机器学习在高德搜索建议中的应用优化实践
导读:高德的愿景是:连接真实世界,让出行更美好。为了实现愿景,我们要处理好 LBS 大数据和用户之间的智能链接。信息检索是其中的关键技术,而搜索建议又是检索服务不可或缺的组成部分。
本文将主要介绍机器学习在高德搜索建议的具体应用,尤其是在模型优化方面进行的一些尝试,这些探索和实践都已历经验证,取得了不错的效果,并且为后来几年个性化、深度学习、向量索引的应用奠定了基础。
对搜索排序模块做重构
搜索建议(suggest 服务)是指:用户在输入框输入 query 的过程中,为用户自动补全 query 或 POI(Point of Interest,兴趣点,地理信息系统中可以是商铺、小区、公交站等地理位置标注信息),罗列出补全后的所有候选项,并进行智能排序。
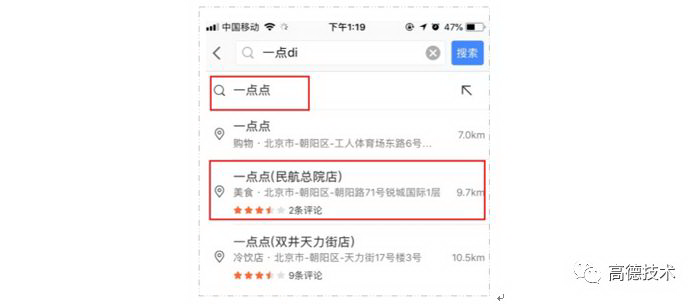
我们希望通过 suggest 服务:智能提示,降低用户的输入成本。它的特点是:响应快、不承担复杂 query 的检索,可以把它理解为一个简化版的 LBS 领域信息检索服务。
和通用 IR 系统一样,suggest 也分为 doc(LBS 中的 doc 即为 POI) 的召回和排序两个阶段。其中,排序阶段主要使用 query 和 doc 的文本相关性,以及 doc 本身的特征(weight、click),进行加权算分排序。
但随着业务的不断发展、特征规模越来越大,人工调参逐渐困难,基于规则的排序方式已经很难得到满意的效果。这种情况下,为了解决业务问题,将不得不打上各种补丁,导致代码难以维护。
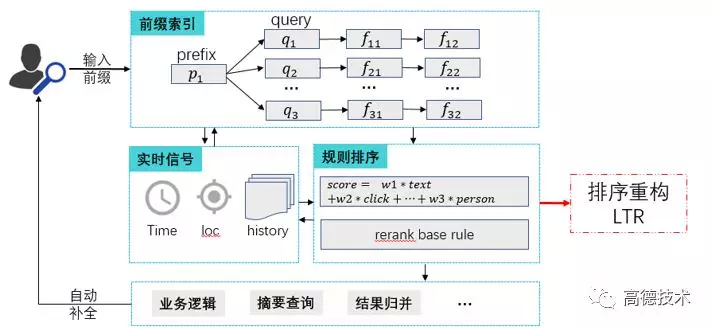
因此,我们决定对排序模块进行重构,Learning to Rank 无疑是一个好的选择。
面临的挑战:样本构造、模型调优
Learning to Rank(LTR)是用机器学习的方法来解决检索系统中的排序问题。业界比较常用的模型是 gbrank,loss 方案用的最多的是 pair wise,这里也保持一致。一般应用 LTR 解决实际问题,最重要的问题之一就是如何获得样本。
首先,高德地图每天的访问量巨大,这背后隐藏的候选 POI 更是一个天文数字,想要使用人工标注的方法去获得样本明显不现实。
其次,如果想要使用一些样本自动构造的方法,比如基于用户对 POI 的点击情况构建样本 pair <click, no-click>,也会遇到如下的问题:
- 容易出现点击过拟合,以前点击什么,以后都给什么结果。
- 有时,用户点击行为也无法衡量真实满意度。
- suggest 前端只展示排序 top10 结果,更多的结果没有机会展现给用户,自然没有点击。
- 部分用户习惯自己输入完整 query 进行搜索,而不使用搜索建议的补全结果,统计不到这部分用户的需求。
