SlimX系列13个小模型
模型小型化,why?
AI服务的计算环境发生了翻天覆地的变化,已逐渐从云端向移动端和IoT蔓延渗透。据统计,近几年AIoT的市场规模以40%以上的实际速度在增长,而且预期未来几年还保持着一个相当高的增长趋势。与此同时,也带来了前所未有的新型交互需求。比如,在智能屏音箱上,不方便语音的时候使用手势控制;看视频时,在耗电量微乎其微的情况下,可以通过表情识别,为你喜欢的视频自动点赞。
 图 1 沉浸式、无感知的新型交互需求
图 1 沉浸式、无感知的新型交互需求
然而,一个反差是,硬件的计算能力,从云到移动端、到IoT,算力以三个数量级的比例在下降,内存也在大幅下降,尤其是边缘芯片内存只有100K。而实际需要运行在这些AIoT设备上的算法需要关注的三个方面,即:算法效果(精度)、计算速度(FLOPs)、模型大小。最理想的选择是算法效果好、计算量低,尤其是实际耗时要少,同时,模型要小到内存足够放得下。
而云端上的经验告诉我们,要想效果好,模型得足够大!
那怎么样解决这个矛盾呢?很多专家提供人工经验去设计端上的模型,并且得到了广泛的应用。
然而这些依旧存在两个问题:
- 如何利用现存优秀的云端模型。
- 如何产生任务自适应的模型。
对于这两个问题,我们给出的答案是:模型小型化!
 图2 PaddleSlim-效果不降的模型压缩工具箱
图2 PaddleSlim-效果不降的模型压缩工具箱
我们希望在有限计算资源的情况下保持效果不降,对已有模型进行压缩,并针对任务自动设计出新模型,这些功能都浓缩在百度飞桨和视觉团队共同研发的PaddleSlim工具箱里,自去年对外开源PaddleSlim,这个工具箱的内容到现在一直还在持续丰富,从量化、蒸馏、剪枝到网络结构搜索,一应俱全。
截止到现在,我们通过PaddleSlim打磨出了用于通用任务的分类、检测和用于垂类任务的人脸识别、文字识别(OCR)等多个业界领先的工业级小模型,它们是SlimMobileNet、SlimFaceNet、SlimDetNet、SlimTextNet等等。
