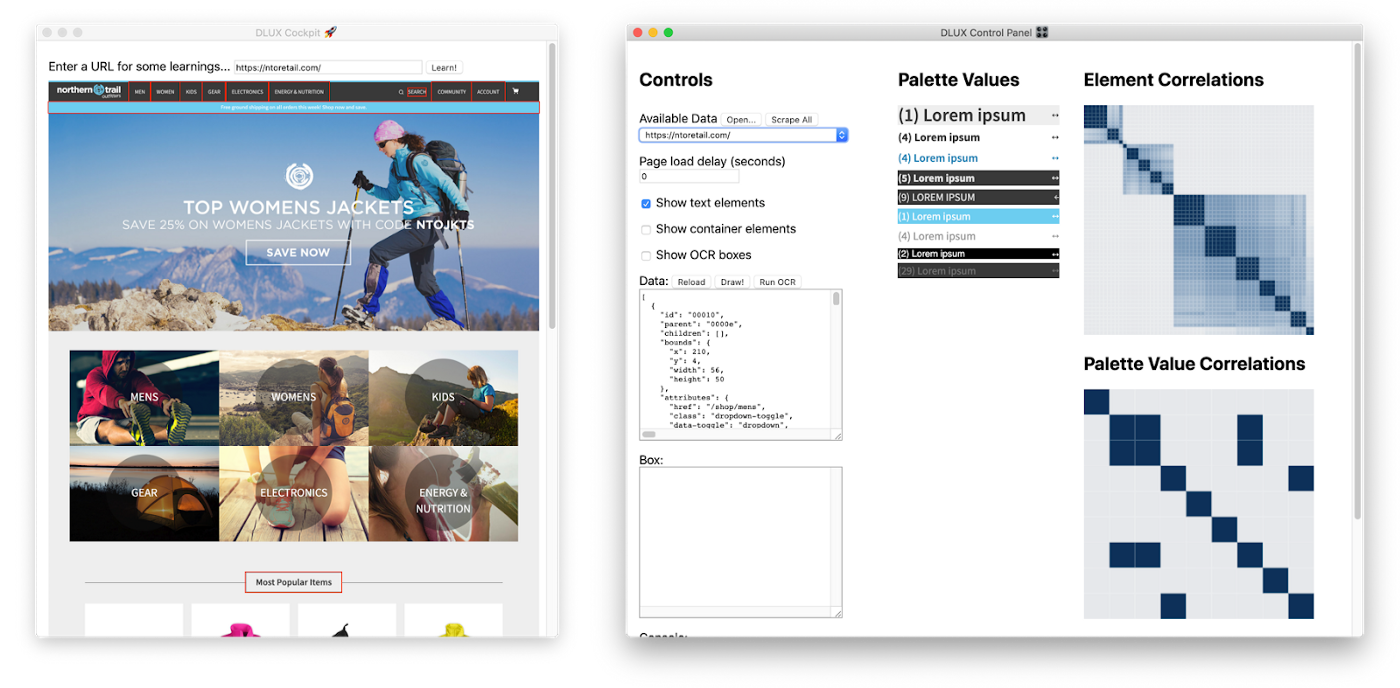
为机器学习而收集的数据通常没有标签,缺少描述如何分类的描述符。例如,我们可能有一堆图像,但是没有描述它们包含的内容的描述者,例如猫或狗。通常,人类必须标记数据。
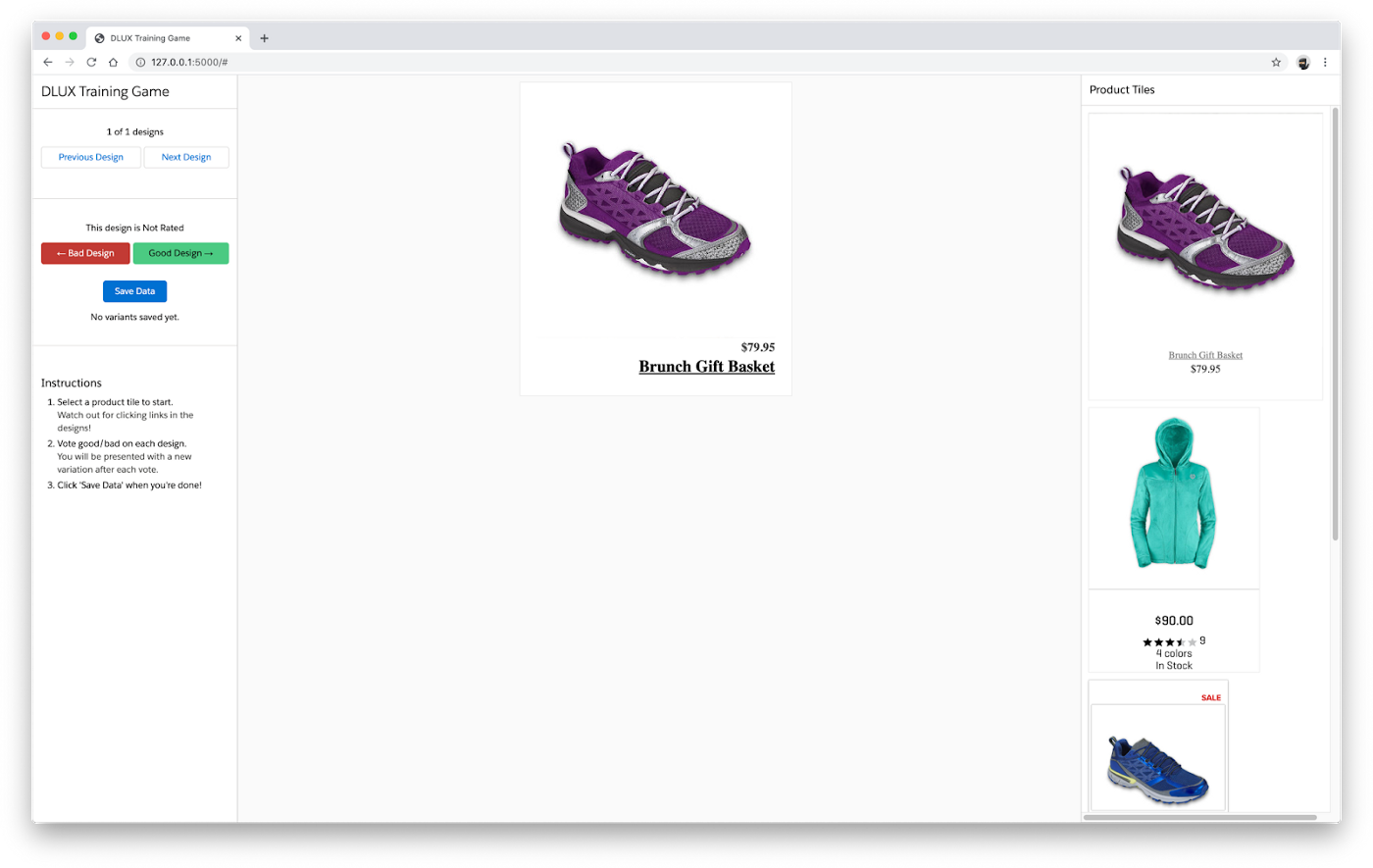
为了加快爱因斯坦设计师的这一过程,我们建立了一种类似于游戏的体验,在这种体验中,人类用户被要求使用键盘箭头键将产品图块的设计分为好坏。然后,通过图像的总分来定义设计质量。作为设计师,我们通过创建清晰的功能性UI并使评估过程尽可能无缝地为该过程做出了贡献。交互越简单,用户可以评估的图像就越多。在这种情况下,速度也迫使用户做出直观的判断。由于消费者用户还将做出瞬间决策,因此有助于创建类似数据。
机器学习的另一个令人兴奋的领域是合成数据。构造为反映对真实数据的期望,它用于在访问大型真实数据集之前引导ML模型。