对于这几个问题总结起来就是:无点击数据时,建模很迷茫。但就算有某个 POI 的点击,却也无法代表用户实际是满意的。
最后,在模型学习中,也面临了特征稀疏性的挑战。统计学习的目标是全局误差的一个最小化。稀疏特征由于影响的样本较少,在全局上影响不大,常常被模型忽略。但是实际中一些中长尾 case 的解决却往往要依靠这些特征。因此,如何在模型学习过程中进行调优是很重要。
系统建模过程详解
上一节,我们描述了建模的两个难题,一个是样本如何构造,另一个是模型学习如何调优。 先看下怎么解决样本构造难题,我们解决方案是:
- 考量用户在出行场景的行为 session,不光看在 suggest 的某次点击行为,更重要的是,考察用户在出行场景下的行为序列。比如 suggest 给出搜索建议后,继续搜索的是什么词,出行的地点是去哪里,等等。
- 不是统计某个 query 下的点击, 而是把 session 看作一个整体,用户在 session 最后的点击行为,会泛化到 session 中的所有 query 上。
详细方案
第一步,融合服务端多张日志表,包括搜索建议、搜索、导航等。接着,进行 session 的切分和清洗。最后,通过把输入 session 中,末尾 query 的点击计算到 session 中所有 query 上,以此满足实现用户输入 session 最短的优化目标。
如下图所示:
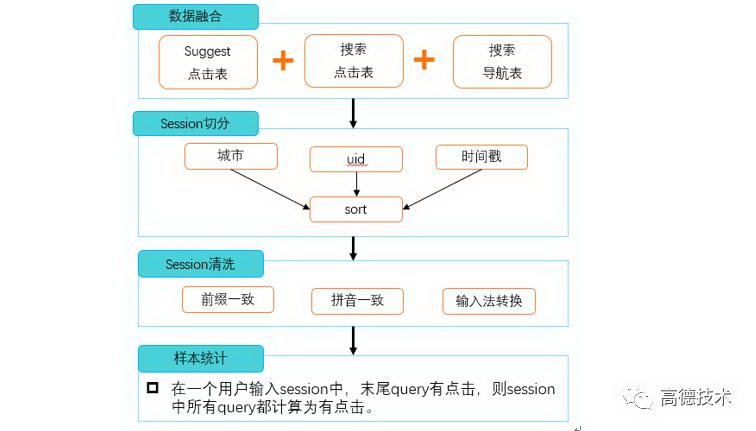
最终,抽取线上点击日志超过百万条的随机 query,每条 query 召回前 N 条候选 POI。利用上述样本构造方案,最终生成千万级别的有效样本作为 gbrank 的训练样本。
特征方面,主要考虑了 4 种建模需求,每种需求都有对应的特征设计方案:
- 有多个召回链路,包括:不同城市、拼音召回。因此,需要一种特征设计,解决不同召回链路间的可比性。
- 随着用户的不断输入,目标 POI 不是静态的,而是动态变化的。需要一种特征能够表示不同 query 下的动态需求。
- 低频长尾 query,无点击等后验特征,需要补充先验特征。
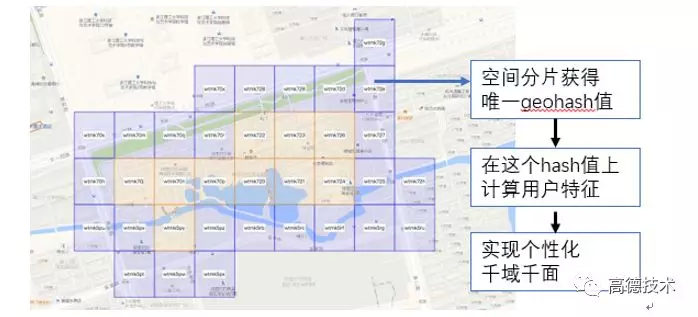
- LBS 服务,有很强的区域个性化需求。不同区域用户的需求有很大不同。为实现区域个性化,做到千域千面,首先利用 geohash 算法对地理空间进行分片,每个分片都得到一串唯一的标识符。从而可以在这个标识符(分片)上分别统计特征。
详细的特征设计,如下表所示:
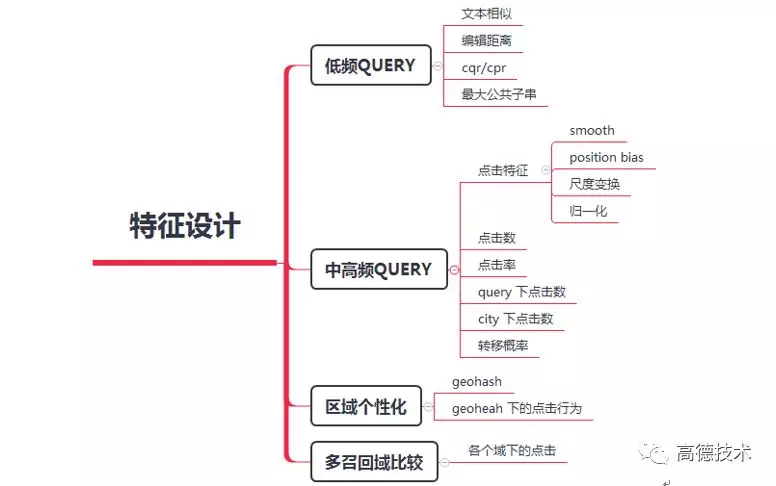
完成特征设计后,为了更好发挥特征的作用,进行必要的特征工程,包括尺度缩放、特征平滑、去 position bias、归一化等。这里不做过多解释。
初版模型,下掉所有规则,在测试集上 MRR 有 5 个点左右的提升,但模型学习也存在一些问题,gbrank 特征学习的非常不均匀。树节点分裂时只选择了少数特征,其他特征没有发挥作用。