为了进一步促进模型小型化技术的产业应用,PaddleSlim将开源所有Slim系列模型!
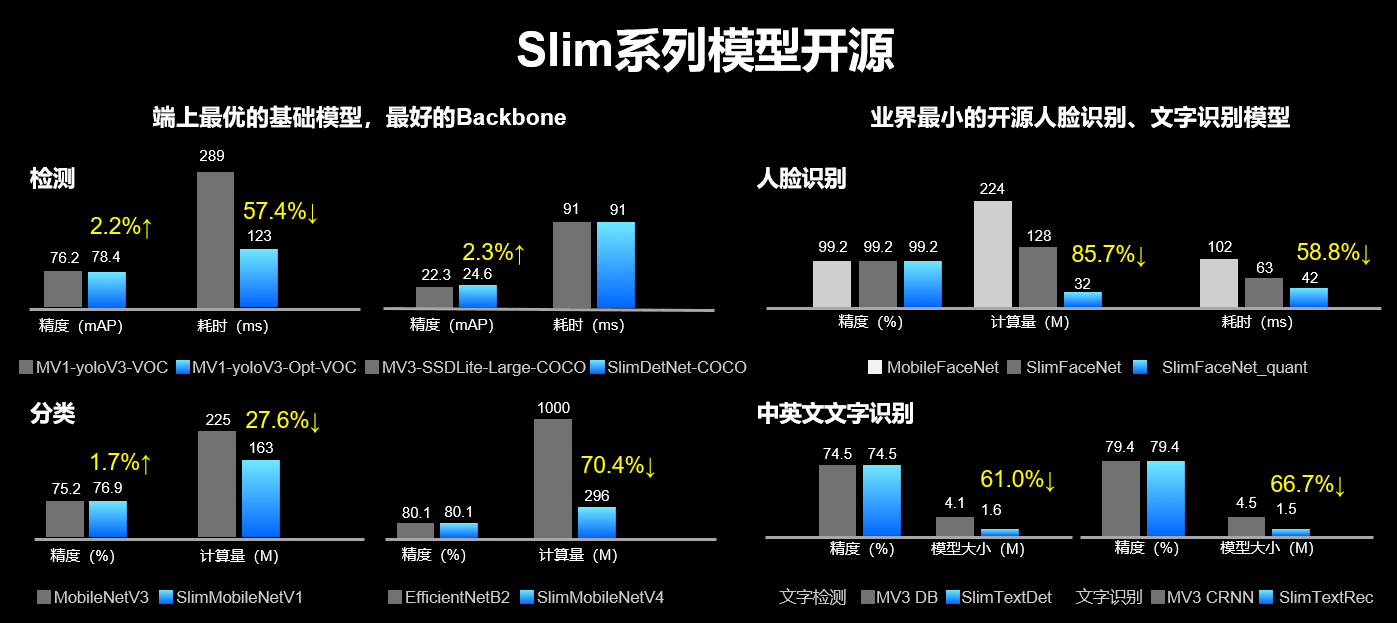 图3 Slim系列模型开源
图3 Slim系列模型开源
PaddleSlim分类、检测最新优化
近日,PaddleSlim发布了SlimMobileNet、SlimFaceNet、SlimDetNet、SlimTextNet四大系列13个业界领先的工业级小模型。
分类:CVPR冠军模型,业界首个开源的FLOPs不超300M、ImageNet精度超过80%的分类小模型
在图像分类任务上,PaddleSlim发布的SlimMobileNet是基于百度自研的GP-NAS(CVPR2020)AutoDL技术以及自研的蒸馏技术得到。
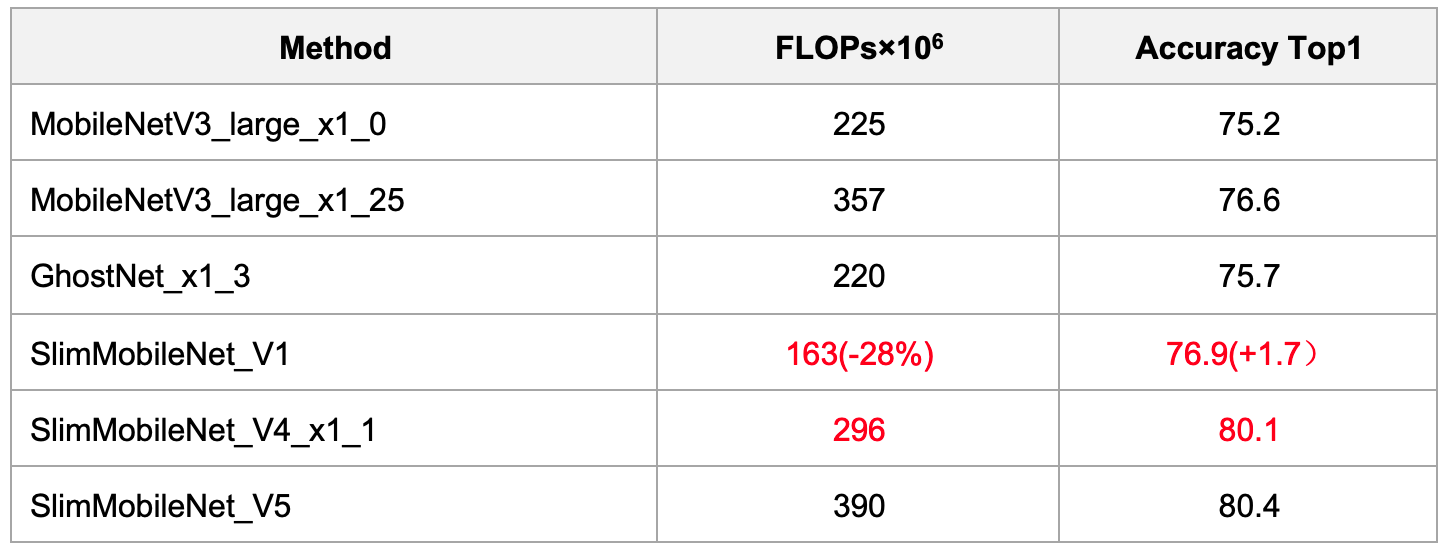 表1 SlimMobileNet分类小模型
表1 SlimMobileNet分类小模型
在ImageNet 1000分类任务上,相比于MobileNetV3, SlimMobileNet_V1在精度提升1.7个点的情况下FLOPs可以压缩28%。SlimMobileNet_V4_x1_1为业界首个开源的FLOPs不超300M,ImageNet精度超过80%的分类小模型。
值得特别提及的是,CVPR的低功耗计算视觉比赛(CVPR 2020 LOW-POWER COMPUTER VISION CHALLENGE)也刚刚宣布了结果,百度联合清华大学在竞争最激烈的Real-time Image Classification Using Pixel 4 CPU 赛道中击败众多强劲对手取得冠军。本次发布的开源分类模型中就包含了此次比赛的冠军模型。
检测:最适合端侧部署的基于PaddleDetection的产业级检测模型