对于正在训练模型以了解设计的爱因斯坦设计师,我们很幸运拥有Sketch,这是一个用于生成新设计的强大工具,可以提供生成的设计的图像以及可以紧密镜像收集的Web数据的JSON表示形式。我们首先根据合成的Sketch数据训练模型,然后再使用来自网络的真实数据扩充这些相同的模型。
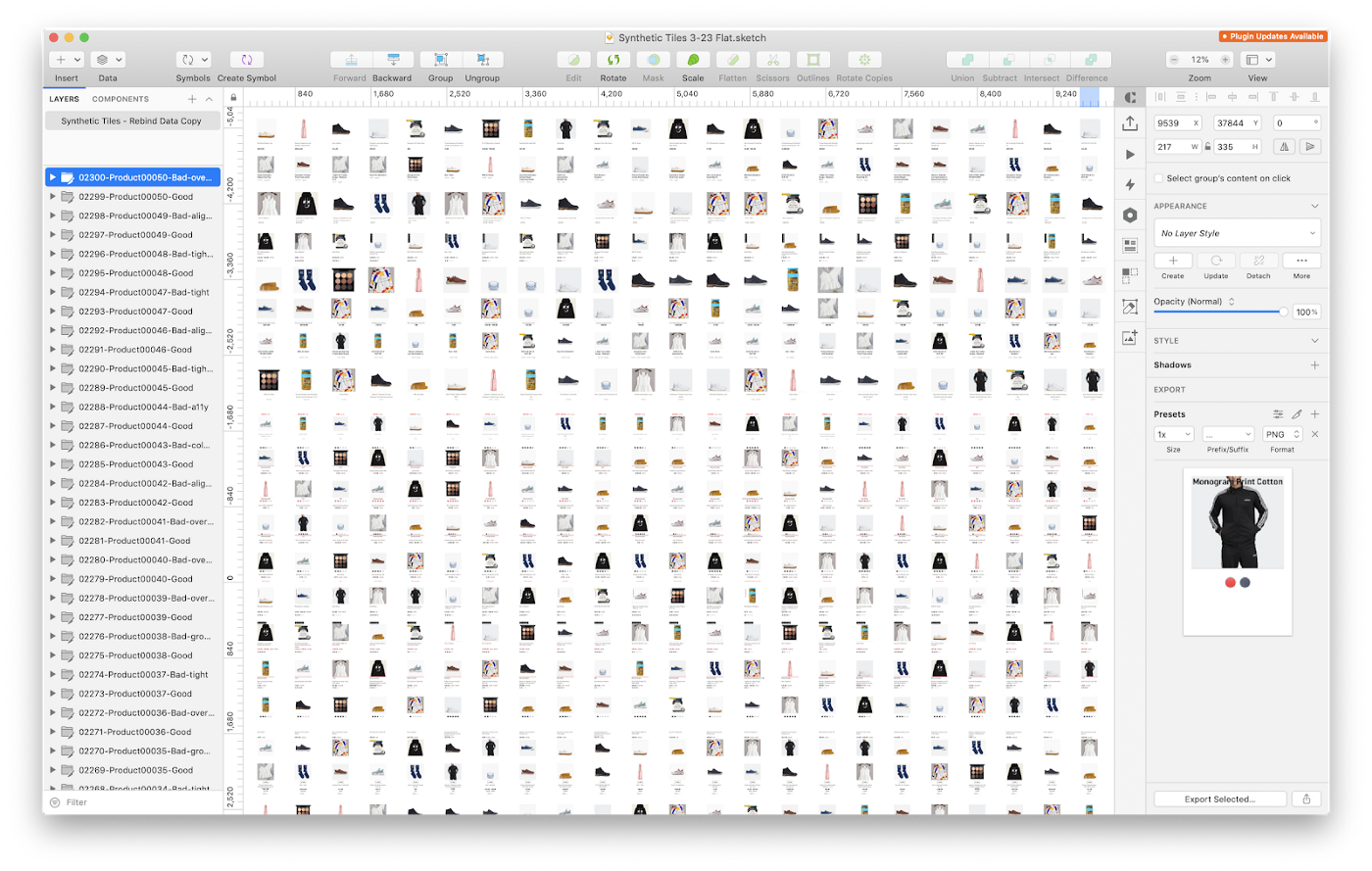
我们使用Sketch创建了50个设计模板,大量使用了符号和自动布局,因此随着数据的变化,它们仍然看起来不错-这一过程非常类似于真实的Web设计工程。接下来,我们使用Sketch的数据功能将模板与自定义值关联起来。对于每个模板,我们都会创建好版本和坏版本,以某种特定方式破坏设计,例如重叠或未对齐的文本。然后,我们将这些克隆克隆了25次,以生成2500个带标签的示例(50X2X25 = 2500)。每个附带草图数据的克隆都将创建一个唯一的示例,从而获得平衡的数据集。最后,我们系统地标记了所有层。
清洁数据
