人工智能与设计
今年年初出于个人兴趣,我开始了对人工智能的研究。为了更好理解人工智能和设计的关系,我开始学习机器学习、深度学习、Alexa开发等知识,从当初觉得人工智能只会让大部分设计师失业,到现在觉得人工智能只是一个设计的辅助工具,也算是成长了不少。
这次希望能将积累的知识写成一本电子书,没别的,因为字太多,更重要的是这样很酷。由写作时间可能太长,互联网每天都在变化,一些比较前沿的思考可能转眼成为现实,所以先把前四章陆续发出来。
前四章主要讲了现在人工智能的基础知识、底层设计、互联网产品设计以及人工智能与设计的关系,后面会通过3~4章详细分析人工智能对不同行业设计的影响,目前考虑的领域是室内设计、公共设计和服务设计。
人工智能的发展历史
说起人工智能这词,不得不提及人工智能的历史。人工智能的概念主要由Alan Turing提出:机器会思考吗?如果一台机器能够与人类对话而不被辨别出其机器的身份,那么这台机器具有智能的特征。同年,Alan Turing还预言了存有一定的可能性可以创造出具有真正智能的机器。
说明:Alan Turing(1912.6.23-1954.6.7)曾协助英国军队破解了德国的著名密码系统Enigma,帮助盟军取得了二战的胜利。因提出一种用于判定机器是否具有智能的试验方法,即图灵试验,被后人称为计算机之父和人工智能之父。
AI诞生
1956年,在达特茅斯学院举行的一次会议上,不同领域(数学,心理学,工程学,经济学和政治学)的科学家正式确立了人工智能为研究学科。

2006年达特茅斯会议当事人重聚,左起:Trenchard More、John McCarthy、Marvin Minsky、Oliver Selfridge、Ray Solomonoff
第一次发展高潮(1955年—1974年)
达特茅斯会议之后是大发现的时代。对很多人来讲,这一阶段开发出来的程序堪称神奇:计算机可以解决代数应用题、证明几何定理、学习和使用英语。在众多研究当中,搜索式推理、自然语言、微世界在当时最具影响力。
大量成功的AI程序和新的研究方向不断涌现,研究学者认为具有完全智能的机器将在二十年内出现并给出了如下预言:
1958年,H. A. Simon,Allen Newell:“十年之内,数字计算机将成为国际象棋世界冠军。” “十年之内,数字计算机将发现并证明一个重要的数学定理。”
1965年,H. A. Simon:“二十年内,机器将能完成人能做到的一切工作。”
1967年,Marvin Minsky:“一代之内……创造“人工智能”的问题将获得实质上的解决。”
1970年,Marvin Minsky:“在三到八年的时间里我们将得到一台具有人类平均智能的机器。”
美国政府向这一新兴领域投入了大笔资金,每年将数百万美元投入到麻省理工学院、卡耐基梅隆大学、爱丁堡大学和斯坦福大学四个研究机构,并允许研究学者去做任何感兴趣的方向。
当时主要成就:
- 人工神经网络在30-50年代被提出,1951年Marvin Minsky制造出第一台神经网络机
- 贝尔曼公式(增强学习雏形)被提出
- 感知器(深度学习雏形)被提出
- 搜索式推理被提出
- 自然语言被提出
- 首次提出人工智能拥有模仿智能的特征,懂得使用语言,懂得形成抽象概念并解决人类现存问题
- Arthur Samuel在五十年代中期和六十年代初开发的国际象棋程序,棋力已经可以挑战具有相当水平的业余爱好者
- 机器人SHAKEY项目受到了大力宣传,它能够对自己的行为进行“推理”;人们将其视作世界上第一台通用机器人
- 微世界的提出
第一次寒冬(1974年—1980年)
70年代初,AI遭遇到瓶颈。研究学者逐渐发现,虽然机器拥有了简单的逻辑推理能力,但遭遇到当时无法克服的基础性障碍,AI停留在“玩具”阶段止步不前,远远达不到曾经预言的完全智能。由于此前的过于乐观使人们期待过高,当AI研究人员的承诺无法兑现时,公众开始激烈批评AI研究人员,许多机构不断减少对人工智能研究的资助,直至停止拨款。
当时主要问题:
- 计算机运算能力遭遇瓶颈,无法解决指数型爆炸的复杂计算问题
- 常识和推理需要大量对世界的认识信息,计算机达不到“看懂”和“听懂”的地步
- 无法解决莫拉维克悖论
- 无法解决部分涉及自动规划的逻辑问题
- 神经网络研究学者遭遇冷落
说明:莫拉维克悖论:如果机器像数学天才一样下象棋,那么它能模仿婴儿学习又有多难呢?然而,事实证明这是相当难的。
第二次发展高潮(1980年—1987年)
80年代初,一类名为“专家系统”的AI程序开始为全世界的公司所采纳,人工智能研究迎来了新一轮高潮。在这期间,卡耐基梅隆大学为DEC公司设计的XCON专家系统能够每年为DEC公司节省数千万美金。日本经济产业省拨款八亿五千万美元支持第五代计算机项目。其目标是造出能够与人对话、翻译语言、解释图像、能够像人一样推理的机器。其他国家也纷纷作出了响应,并对AI和信息技术的大规模项目提供了巨额资助。
说明:专家系统是一种程序,能够依据一组从专门知识中推演出的逻辑规则在某一特定领域回答或解决问题。由于专家系统仅限于一个很小的领域,从而避免了常识问题。“知识处理”随之也成为了主流 AI 研究的焦点。
当时主要成就:
- 专家系统的诞生
- AI研究人员发现智能可能需要建立在对分门别类的大量知识的多种处理方法之上
- BP算法实现了神经网络训练的突破,神经网络研究学者重新受到关注
- AI研究人员首次提出:机器为了获得真正的智能,机器必须具有躯体,它需要有感知、移动、生存,与这个世界交互的能力。感知运动技能对于常识推理等高层次技能是至关重要的,基于对事物的推理能力比抽象能力更为重要,这也促进了未来自然语言、机器视觉的发展。
第二次寒冬(1987年—1993年)
1987年,AI硬件的市场需求突然下跌。科学家发现,专家系统虽然很有用,但它的应用领域过于狭窄,而且更新迭代和维护成本非常高。同期美国Apple和IBM生产的台式机性能不断提升,个人电脑的理念不断蔓延;日本人设定的“第五代工程”最终也没能实现。人工智能研究再次遭遇了财政困难,一夜之间这个价值五亿美元的产业土崩瓦解。
当时主要问题:
- 受到台式机和“个人电脑”理念的冲击影响
- 商业机构对AI的追捧和冷落,使AI化为泡沫并破裂
- 计算机性能瓶颈仍无法突破
- 仍然缺乏海量数据训练机器
第三次发展高潮(1993年至今)
在摩尔定律下,计算机性能不断突破。云计算、大数据、机器学习、自然语言和机器视觉等领域发展迅速,人工智能迎来第三次高潮。
摩尔定律起始于Gordon Moore在1965年的一个预言,当时他看到因特尔公司做的几款芯片,觉得18到24个月可以把晶体管体积缩小一半,个数可以翻一番,运算处理能力能翻一倍。没想到这么一个简单的预言成真了,下面几十年一直按这个节奏往前走,成为了摩尔定律。
主要事件:
- 1997年:IBM的国际象棋机器人深蓝战胜国际象棋世界冠军卡斯帕罗夫
- 2005年:Stanford开发的一台机器人在一条沙漠小径上成功地自动行驶了131英里,赢得了DARPA挑战大赛头奖;
- 2006年:Geoffrey Hinton提出多层神经网络的深度学习算法;Eric Schmidt在搜索引擎大会提出“云计算”概念
- 2010年:Sebastian Thrun领导的谷歌无人驾驶汽车曝光,创下了超过16万千米无事故的纪录
- 2011年:IBM Waston参加智力游戏《危险边缘》,击败最高奖金得主Brad Rutter和连胜纪录保持者Ken Jennings;苹果发布语音个人助手Siri;Nest Lab发布第一代智能恒温器Nest。它可以了解用户的习惯,并相应自动地调节温度
- 2012年:Google发布个人助理Google Now
- 2013年:深度学习算法在语音和视觉识别率获得突破性进展
- 2014年:微软亚洲研究院发布人工智能小冰聊天机器人和语音助手Cortana;百度发布Deep Speech语音识别系统
- 2015年:Facebook发布了一款基于文本的人工智能助理“M”
- 2016年:Google AlphaGo以比分4:1战胜围棋九段棋手李世石;Chatbots这个概念开始流行;Google发布为机器学习定制的第一代专用芯片TPU;Google发布语音助手Assistant
- 2017年:AlphaGO在围棋网络对战平台以60连胜击败世界各地高手;Google 开源深度学习系统Tensorflow 1.0正式发布;Google AlphaGo以比分3:0完胜世界第一围棋九段棋手柯洁;默默深耕机器学习和机器视觉的苹果在WWDC上发布Core ML,ARKit等组件;Google发布了ARCore SDK;百度AI开发者大会正式发布Dueros语音系统,无人驾驶平台Apollo1.0自动驾驶平台;华为发布全球第一款AI移动芯片麒麟970;iPhone X配备前置 3D 感应摄像头(TrueDepth),脸部识别点达到3W个,具备人脸识别、解锁和支付等功能;配备的A11 Bionic神经引擎使用双核设计,每秒可达到运算6000亿次
很多专家学者对此次人工智能浪潮给予了肯定,认为这次人工智能浪潮能引起第四次工业革命。人工智能逐渐开始在保险,金融等领域开始渗透,在未来健康医疗、交通出行、销售消费、金融服务、媒介娱乐、生产制造,到能源、石油、农业、政府……所有垂直产业都将因人工智能技术的发展而受益,那么我们现在讲的人工智能究竟是什么?