除了分类任务以外,如今目标检测已经产业应用的重要方向,它可以被广泛应用于工业产品检测、智能导航、视频监控等各个应用领域,帮助政府机关和广大企业提高工作效率。
PaddleDetection发布了一系列YOLO模型,PaddleSlim在其基础上进行了蒸馏、量化和剪枝等压缩操作,产出了SlimDetNet系列图像目标检测模型。以MobileNetV1网络为主干的YOLOv3模型,适用于移动端部署环境,因为冗余信息更少,所以压缩难度较大,在PaddleSlim剪枝和蒸馏的共同作用下模型参数和计算量均有65%以上的减少,同时精度只有略微的降低。具体实验数据如表2所示。
注:SlimDetNet v2(MV3_YOLOv3)输入大小为320,测试环境是骁龙845;SlimDetNet v1(MobileNetV1-YOLOv3)输入大小为608,测试环境是骁龙855。
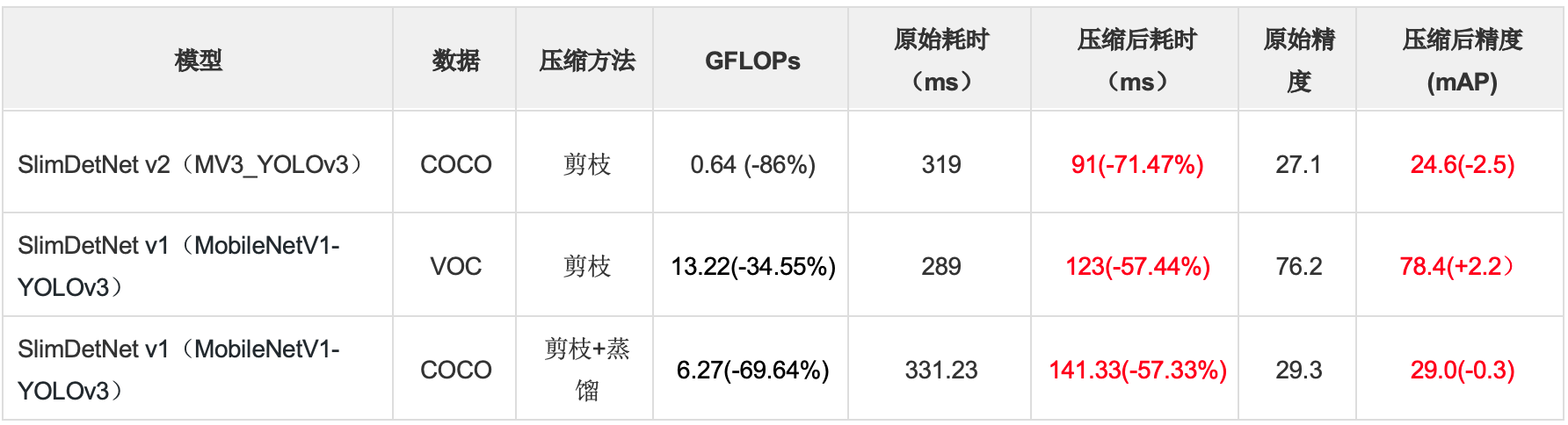 表2 SlimDetNet检测小模型
表2 SlimDetNet检测小模型
业界最小的开源人脸识别模型
除了基础模型,PaddleSlim还开源了垂类模型。众所周知,人脸识别和文字识别是工业化大生产中最常用的两项视觉技术。
首先看一下人脸识别。人脸识别技术作为目前AI技术落地最广泛的技术之一,广泛应用于人脸解锁、考勤、支付、身份识别等各个场景。如何在嵌入式设备上高效的执行人脸识别算法成为制约相关应用的关键因素。
SlimFaceNet同样是基于百度自研的GP-NAS AutoDL技术以及百度自研的自监督超网络训练算法得到,如表3所示。
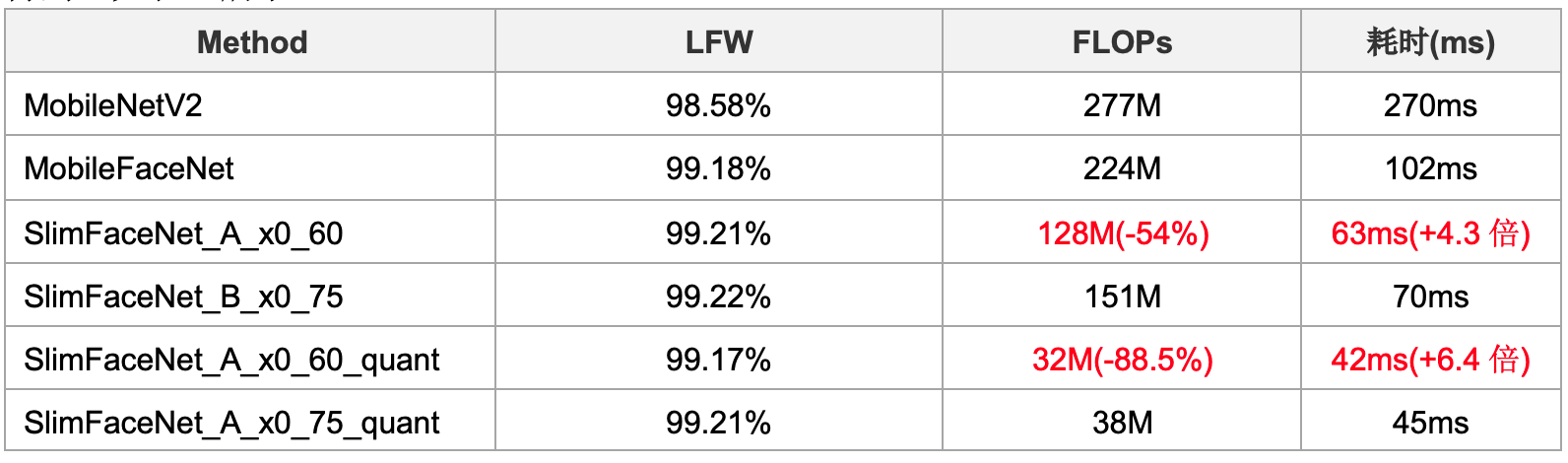 表3 SlimFaceNet与现有模型对比
表3 SlimFaceNet与现有模型对比
相比于MobileNetV2,SlimFaceNet_A_x0_60 FLOPs压缩54%,在RK3288上加速4.3倍。基于PaddleSlim的离线量化功能还可以进一步压缩模型,相比于MobileNetV2,SlimFaceNet_A_x0_60_quant FLOPs可以压缩88.5%,在RK3288硬件上可以加速6.4倍。