ML开发的下一步是清理数据。如果您使用的是综合数据,则此操作已经完成-否则,需要进行一些清理。无论哪种方式,可视化数据都将帮助您了解其中的实际内容。
再次,设计师具有宝贵的技能可以带到餐桌上。无论您是在白板上绘制可能的图还是使用Python或D3创建它们,都可以使用设计过程来进行可视化思考。

创建模型
有了干净的数据集并了解其内容后,下一步就是根据您的见解创建算法或模型。尽管直接进入代码并开始训练模型可能很诱人,但我们发现首先使用lo-fi设计原型来尝试算法很有用。例如,我们通过简单地在幻灯片上创建设计选项矩阵来原型化生成设计工具的输出。然后,我们要求客户消除所有不符合其品牌准则的设计。这使我们对服务的产品要求充满信心,并帮助我们了解用户可能要采取的措施。
您还可以对算法本身进行原型设计,以了解在给定数据下可能进行哪些类型的预测。例如,我们想训练一个模型来理解品牌的现有风格指南。我们可以收集网站上使用的个别样式,但是想了解这些样式如何协同工作。我们意识到我们可以为该任务建立多种方法的原型,并仅通过绘制样式就能直观地了解如何正确使用样式。
我们创建了输入数据并写下了所提出算法的规则,然后由团队成员在Sketch中手动执行。该过程表明,在原始页面中创建彼此跟随的样式对是理解设计之间关系的最佳方法。这也使我们有信心开始自动化样式关系集合并进一步完善我们的方法。
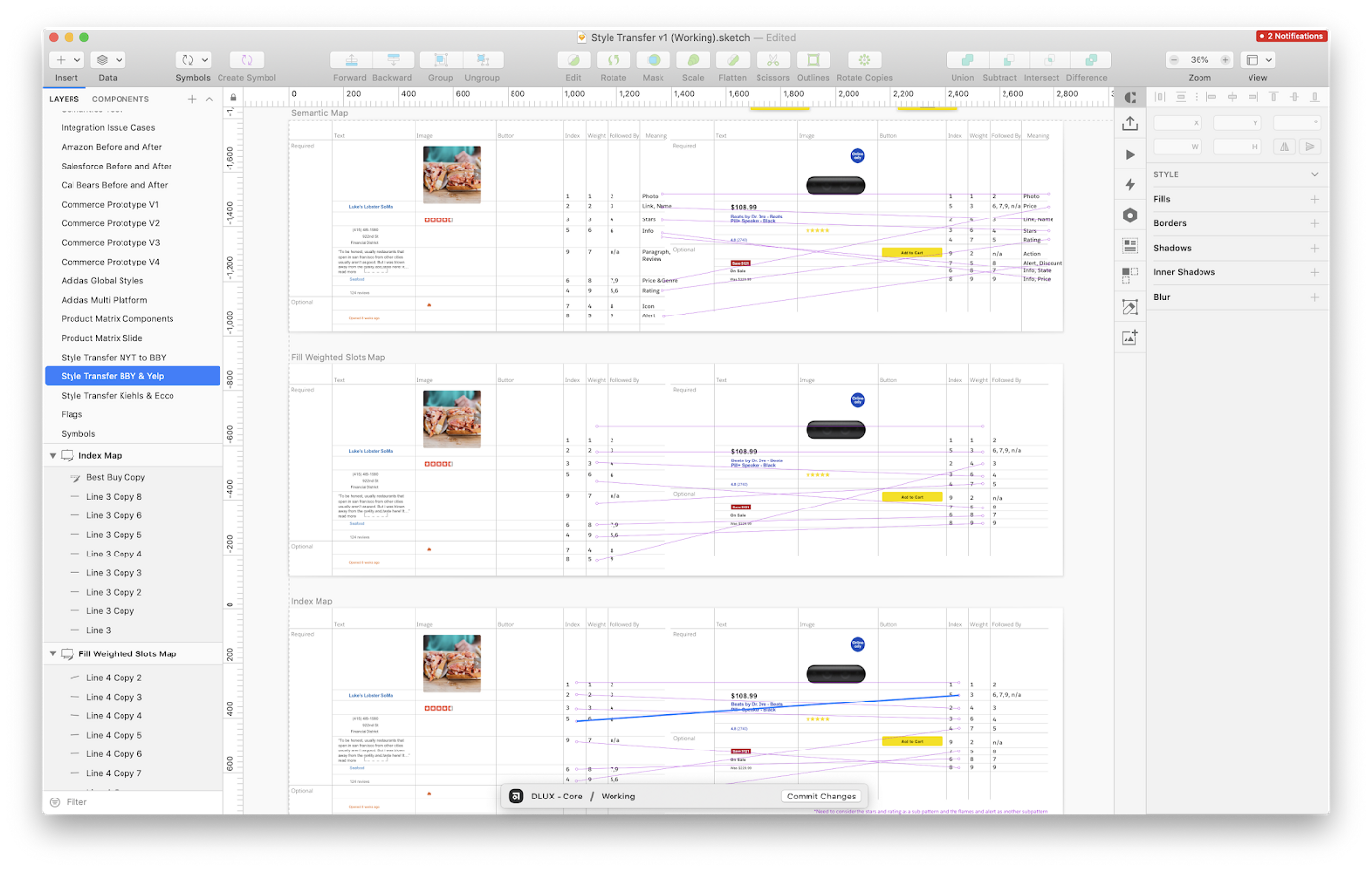
此练习还支持了我们的直觉,即某些算法将不起作用。人类无法完美地模拟机器学习算法,但是机器学习不是魔术。必须有一些基本的模式或信息来告诉算法该怎么做。例如,我们想知道设计生成器选择合适的字体大小所需的信息很少。我们要求团队成员仅根据数据类型和设计层次结构中的位置来绘制设计,然后很快发现有必要更多地了解这些值。像人类设计师一样,为了做出适当的选择,算法需要知道每个字段中大约的文本量。
评估模型
创建算法和模型后,您需要识别,学习并纠正错误和偏见。设计在这里可以在创建工具以简化评估过程中发挥重要作用。