人工智能是什么?
在60年代,AI研究人员认为人工智能是一台通用机器人,它拥有模仿智能的特征,懂得使用语言,懂得形成抽象概念,能够对自己的行为进行推理,它可以解决人类现存问题。由于理念、技术和数据的限制,人工智能在模式识别、信息表示、问题解决和自然语言处理等不同领域发展缓慢。
80年代,AI研究人员转移方向,认为人工智能对事物的推理能力比抽象能力更重要,机器为了获得真正的智能,机器必须具有躯体,它需要感知、移动、生存,与这个世界交互。为了积累更多推理能力,AI研究人员开发出专家系统,它能够依据一组从专门知识中推演出的逻辑规则在某一特定领域回答或解决问题。
1997年,IBM的超级计算机深蓝在国际象棋领域完胜整个人类代表卡斯帕罗夫;相隔20年,Google的AlphaGo在围棋领域完胜整个人类代表柯洁。划时代的事件使大部分AI研究人员确信人工智能的时代已经降临。
可能大家觉得国际象棋和围棋好像没什么区别,其实两者的难度不在同一个级别。国际象棋走法的可能性虽多,但棋盘的大小和每颗棋子的规则大大限制了赢的可能性。深蓝可以通过蛮力看到所有的可能性,而且只需要一台计算机基本上就可以搞定。相比国际象棋,围棋很不一样。围棋布局走法的可能性可能要比宇宙中的原子数量还多,几十台计算机的计算能力都搞不定,所以机器下围棋想赢非常困难,包括围棋专家和人工智能领域的专家们也纷纷断言:计算机要在围棋领域战胜人类棋手,还要再等100年。结果机器真的做到了,并据说AlphaGo拥有围棋十几段的实力(目前围棋棋手最高是9段)。
那么深蓝和AlphaGo在本质上有什么区别?简单点说,深蓝的代码是研究人员编程的,知识和经验也是研究人员传授的,所以可以认为与卡斯帕罗夫对战的深蓝的背后还是人类,只不过它的运算能力比人类更强,更少失误。而AlphaGo的代码是自我更新的,知识和经验是自我训练出来的。与深蓝不一样的是,AlphaGo拥有两颗大脑,一颗负责预测落子的最佳概率,一颗做整体的局面判断,通过两颗大脑的协同工作,它能够判断出未来几十步的胜率大小。所以与柯洁对战的AlphaGo的背后是通过十几万盘的海量训练后,拥有自主学习能力的人工智能系统。
这时候社会上出现了不同的声音:“人工智能会思考并解决所有问题”、“人工智能会抢走人类的大部分工作!”“人工智能会取代人类吗?”那么已来临的人工智能究竟是什么?
人工智能目前有两个定义,分别为强人工智能和弱人工智能。
普通群众所遐想的人工智能属于强人工智能,它属于通用型机器人,也就是60年代AI研究人员提出的理念。它能够和人类一样对世界进行感知和交互,通过自我学习的方式对所有领域进行记忆、推理和解决问题。这样的强人工智能需要具备以下能力:
- 存在不确定因素时进行推理,使用策略,解决问题,制定决策的能力
- 知识表示的能力,包括常识性知识的表示能力
- 规划能力
- 学习能力
- 使用自然语言进行交流沟通的能力
- 将上述能力整合起来实现既定目标的能力
说明:以上结论借鉴李开复所著的《人工智能》一书。
这些能力在常人看来都很简单,因为自己都具备着;但由于技术的限制,计算机很难具备以上能力,这也是为什么现阶段人工智能很难达到常人思考的水平。
由于技术未成熟,现阶段的人工智能属于弱人工智能,还达不到大众所遐想的强人工智能。弱人工智能也称限制领域人工智能或应用型人工智能,指的是专注于且只能解决特定领域问题的人工智能,例如AlphaGo,它自身的数学模型只能解决围棋领域的问题,可以说它是一个非常狭小领域问题的专家系统,以及它很难扩展到稍微宽广一些的知识领域,例如如何通过一盘棋表达出自己的性格和灵魂。
弱人工智能和强人工智能在能力上存在着巨大鸿沟,弱人工智能想要进一步发展,必须具备以下能力:
- 跨领域推理
- 拥有抽象能力
- “知其然,也知其所以然”
- 拥有常识
- 拥有审美能力
- 拥有自我意识和情感
说明:以上结论借鉴李开复所著的《人工智能》一书。
在计算机理念来说,人工智能是用来处理不确定性以及管理决策中的不确定性。意思是通过一些不确定的数据输入来进行一些具有不确定性的决策。从目前的技术实现来说,人工智能就是深度学习,它是06年由Geoffrey Hinton所提出的机器学习算法,该算法可以使程序拥有自我学习和演变的能力。
机器学习和深度学习是什么?