MobileFaceNet是之前业界开源的一个网络,SlimFaceNet_A_x_60_quant计算量只有MobileFaceNet的七分之一,延时降低了59%。
业界最小的开源文字识别模型
再来看一看OCR,OCR技术有着丰富的应用场景,包括已经在日常生活中广泛应用的面向垂类的结构化文本识别,如车牌识别、银行卡信息识别、身份证信息识别、火车票信息识别等等,此外,通用OCR技术也有广泛的应用,如在视频场景中,经常使用OCR技术进行字幕自动翻译、内容安全监控等等,或者与视觉特征相结合,完成视频理解、视频搜索等任务。
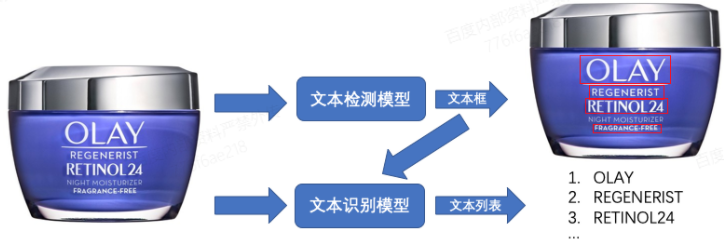 图4 OCR识别工作流程
图4 OCR识别工作流程
6月份的时候飞桨开源了一个8.6兆的OCR,业界反响热烈,登上了Github的Trending,现在我们又开源一个更加优质的模型,效果不降,但是模型大小只有3.1兆,并达到了30%的加速。
各个模型具体压缩情况如表4所示。
注:表中识别模型耗时为单个候选框的识别耗时,一张图片可能有多个候选框。使用自建中文数据集,测试环境是骁龙855。
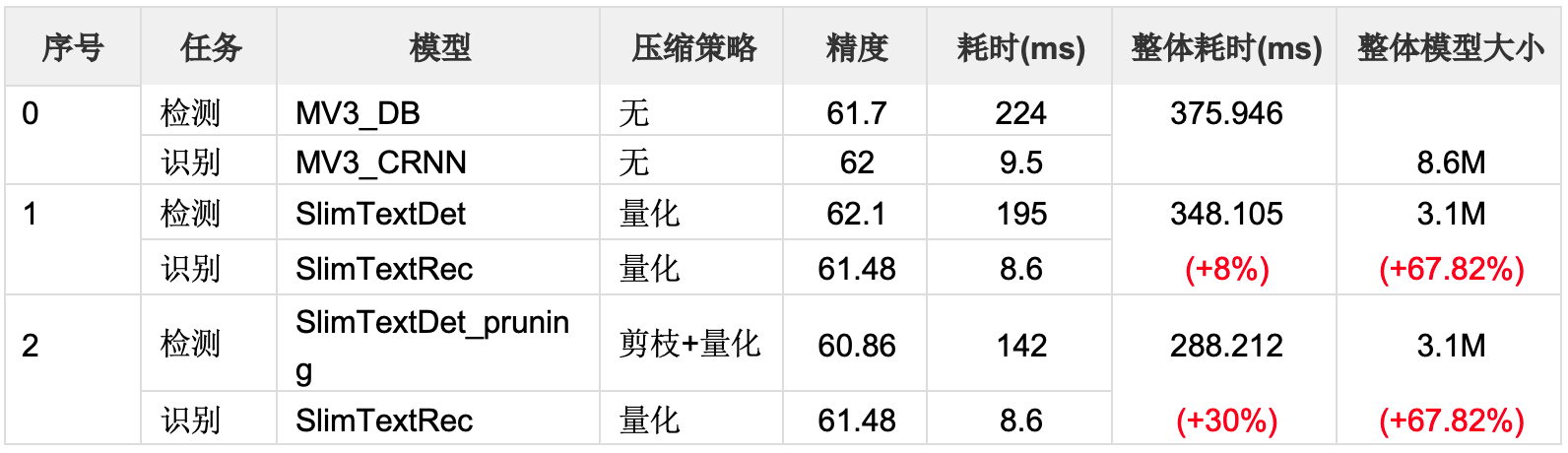 表4 SlimText系列小模型
表4 SlimText系列小模型
我们是如何做到的
以上业界最小的模型全部都基于飞桨模型压缩库PaddleSlim实现。它们的实现方式不尽相同,其中,人脸识别模型和分类模型使用了搜索压缩策略;检测与OCR使用了经典的量化、剪枝和蒸馏策略。
搜索压缩策略简介
继PaddleSlim分布式SA-NAS在CVPR 2020 Real Image Denoising rawRGB Track夺冠后,GP-NAS包揽了ECCV 2020 Real Image Super-Resolution Challenge全部3项track的冠军。其中,SA-NAS搜索方法是百度首次把NAS技术应用于图像降噪领域。