对于爱因斯坦设计师,我们需要评估生成模型的输出。尽管没有简单的方法可以自动对设计质量进行评分,但我们可以构建一个工具来评估结果。我们的流程借鉴了用户研究和设计领导者的最佳实践,包括芝加哥IIT设计与英里学院的Charles Owens和Huberman的定性数据分析。
首先,我们创建了一个工具,使团队中的每个人都可以可视化和查看相同的设计。它整理了一组测试用例,为每个用例创建了标准化的输入,并让我们一致地测试我们的系统。与实际产品中用户只能看到最高质量的输出不同,它显示了模型的完整输出,以帮助我们了解其功能。
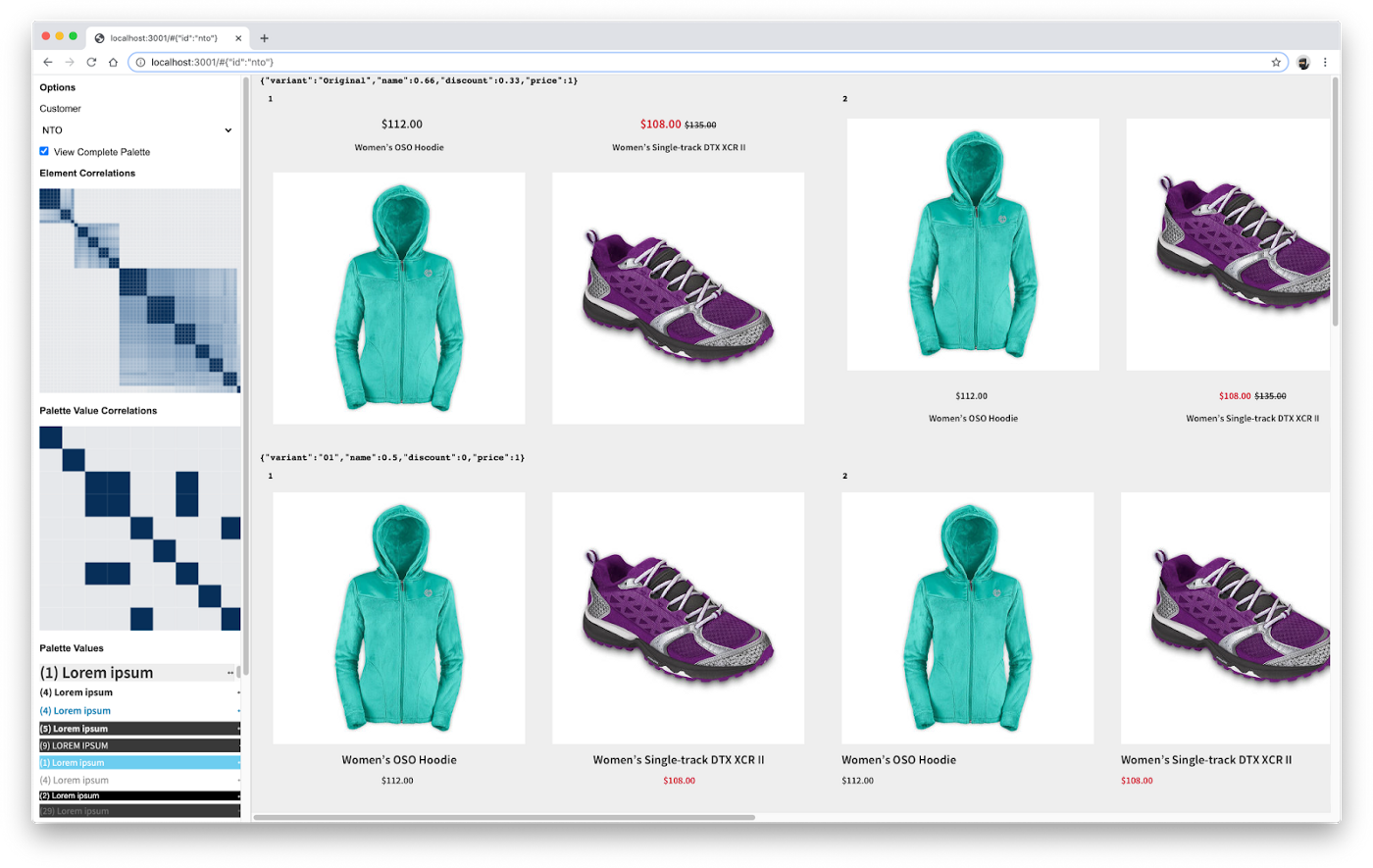
接下来,团队的每个成员都使用该工具对设计进行独立排名,这与研究人员可能会编写成绩单以量化定性数据的方式很相似。
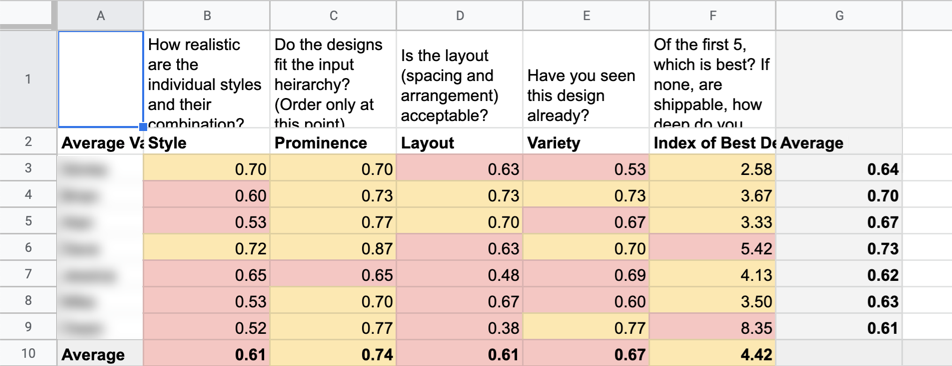
例如,在Owen的IIT结构化计划课程中,要求每个学生对各个主题的相关性进行排名。然后将得到的数据进行组合,并用于告知哪些主题对于设计项目最为重要。通过标准化学生在比较主题时提出的问题,可以分配作业和进行聚类并比较结果。并且让多个学生对同一数据进行排名有助于减少个人偏见的影响。
我们采用相同的方法,让每个团队成员对设计进行排名,然后结合结果以生成更客观的设计质量视图,这是一个固有的主观主题。在每个设计冲刺的末尾重复此过程有助于我们跟踪实现稳健的设计生成产品目标的进度。
随着机器学习在产品设计中变得越来越重要,请记住考虑设计如何发挥作用。识别和传达需求,可视化数据,原型设计,构建工具以及进行研究等核心设计技能在核心机器学习过程中均扮演着重要角色。最重要的是,请记住该过程是协作的,每个人都可以参与,更多的观点可以带来更好的产品。
原文:https://medium.com/salesforce-ux/the-role-of-design-in-machine-learning-ae968ea90aac
既然来了,说些什么?