机器学习简单点说就是通过一个数学模型将大量数据中有用的数据和关系挖掘出来。机器学习建模采用了以下四种方法:
- 监督学习与数学中的函数有关。它需要研究学者不断地标注数据从而提高模型的准确性,挖掘出数据间的关系并给出结果。
- 非监督学习与现实中的描述(例如哪些动物有四条腿)有关。它可以在没有额外信息的情况下,从原始数据中提取模式和结构的任务,它与需要标签的监督学习相互对立。
- 半监督学习,它可以理解为监督学习和半监督学习的结合。
- 增强学习,它的大概意思是通过联想并对比未来几步所带来的好处而决定下一步是什么。
目前机器学习以监督学习为主。
深度学习属于机器学习下面的一条分支。它能够通过多层神经网络以及使用以上四种方法,不断对自身模型进行自我优化,从而发现出更多优质的数据以及联系。
目前的AlphaGo正是采用了深度学习算法击败了人类世界冠军,更重要的是,深度学习促进了人工智能其他领域如自然语言和机器视觉的发展。目前的人工智能的发展依赖深度学习,这句话没有任何问题。
人工智能基础能力
在了解人工智能基础能力前,我们先聊聊更底层的东西——数据。计算机数据分为两种,结构化数据和非结构化数据。结构化数据是指具有预定义的数据模型的数据,它的本质是将所有数据标签化、结构化,后续只要确定标签,数据就能读取出来,这种方式容易被计算机理解。非结构化数据是指数据结构不规则或者不完整,没有预定义的数据模型的数据。非结构化数据格式多样化,包括了图片、音频、视频、文本、网页等等,它比结构化信息更难标准化和理解。
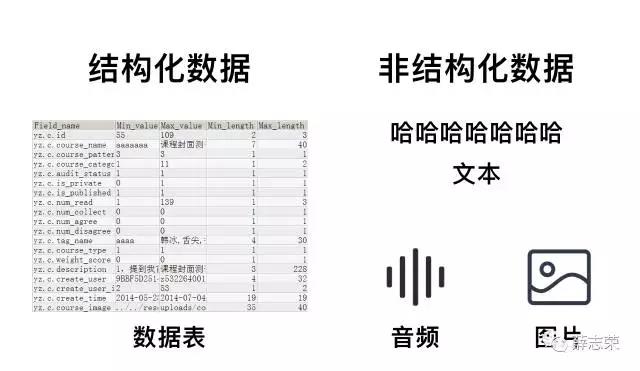
音频、图片、文本、视频这四种载体可以承载着来自世界万物的信息,人类在理解这些内容时毫不费劲;对于只懂结构化数据的计算机来说,理解这些非结构化内容比登天还难,这也就是为什么人与计算机交流时非常费劲。
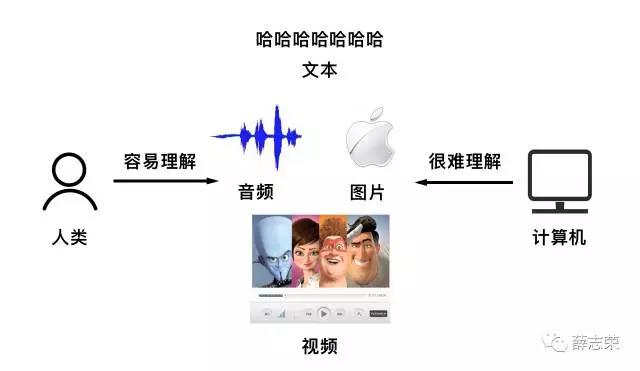
全世界有80%的数据都是非结构化数据,人工智能想要达到看懂、听懂的状态,必须要把非结构化数据这块硬骨头啃下来。学者在深度学习的帮助下在这领域取得了突破性成就,这成就为人工智能其他各种能力奠定了基础。
如果将人工智能比作一个人,那么人工智能应该具有记忆思考能力,输入能力如视觉、听觉、嗅觉、味觉以及触觉,以及输出能力如语言交流、躯体活动。以上能力对相应的术语为:深度学习、知识图谱、迁移学习、自然语言处理、机器视觉、语音识别、语音合成(触觉、嗅觉、味觉在技术研究上暂无商业成果,躯体活动更多属于机器人领域,不在文章中过多介绍)
简单点说,知识图谱就是一张地图。它从不同来源收集信息并加以整理,每个信息都是一个节点,当信息之间有关系时,相关节点会建立起联系,众多信息节点逐渐形成了图。知识图谱有助于信息存储,更重要的是提高了搜索信息的速度和质量。
迁移学习把已学训练好的模型参数迁移到新的模型来帮助新模型训练数据集。由于大部分领域都没有足够的数据量进行模型训练,迁移学习可以将大数据的模型迁移到小数据上,实现个性化迁移,如同人类思考时使用的类比推理。迁移学习有助于人工智能掌握更多知识。
自然语言处理是一门融语言学、计算机科学、数学于一体的学科,它是人工智能的耳朵-语音识别和嘴巴-语音合成的基础。计算机能否理解人类的思想,首先要理解自然语言,其次拥有广泛的知识,以及运用这些知识的能力。自然语言处理的主要范畴非常广,包括了语音合成、语音识别、语句分词、词性标注、语法分析、语句分析、机器翻译、自动摘要等等、问答系统等等。
机器视觉通过摄影机和计算机代替人的眼睛对目标进行识别、跟踪和测量,并进一步对图像进行处理。这是一门研究如何使机器“看懂”的技术,是人工智能最重要的输入方式之一。如何通过摄像头就能做到实时、准确识别外界状况,这是人工智能的瓶颈之一,深度学习在这方面帮了大忙。现在热门的人脸识别、无人驾驶等技术都依赖于机器视觉技术。
语音识别的目的是将人类的语音内容转换为相应的文字。机器能否与人类自然交流的前提是机器能听懂人类讲什么,语音识别也是人工智能的最重要输入方式之一。由于不同地区有着不同方言和口音,这对于语音识别来说都是巨大的挑战。目前百度、科大讯飞等公司的语音识别技术在普通话上的准确率已达到97%,但方言准确率还有待提高。
目前大部分的语音合成技术是利用在数据库内的许多已录好的语音连接起来,但由于缺乏对上下文的理解以及情感的表达,朗读效果很差。现在百度和科大讯飞等公司在语音合成上有新的成果:16年3月百度语音合成了张国荣声音与粉丝互动;17年3月本邦科技利用科大讯飞的语音合成技术,成功帮助小米手机实现了一款内含“黑科技”的营销活动H5。它们的主要技术是通过对张国荣、马东的语音资料进行语音识别,提取该人的声纹和说话特征,再通过自然语言处理对讲述的内容进行情绪识别,合成出来的语音就像本人在和你对话。新的语音合成技术不再被数据库内的录音所限制语言和情感的表达。
经过多年的人工智能研究,人工智能的主要发展方向分为:计算智能、感知智能、认知智能,这一观点也得到业界的广泛认可。
计算智能是以生物进化的观点认识和模拟智能。有学者认为,智能是在生物的遗传、变异、生长以及外部环境的自然选择中产生的。在用进废退、优胜劣汰的过程中,适应度高的(头脑)结构被保存下来,智能水平也随之提高。机器借助大自然规律的启示设计出具有结构演化能力和自适应学习能力的智能。计算智能算法主要包括神经计算、模糊计算和进化计算三大部分,神经网络和遗传算法的出现,使得机器的运算能力大幅度提升,能够更高效、快速处理海量的数据。计算智能是人工智能的基础,AlphaGo是计算智能的代表。
感知智能是以视觉、听觉、触觉等感知能力辅助机器,让机器能听懂我们的语言、看懂世界万物。相比起人类的感知能力,机器可以通过传感器获取更多信息,例如温度传感器、湿度传感器、红外雷达、激光雷达等等。感知智能也是人工智能的基础,机器人、自动驾驶汽车是感知智能的代表。
认知智能是指机器具有主动思考和理解的能力,不用人类事先编程就可以实现自我学习,有目的推理并与人类自然交互。人类有语言,才有概念、推理,所以概念、意识、观念等都是人类认知智能的表现,机器实现以上能力还有漫长的路需要探索。
在认知智能的帮助下,人工智能通过发现世界和历史上海量的有用信息,并洞察信息间的关系,不断优化自己的决策能力,从而拥有专家级别的实力,辅助人类做出决策。认知智能将加强人和人工智能之间的互动,这种互动是以每个人的偏好为基础的。认知智能通过搜集到的数据,例如地理位置、浏览历史、可穿戴设备数据和医疗记录等等,为不同个体创造不同的场景。认知系统也会根据当前场景以及人和机器的关系,采取不同的语气和情感进行交流。