GP-NAS搜索方法是百度首次把NAS技术应用于图像超分领域。目前为止,百度自研的SA-NAS和GP-NAS AutoDL技术已在CVPR19,ICME19,CVPR20,ECCV20 夺得7项世界第一,提交200余项中国/美国专利申请。
基于自监督的Oneshot-NAS
超网络训练方法
One-Shot NAS是一种自动搜索方法。它将超网络训练与搜索完全解耦,可以灵活的适用于不同的约束条件,超网络训练过程中显存占用低,所有结构共享超网络权重,搜索耗时加速显著。与此同时,我们还研发了基于自监督的排序一致性算法,以确保超网络性能与模型最终性能的一致性。
如图5所示,超网络的训练还可以与蒸馏和量化深度结合,如在超网络训练过程中加入蒸馏损失函数,可以得到一致性蒸馏超网络(基于该超网络可以搜索得到最适合特定teacher模型的student模型);如在超网络训练过程中加入量化损失函数,可以得到一致性量化超网络(基于该超网络可以搜索得到精度高且对量化不敏感的模型结构)。基于一致性超网络,PaddleSlim使用百度自研的GP-NAS算法进行模型结构自动搜索。
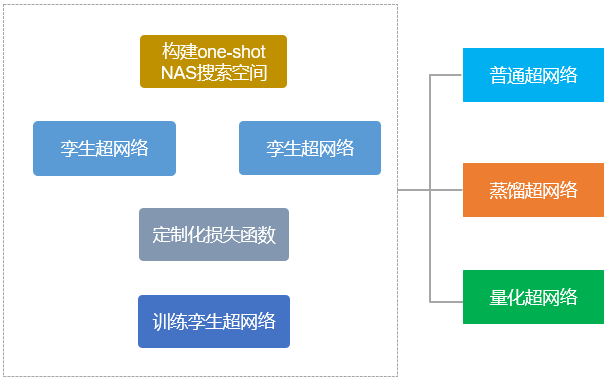 图5 基于自监督的超网络训练
图5 基于自监督的超网络训练
基于高斯过程的模型结构
自动搜索GP-NAS
GP-NAS从贝叶斯角度来建模NAS,并为不同的搜索空间设计了定制化的高斯过程均值函数和核函数。图6为GP-NAS的架构图,具体来说,基于GP-NAS的超参数,我们有能力高效率的预测搜索空间中任意模型结构的性能。从而,模型结构自动搜索问题就被转换为GP-NAS高斯过程的超参数估计问题。接下来,通过互信息最大化采样算法,我们可以有效地对模型结构进行采样。因此,根据采样网络的性能,我们可以有效的逐步更新GP-NAS超参数的后验分布。基于估计出的GP-NAS超参数,我们可以预测出满足特定延时约束的最优的模型结构,更详细的技术细节请参考GP-NAS论文。