以上就是前面提到的,建模的第二个难题:模型学习的调优问题。具体来就是如何解决 gbrank 特征选择不均匀的问题。接下来,我们详细解释下。
先看下,模型的特征重要度。如下图所示:
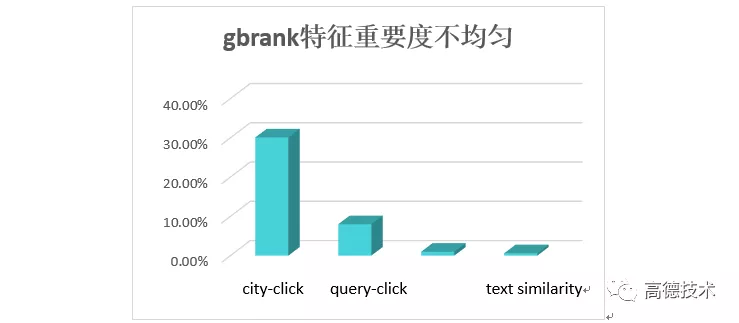
经过分析,造成特征学习不均衡的原因主要有:
- 交叉特征 query-click 的缺失程度较高,60% 的样本该特征值为 0。该特征的树节点分裂收益较小,特征无法被选择。然而,事实上,在点击充分的情况下,query-click 的点击比 city-click 更接近用户的真实意图。
- 对于文本相似特征,虽然不会缺失,但是它的正逆序比较低,因此节点分裂收益也比 city-click 低,同样无法被选择。
综上,由于各种原因,导致树模型学习过程中,特征选择时,不停选择同一个特征(city-click)作为树节点,使得其他特征未起到应有的作用。解决这个问题,方案有两种:
- 方法一:对稀疏特征的样本、低频 query 的样本进行过采样,从而增大分裂收益。优点是实现简单,但缺点也很明显:改变了样本的真实分布,并且过采样对所有特征生效,无法灵活的实现调整目标。我们选择了方法二来解决。
- 方法二: 调 loss function。按两个样本的特征差值,修改负梯度(残差),从而修改该特征的下一轮分裂收益。例如,对于 query-click 特征非缺失的样本,学习错误时会产生 loss,调 loss 就是给这个 loss 增加惩罚项 loss_diff。随着 loss 的增加,下一棵树的分裂收益随之增加,这时 query-click 特征被选作分裂节点的概率就增加了。
具体的计算公式如下式:
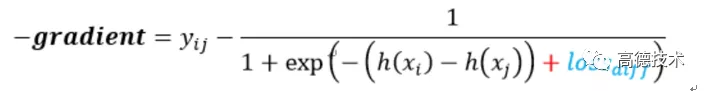
以上公式是交叉熵损失函数的负梯度,loss_diff 相当于对 sigmod 函数的一个平移。

差值越大,loss_diff 越大,惩罚力度越大,相应的下一轮迭代该特征的分裂收益也就越大。
调 loss 后,重新训练模型,测试集 MRR 在初版模型的基础又提升了 2 个点。同时历史排序 case 的解决比例从 40% 提升到 70%,效果明显。
写在最后
Learning to Rank 技术在高德搜索建议应用后,使系统摆脱了策略耦合、依靠补丁的规则排序方式,取得了明显的效果收益。gbrank 模型上线后,效果基本覆盖了各频次 query 的排序需求。
目前,我们已经完成了人群个性化、个体个性化的建模上线,并且正在积极推进深度学习、向量索引、用户行为序列预测在高德搜索建议上的应用。
原文:https://www.infoq.cn/article/QJoNXLo6726oIrUwbRtx
既然来了,说些什么?