假如能像设想的一样实现认知智能,那么底层平台必须足够宽广和灵活,以便在各领域甚至跨领域得到应用。因此研发人员需要从全局性出发,打造这个健壮的底层平台,它应该包括机器学习、自然语言处理、语音和图像识别、人机交互等技术,便于上层应用开发者的开发和使用。
下一篇文章会从设计底层平台的角度来阐述个人的思考。
阅读资料:
1、人工智能史
- https://zh.wikipedia.org/wiki/人工智能史
- Alan Turing
- https://zh.wikipedia.org/wiki/艾伦·图灵
- 科普AI之60年前的达特茅斯会议与AI缘起
- https://tech.163.com/16/0313/12/BI1P1CLI00094P0U.html
2、人工神经网络
https://baike.baidu.com/item/人工神经网络
3、深度学习
https://baike.baidu.com/item/深度学习
4、自然语言
https://baike.baidu.com/item/自然语言
5、TensorFlow
https://baike.baidu.com/link?url=dO_lFqvg6FQLYVaQKcwnlol1noc-EgdfIGbG6pQUo481iBQQkXSC8ZtFdAZ7II2SXyvG-mrTu34UuRFGdb0xvu2gmiZL02Sm6X4zOKiJrJ_
6、知识图谱
https://www.jiqizhixin.com/articles/2017-03-20
7、《人工智能》-李开复、王咏刚著
https://item.jd.com/12169266.html
8、小米《奇葩说》花式广告大赛
http://w.benbun.com/xiaomi/koubo/?state=d81c977eeb74e8d8783dc94e39fe1972&code=1abbb176039771a76583804409fb3354
以上就是第一章的内容。
“去中心化”的互联网
互联网的前身叫做阿帕网,属于美国国防部60年代部署的一个中央控制型网络。阿帕网有一个明显的弱点:如果中央控制系统受到攻击,整个阿帕网就会瘫痪。为了解决这个问题,美国的Paul Baran开发了一套新型通信系统。该系统的主要特色是:如果部分系统被摧毁,整个通信系统仍能够保持运行。它的工作原理是这样的:中央控制系统不再简单地把数据直接传送到目的地,而是在网络的不同节点之间传送;如果其中某个节点损坏,则别的节点能够马上代替进来。阿帕网的相关实践和研究,催生出现代意义上的互联网。
互联网的起源就是为了去中心化,可以使信息更安全、更高效地传播。可惜在第一次互联网泡沫之后,人们开始意识到在互联网上创造价值的捷径是搭建中心化服务,收集信息并将之货币化。互联网上逐渐出现了不同领域的巨头,它们以中心化的形式影响着亿万用户,例如社交网络Facebook,搜索引擎Google等等。用户使用他们的产品进行社交或者搜索,而作为服务提供商的巨头们通过掌握和分析用户数据进而优化自己的产品并获得利益。为了给用户提供更好的服务,存储和分析用户数据本来无可厚非,但这也引起了一部分对自己的隐私安全敏感的用户的不满。但更重要的一点是,如果某个巨头突然垮了停止了相关服务,会给人类的生活带来极大的困扰。
貌似互联网又回到了60年代。很多老一辈互联网参与者重新开始讨论去中心化的互联网,他们认为互联网去中心化的核心概念是:服务的运行不再盲目依赖于单一的垄断企业,而是将服务运营的责任分散承担。
Tim Berners-Lee(万维网的发明者)提出了自己的见解:“将网络设计成去中心化的,每个人都可以参与进来,拥有自己的域名和网络服务器,只是目前还没有实现。目前的个人数据被垄断了。我们的想法是恢复去中心化网络的创意”。
我们再看看去中心化网络的三个核心优势:隐私性、数据可迁移性和安全性。
- 隐私性:去中心化对数据隐私性要求很高。数据分布在网络中,端到端加密技术可以保证授权用户的读写权限。数据获取权限用算法控制,而中心化网络则一般由网络所有者控制,包括消费者描述和广告定位。
- 数据可迁移性:在去中心化环境下,用户拥有个人数据,可以选择共享对象。而且不受服务供应商的限制(如果还存在服务供应商的概念)。这点很重要。如果你想换车,为什么不可以迁移自己的个人驾驶记录呢?聊天平台记录和医疗记录同此理。
- 安全性:最后我们的世界面临着越来越大的安全威胁。在中心化环境下,越孤立的优良环境越是吸引破坏者。去中心化环境的本质决定了其安全性,可以抵御黑客攻击、渗透、信息盗窃、系统奔溃等漏洞,因为从一开始它的设计就保证了公众的监督。
近几年很火的HBO《硅谷》以“互联网去中心化”这个理念开始了最新一季。怪人风投家 Russ Hanneman 询问陷入困境的 Pied Piper 创始人 Richard Hendricks,如果给予他无限的时间和资源,他想要构建什么? Hendricks 回答“一个全新的互联网”,他随后解释说,现在每台手机的运算能力都比人类登月时的手机要强大得多,如果你能用所有的几十亿台手机构建一个巨大的网络,使用压缩算法将一切变得更小更高效, 更方便的转移数据,那么我们将能构建一个完全去中心化的互联网,没有防火墙,没有过路费,没有政府监管,没有监视,信息将会完全的自由。
详细可以看以下视频:
在后面剧情中,Pied Piper在Hooli大会上将Dan Melcher的几千TB数据转移到25万手机上。虽然期间发生了一系列问题,但最后Dan Melcher的数据“神奇”地备份到3万台智能冰箱的巨型网络上。
互联网档案馆的创始人Brewster Kahle曾表示,互联网去中心化在实际中很难被执行,仍有很漫长的路要走。虽然《硅谷》只是一部电视剧,里面有部分技术纯属虚构,但是它也侧面证实了一个事实,每一台手机的运算能力和性能除了打打电话,聊聊天,玩玩游戏外,还能做到很多事情,例如成为新一代微型服务器和计算中心。
最合适的私人服务器