GP-NAS论文地址:
https://openaccess.thecvf.com/content_CVPR_2020/papers/Li_GP-NAS_Gaussian_Process_Based_Neural_Architecture_Search_CVPR_2020_paper.pdf
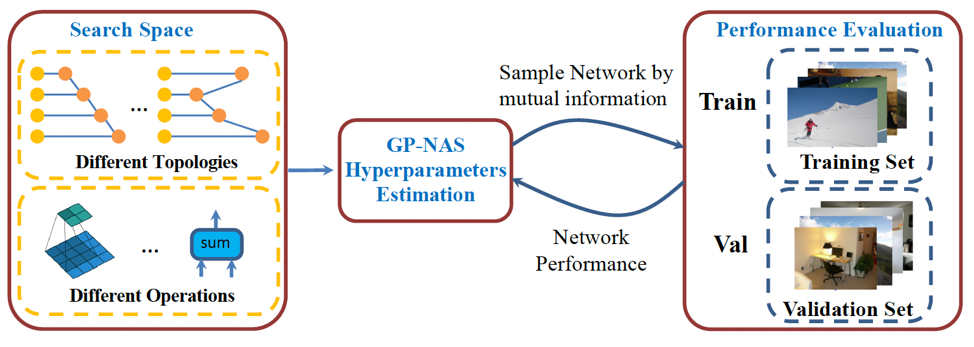 图6 基于高斯过程的模型结构自动搜索GP-NAS
图6 基于高斯过程的模型结构自动搜索GP-NAS
量化、剪枝、蒸馏
接下来,以文字检测和识别为例,简要介绍使用经典压缩策略做模型压缩的一般思路。
第一步:分析模型参数量分布
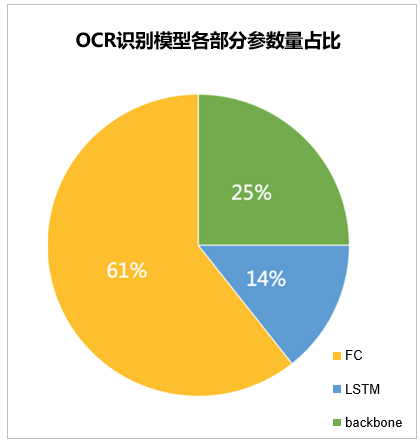 图7 OCR识别模型各部分参数量占比
图7 OCR识别模型各部分参数量占比
如图7所示,OCR识别模型的参数主要集中在FC层和backbone层。另外考虑到当前没有对FC进行剪枝的有效的方法,所以我优先选择对FC层和backbone进行PACT量化训练。对于OCR检测模型,我们将其拆为backbone和head两部分进行分析对比,结果如图8所示。
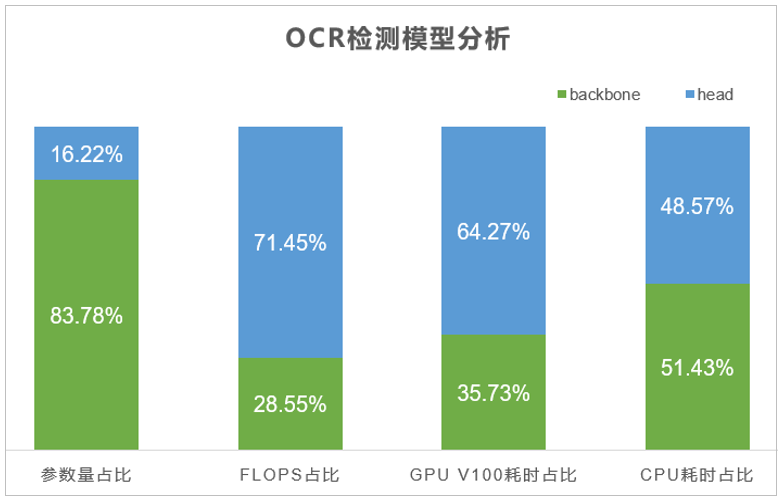 图8 OCR检测模型分析
图8 OCR检测模型分析
第二步:制定模型压缩方案
根据第一步的分析,我们制定以下压缩方案:
- OCR识别模型:对backbone和FC层进行PACT量化训练
- OCR检测模型:对head部分先进行剪枝,然后再进行PACT量化训练
第三步:实施模型压缩
按照第二步制定计划对各个模型进行压缩。其中,在对识别模型和检测模型进行PACT量化训练时,可以根据PaddleSlim提供的PACT自动调参教程自动计算出最合适的参数。教程详见:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/demo/quant/pact_quant_aware
对检测模型的head部分进行剪枝时,推荐使用PaddleSlim的敏感度分析方法和FPGM通道重要性评估方式。相关教程详见:
https://github.com/PaddlePaddle/PaddleSlim/blob/develop/docs/zh_cn/tutorials/image_classification_sensitivity_analysis_tutorial.md
OCR模型压缩方案的完整代码和教程请参考:
https://aistudio.baidu.com/aistudio/projectdetail/898523
参考链接
本文示例代码放在百度一站式在线开发平台AI Studio上,链接如下:
https://aistudio.baidu.com/aistudio/projectdetail/898523
本文提到的Slim系列小模型的更多详细内容请参见PaddleSlim项目地址:
https://github.com/PaddlePaddle/PaddleSlim
PaddleSlim是基于百度飞桨提供的开源深度学习模型压缩工具,集深度学习模型压缩中常用的量化、剪枝、蒸馏、模型结构搜索、模型硬件搜索等方法与一体。目前,依靠PaddleSlim百度大脑打造了三位一体的度目系列自研产品,当PaddleSlim和其他视觉算法在硬件上结合时,也赋能了许多其他应用场景,小度在家的手势控制;好看视频APP的表情识别;国家电网智能巡检解决方案……从智慧分析、智慧社区,再到驾驶管理、产业赋能,基于PaddleSlim百度大脑已经打造出一个特有的“软+硬”视觉时代,并时刻守护生活的每个角落。
原文:https://mp.weixin.qq.com/s/N5J8iwh6vsX2ZtBKyxLT4g
既然来了,说些什么?