手机成为新一代微型服务器,这也符合Tim Berners-Lee“每个人都拥有自己的网络服务器”的观点。目前手机的性能和容量已经可以媲美一台台式计算机,更重要的是,为了减少对CPU的压力,手机拥有不同的协处理器。各协处理器各司其职,专门为手机提供不同的特色功能,例如iPhone从5s开始集成了运动协处理器,它能低功耗监测并记录用户的运动数据;MotoX搭载的协处理器可以识别你的语音/处理运动信息,从而在未唤醒状态下使用Google now功能。
手机上各种传感器可以从不同维度监测用户数据,如果手机成为下一代微型服务器,那么它需要承担着存储用户数据的责任。同时人工智能助手需要每个用户海量的数据作为基础才能更好地理解用户并实时提供帮助,成为“千人千面”的个人助理,所以手机存储和分析用户数据是人工智能助手的基础。
分析用户的非结构化数据需要大量的计算,为了降低对CPU和电池的压力,手机需要一块低功耗专门分析用户数据的协处理器。它能够低功耗地进行深度学习、迁移学习等机器学习方法,对用户的海量非结构化数据进行分析、建模和处理。
家庭也需要一个更大容量的服务器来减少手机容量的压力,例如24小时长期工作的冰箱、路由器或者智能音箱是一个很好地承载数据的容器。用户手机可以定期将时间较长远的数据备份到家里服务器,这样的方式有以下好处:
- 降低了手机里用户数据的使用空间
- 家庭服务器可以24小时稳定工作,可以承担更多更复杂的计算,并将结果反馈给移动端
- 用户手机等设备更换时,可以无缝使用现有功能
Google在2015年已经开始使用自家研发的TPU,它在深度学习的运算速度上比当前的CPU和GPU快15~30倍,性能功耗比高出约30~80倍。当手机、智能音箱等设备拥有与TPU类似的协处理器时,个人人工智能助理会到达新的顶峰。在17年9月份,华为发布了全球第一款AI移动芯片麒麟970,其AI性能密度大幅优于CPU和GPU。在处理同样的AI应用任务时,相较于四个Cortex-A73核心,麒麟970的新异构计算架构拥有大约50倍能效和25倍性能优势,这意味未来在手机上处理AI任务不再是难事。更厉害的是,iPhone X的A11仿生芯片拥有神经引擎,每秒运算次数最高可达 6000 亿次。它是专为机器学习而开发的硬件,它不仅能执行神经网络所需的高速运算,而且具有杰出的能效。
数据的进一步利用
人工智能的发展依赖于大数据、高性能的运算能力和实现框架,数据是人工智能的基础。在过去30年里,人类数据经历了两个阶段,孤岛阶段和集体阶段。
孤岛阶段
在没有互联网以及互联网前期,人类使用计算机基本处于单机状态,数据也只能存储在计算机本地。由于计算机性能较差,产品较为简单以及技术的不成熟,人类在计算机上产生的数据价值不大。
集体阶段
在互联网中后期和移动互联网时代,计算机行业开始往互联网发展并衍生出更多领域,例如网上社交、搜索等等,视频音乐等娱乐行业也开始互联网化;到了移动互联网时代,巨头们结合传统行业产生出更多的玩法。人类每天的活动逐渐创造出庞大的数据。
由于数据的庞大以及技术有限,个人没有能力对自己的数据进行存储和分析,个人数据对个人来讲仍然价值不大,但对于巨头来说就不一样了。巨头们有的是资金和技术,即使个人数据拥有太多特征,但放在一起成为群体数据时,巨头们可以通过数据清洗,建模等方法分析出相关群体的普遍特征,得出相关的用户画像,更了解自己的用户是谁,从而设计出更有针对性的功能和服务,探索出新的用户需求和衍生出新的产品。
随着近几年技术的成熟,巨头们可以做到一些相对简单的个人推荐。如亚马逊,它可以根据你的购买记录推荐相关商品给你,其背后的原理是通过分析大量的用户购买数据后得到的商品推荐。
由于服务器的普遍昂贵以及普通用户缺乏对数据处理的能力,而巨头们有能力使用户数据发挥更大价值,所以用户数据一直“默许”被Google、Facebook、苹果、腾讯、阿里、百度等巨头收集着,这是可以理解的。每个用户一天产生的数据涵括了社交、健康、购物、地理信息等等,但是巨头们的垄断和相互竞争,导致用户数据被各巨头分割和收集使用,再加上巨头们宁愿生产更多的产品进行竞争也不愿意使用户数据互通,导致用户数据发挥不出更大的价值。这也是人工智能发展道路上的一道很现实赤裸裸的门槛。
互通阶段
若要使人工智能得到更快发展,需要分析和了解更多完整数据;加上互联网去中心化的理念,应用厂商把数据“还给”用户将会是下一个趋势。把数据“还给”用户的意思不是指应用厂商不应该拥有该数据,而是指将数据共享出去,从而获得更多有用的数据。
为了人工智能的发展让各个应用厂商之间共享数据是不符合竞争和现实的,但用户有权把自己的数据给“拿”回来,因为这些本来就是用户自己的。这时候用户需要一个数据仓库,它能存储和整理不同应用厂商的数据,而人工智能可以利用数据进行自我优化和分析出该名用户的特征。
例如我们手机里的淘宝和京东,用户使用它们时的动机和场景不一样,所以它们所得的用户画像仅是该名用户的一部分,不能完全代表该名用户。如果淘宝和京东将各自的数据保存到个人数据仓库,人工智能将数据整理完后为淘宝和京东输出已授权的完整用户画像,那么淘宝和京东可以为该名用户提供更多的个性化服务,创造更多收益。这就是应用厂商为人工智能提供数据,人工智能反哺各应用厂商。
下一代人工智能助理
为了更了解你,人工智能需要了解更多数据。在日常生活中,一名用户的主要信息归纳为:身份信息、健康数据、兴趣爱好、工作信息、财产数据、信用度、消费信息、社交圈子、活动范围9个大类。
- 身份信息:名字、性别、年龄、家乡、身份证(身份证包含前4项)、账号、现居住地址和家庭信息
- 健康数据:基础身体情况、医疗记录和运动数据
- 兴趣爱好:饮食、娱乐、运动等方面
- 工作信息:公司、职位、薪酬和同事通讯录
- 财产数据:薪酬、存款、股票、汽车、不动产和贵重物品
- 信用度:由信用机构提供的征信记录
- 消费信息:消费记录(含商品类型、购买时间、购买价格和收货地址)、消费水平和浏览记录
- 社交圈子:通讯录(含好友、同事、同学和亲戚)和社交动态(含线下和线上)
- 活动范围:出行记录、主要活动范围和旅游
以上方面都有相关产品提供服务和数据记录,例如社交应用微信和陌陌、购物应用京东和淘宝、运动健康Keep等等。如果各方面数据打通并提供给人工智能,人工智能拥有用户更多的数据和特征,更多应用和智能硬件可以通过连接人工智能了解用户信息,从而进行自我学习和优化。总体来说,人工智能能代表你,它也是最懂你的个人助理。
人工智能数据仓库设计
2015年堪称智能家居元年,但最后大众还是被忽悠了。通俗理解的话,智能家居的重点是智能,而人工智能没有发展起来,智能家居如何智能?
现在大部分智能电器就像一个孤岛,只能通过手机里的不同APP操控,相互之间没有任何联动,根本体现不出智能家居的概念,直至小米打破了现有状况。
小米通过MIUI、路由器和小米生态链布局智能家居生态,前期通过路由器掌控联网大权,小米电视占据家庭娱乐中心、Wifi插座使基础家电智能化、各种传感器使建筑智能化;中期通过与科技企业如美的的合作,以及小米生态链的各种产品如扫地机器人、空气净化器、电饭煲等,由小米控制的智能家居不断渗透到用户家里;近期推出299元的小米AI音箱使小米智能家居达到一个新的高潮,控制智能家居变得更为简单,用户可以通过AI音箱对各产品下达指令和操控。至今为止,在国内智能家居布局最出色的是小米。
目前小米的智能家居布局仍处于初期阶段,只是把不同电器互联化并连接一个终端。家居的智能不只是简简单单地通过命令操作就行,更多在于智能家居之间的联动以及更懂主人,这靠的是对用户数据的积累、理解和分享;但也带来隐私问题,用户会担心更多产品和人工智能接触到更多数据时,自己的生活被24小时监控着。人工智能将会是科学与伦理博弈中最激烈的一环,所以如何实现底层的数据仓库是关键。
未来的人工智能和数据仓库应该是一个平台,就像现在的操作系统Windows,iOS和Android,但数据仓库不应该被巨头们和政府掌控,因为它比现在的操作系统存储更多用户的隐私数据,所以数据仓库需要定制更多的隐私规则防止用户数据泄露,以及定制开放协议实现多元创新,避免被巨头垄断。
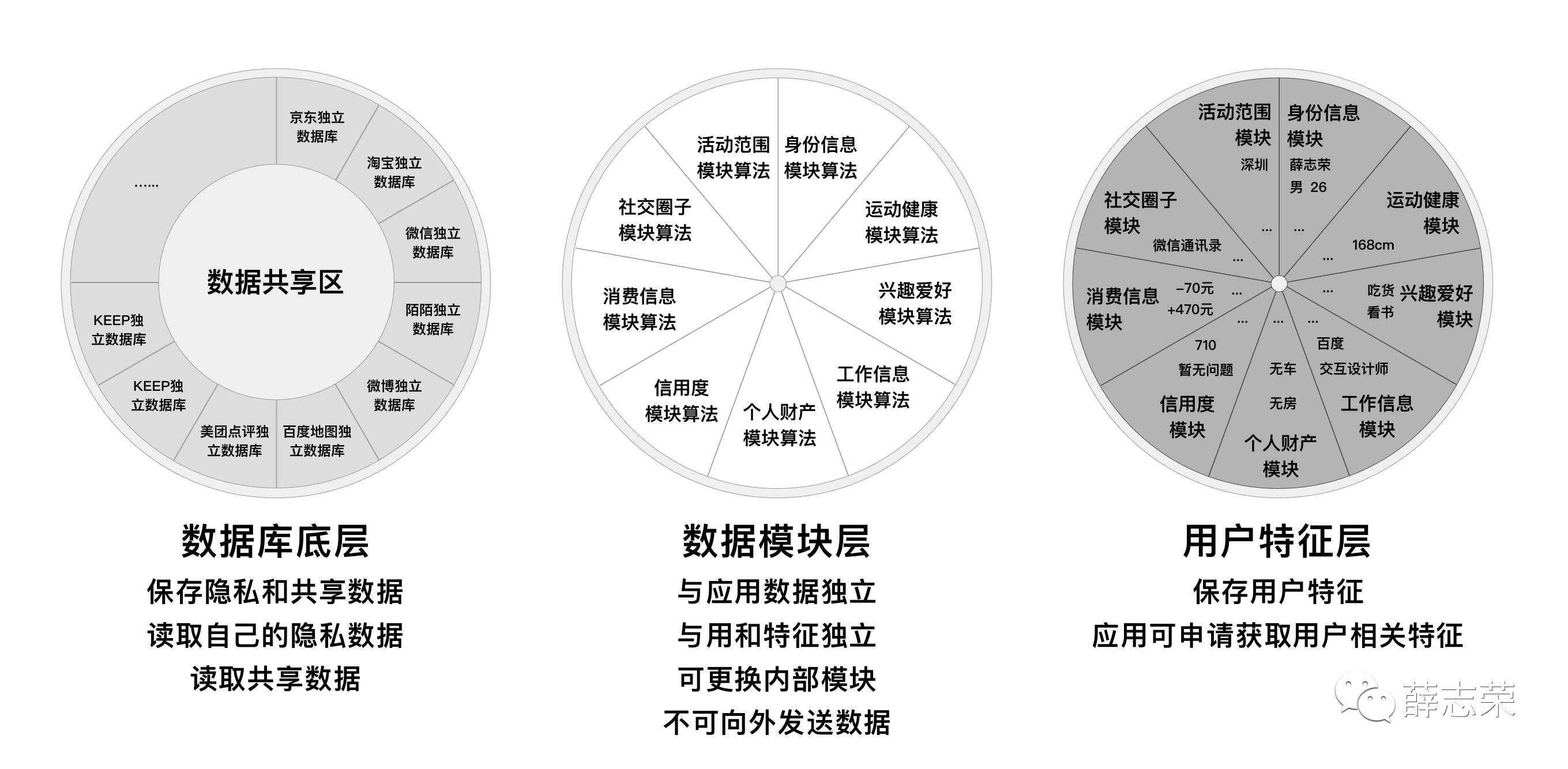
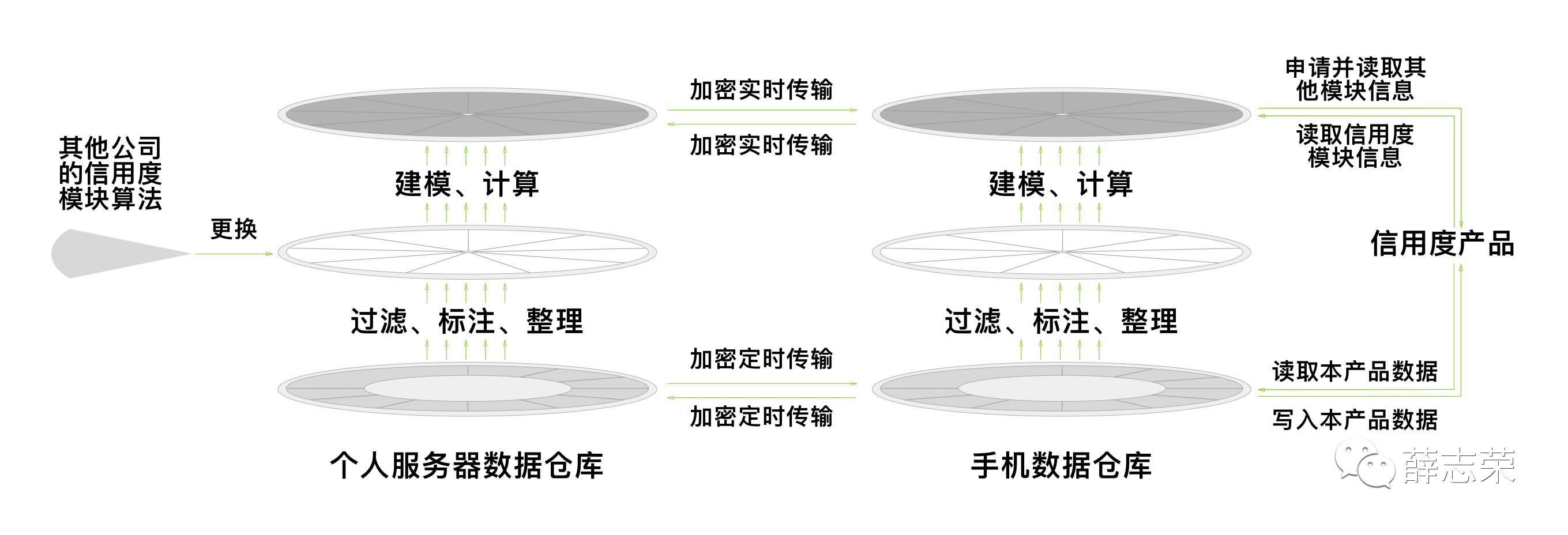
该仓库具有以下特性和功能:
- 数据仓库拥有该名用户的完整特征和数据,它可以代表该用户。
- 数据仓库最少包含身份信息、健康数据、兴趣爱好、工作信息、财产数据、信用度、消费信息、社交圈子、活动范围9个模块。每个模块相互独立,不耦合。
- 数据仓库包括用户特征、产品私有数据和共享数据。用户特征只有输出行为;私有数据只有输入行为;共享数据具有输入和输出行为。
- 模块间可以交换数据,模块具有规定的输入和输出接口格式。
- 每个模块内的机器学习算法可自行升级或替换成其他厂商提供的算法。
- 每个模块具有封闭性,算法不能向外发送用户数据。
- 每个模块拥有必选和非必须的固定数据字段。
- 产品可以向不同模块输入私有和共享数据。
- 产品提供的数据必须符合该模块的必选数据字段,可以额外提供非必选数据字段。
- 由模块内部的算法对该模块的共享、私有数据进行标注和建模,产出相关用户特征。
- 算法可以申请授权获取其他模块共享数据和用户特征。
- 在授权范围内,产品可以获取相关模块的用户特征和共享数据部分,无法访问私有数据。
- 数据仓库定期将数据加密备份至个人服务器。
- 数据仓库定期清理过期数据。
- 数据仓库容量不足时自动提醒用户备份数据并清理空间。
- 数据仓库自动加密用户数据,防止泄露。
不同厂商的数据仓库产品应该遵循以下协议:
- 不同数据仓库相同模块的必选数据字段需要一致。
- 数据仓库内部算法和数据仓应相互独立。
- 数据仓库可以沿用以往数据和用户特征。
- 数据仓库之间传输数据需要加密。
- 不允许设置后门。
数据仓库制定协议的好处:
- 企业可以根据规范制定数据仓库,降低被巨头控制的风险。
- 数据仓库内不同模块的机器学习算法可以由不同企业制定和替换。
- 有利于进行不同企业数据仓库之间的数据迁移和升级。
- 该用户名下的数据仓库进行数据同步时是加密的,降低隐私的曝光和风险。
人工智能需要考虑运算性能、电量、发热量、数据采集和人机交互等问题。在移动端,手机依然是人工智能助理的最好载体,可穿戴式设备更多成为辅助;在家或办公室里,最好的人工智能助手载体应该一分为二,一是可与用户对话交互的电器,例如现在流行的智能音箱,还有具有大屏展示的电视,甚至是24小时供电的路由器;另外一个是具有天生优势的冰箱:它也是24小时供电,它的自动降温能力能更好地解决复杂运算时所产生的热量问题,它的庞大体积可以容纳更多存储数据的硬盘和计算机部件。
可推测,冰箱将成为个人人工智能的运算中心,就像一台服务器;手机和智能音箱等将成为与用户打交道的人工智能助理。当运算中心处理完数据后,将结果同步至相关人工智能助理,数据仓库将成为连接它们的桥梁。只有完善底层的数据共享,人工智能才能发挥出最大价值。
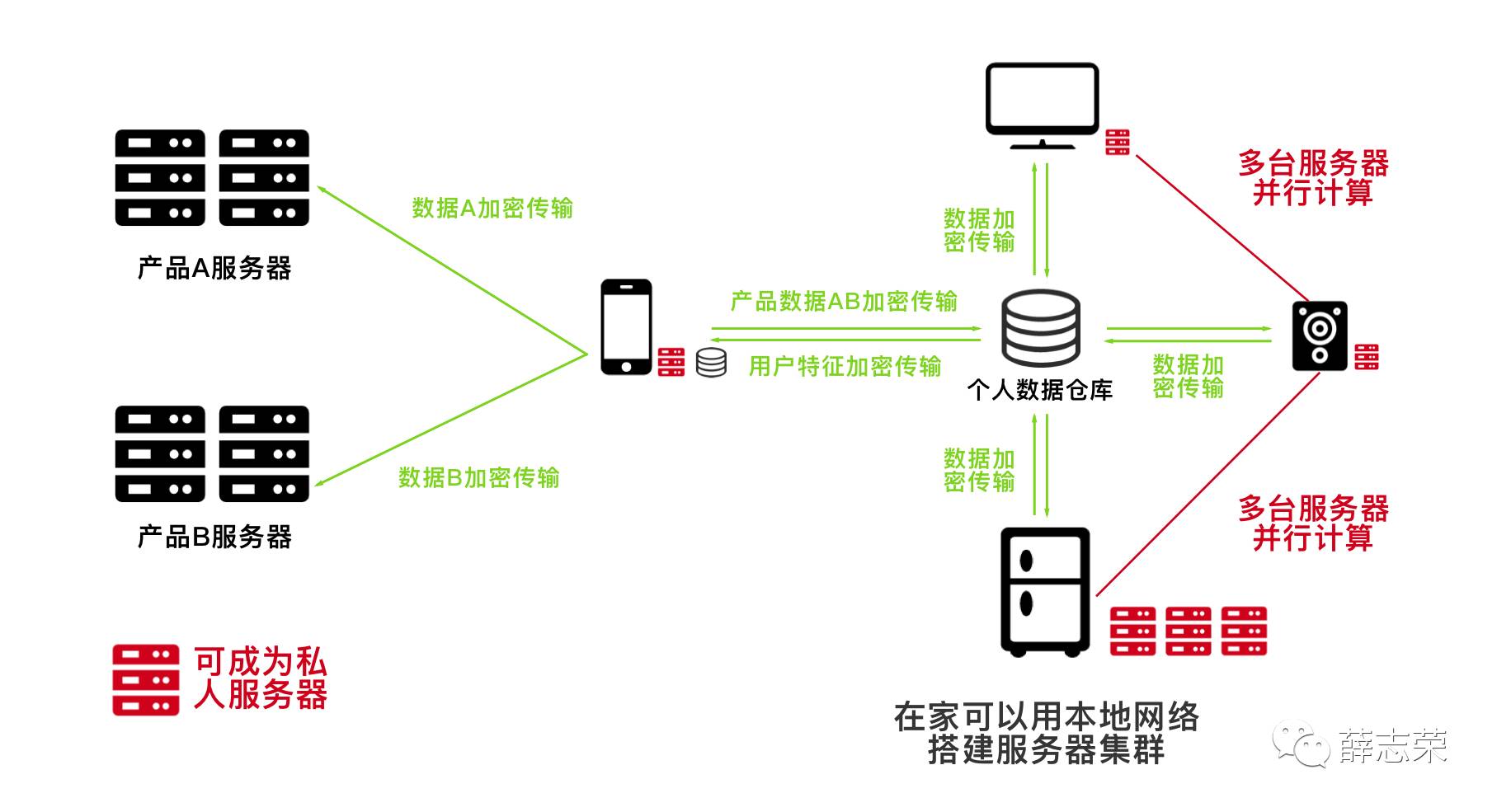
以上就是第二章的内容,下一章为《人工智能时代下交互设计的改变》,敬请期待。
信息架构
要说信息架构(Information Architecture),首先要提及图书馆,因为图书馆应该是最早能体现出信息架构的设计。当不同领域的书籍多到人类无法第一时间找到相关信息时,为了提高查找效率,人类开始给书籍添加索引,分门别类,到后面按区域摆放不同内容的书籍,即使是毫无经验的人在图书馆引导和图书管理员的帮助下也能迅速找到相关资料。
信息架构最早由美国建筑师Richard Saul Wurman在1976年提出。面对当代社会信息的不断增长和爆炸,Richard认为信息需要一个架构,一个系统来合理设计,创造了一个全新的术语——信息架构。
GUI和HTML的出现,信息架构得以广泛应用,同时也衍生出一个新的术语——页面(Page)。在GUI时代,信息架构主要由页面和流程决定。由于信息的展现必须由页面承载,而页面承载的信息应该是有限的,所以设计者需要将信息合理放入页面里。
假设总信息和页面内容的信息是固定的,那么流程也是固定的;反之亦然,假设页面信息是固定的,在固定的流程上增加一个可以扩展信息的聚合页面,那么总信息是可以无限的。当页面和流程设计被固定时,信息架构也是固定的。
在海量信息面前,固定的信息架构有助于人类记忆使用路径,降低寻找信息成本。当海量信息不断指数增长,功能变得越来越多,产品需要更多的页面来承载。更多页面会导致产品架构的层级和流程变得更复杂,也使得用户的使用成本不断增加,这并不是一件好事。
每个人的思考模式不是固定的,为了解决大部分用户需求而设计的信息架构可以帮助到用户,同时也限制了用户的思考。为了解决这个问题,信息架构需要一个优秀的导航设计来引导用户使用和随处浏览,如下图 :

为了方便用户随心所欲地挖掘更多信息,搜索是一条捷径。搜索可以让用户便捷挖掘和随时切换需要寻找的内容。
由于手机小屏幕的限制,为了展现更多内容,导航的功能和展现被削减,主要依赖标签式、抽屉式、列表式等导航模式以及每个子页面的返回按钮。如果产品架构层级过深,会导致返回步骤过长,如果用户要从一条路径跳到另外一条路径,步骤极其繁琐。
在页面里,不提供随时跳到另外一个页面的功能是完全可以理解的,因为这个功能在展现上就很难设计,而且可能会使稳定的信息架构变紊乱。但是,这个功能可以降低用户的操作成本以及更符合人的思维模式。
为了实现这个功能,让用户自行搜索信息框架或许是一个不错的选择。相对于成本很高的文字输入,人工智能下的语音输入是目前最佳的解决方案,语音助手的本质也是利用语音进行搜索。语音助手与信息架构的结合并不是一个全新的模式。iOS的Siri可以打开手机应用以及部分苹果官方产品的功能,例如在Siri模式下说出“打开秒表”可以直接打开时钟APP下的秒表页面;说出“打开显示与亮度”可以直接定位到显示与亮页面。可惜的是,目前其他厂商产品的信息架构并没有和语音助手进行深度整合,例如在Siri模式下说出“打开微信朋友圈”不能打开微信朋友圈,主要原因是目前语音助手如Siri,Google Now等没有提供相关API给第三方应用,语音助手主要以特定关键词触发功能或者发起网页搜索,功能非常局限。
对于iOS 10,Siri API仅支持六类应用程序:打车,通讯,照片搜索(在特定应用中寻找照片和视频),支付(如“用SquareCash’给约翰转账100美元”),网络电话,锻炼,体验后发现功能也非常简单。
语音助手提供搜索第三方应用信息架构将极大提高用户的效率,例如在看网易新闻时唤醒Siri说“打开微信朋友圈”可以立即打开微信朋友圈,比传统操作快捷很多。仅需要对系统和应用层面进行小成本的修改即可实现该功能,改动如下:
- 功能/页面增加新的标识/属性即可被系统语音助手搜索,本质上也是一种Deep Link。为了降低用户的记忆成本,该功能/页面应该是重要的,常用的,唯一的,例如可以通过Siri语音输入“打开微信薛志荣”、“打开微信朋友圈”直接到达相关页面,而新闻、购物等详情页、聚合页不应该添加该标识/属性。
- 被语音助手调起的页面可以考虑将返回按钮改为回首页。由于固定的信息架构使每个页面都确定上一级页面是什么,流程符合用户心理预期的话需要做到“从哪里回那里去”,但语音调起的功能/页面,对于用户来说上一级页面是哪里无关紧要,可以直接将返回上一页改为返回首页,也方便用户继续使用该应用。
- 被语音助手调起的页面有办法直接回到上一个应用/页面。例如在iOS中调起另外一个应用时,点击屏幕左上角可以回到原应用;同理,当用户在与微信好友薛志荣聊天时,使用语音助手切换到朋友圈时,点击左上角回到薛志荣的聊天页面。这样可以尽量避免打断用户的流程。
Deep Link,简单点说就是你在手机上点击一个链接之后,可以直接链接到app内部的某个页面,而不是app正常打开时显示的首页。
以上3点以图表示如下:
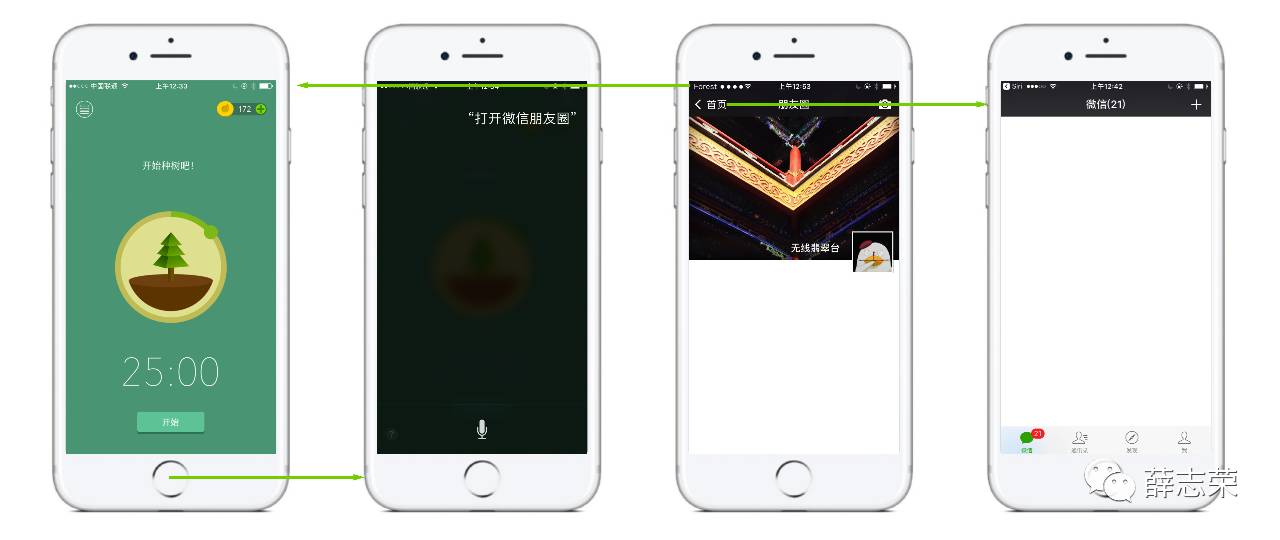
人工智能的成熟使语音助手得以快速发展,语音助手与产品信息架构的整合将使每一个功能都可以被迅速访问,产品入口不再是首页,语音助手给沉重的产品信息架构赋予了活力和流动性。该模式能更好地满足用户随心所欲的需求,也更好地提高了用户的使用效率。
流的设计
移动端产品主要分为内容(资讯、视频、音乐等等)、工具(闹钟、笔记、地图等等)、社交(聊天)和游戏四个方向。通过不同方向的结合可以孵化出不同的产品,人工智能会为这些产品带来怎样的变化?
- 人工智能使推荐系统的准确度大幅度提高,用户发现内容的成本降低,产品不再需要复杂的架构来承载不同内容。
- 人工智能可以承担更多复杂操作,工具的操作成本降低,使用流程也会随之减少,一款产品只承担一个工具不再行得通,除非有靠山,例如操作系统。往年iOS和Android的更新都会添加一些新的工具功能,加上Siri或者Google now语音指令,以及负一屏的信息聚合页面,可以使工具产品操作起来更方便。
- 对话式的聊天已经是最扁平的结构,游戏因复杂而有趣,所以人工智能不能也不应该使它们简单化,但由它驱动的VR和AR会为社交和游戏产品带来新的玩法和机遇,不过不在本次讨论中。
人工智能的驱动使内容和工具型产品的信息架构变得更加扁平,加上在不同场景触发不同功能,有可能实现“每个功能/页面都可能成为用户第一时间触达的功能/页面”,这意味着每个页面都有可能成为首页,都是信息架构的顶部,这需要产品的信息架构有很强的兼容性和扩展性。
拥有高兼容性和扩展性的模式莫过于FEED和IM,这两种结构有以下特点:
- 它们具有流的性质,结构扁平,内容可以无限延伸;
- 它们都用样式相同的空容器,例如FEED的列表或者卡片,IM的气泡;
- 空容器可以承载各式各样的媒体,包括文字、图片、音频和视频。
FEED和IM的区别是:是否主动给予信息反馈。FEED通过采集用户数据,将用户感兴趣的信息主动推荐给用户,在人工智能时代下它更适合用在内容型产品上。IM通过对话交流的形式给出问题或指令,对方根据相关内容给予反馈;在人工智能时代下它更适合用在简化流程以及工具型产品上。
既然固定内容的概念被打破,页面可以无限延伸,为了保证结构稳定和方便管理,内容和功能需要被模块化。iOS和Android在几年前已采用了首页左滑进入系统FEED的设计,不同产品用卡片的形式承载。小米MIUI9的信息助手突破了产品间的壁垒,在负一屏中将不同应用中的同类别信息整理聚合,比如收藏、支出、快递、行程、日程等,想查找使用这些信息时,无需进入不同应用查找,在信息助手中就能快捷查看和使用。
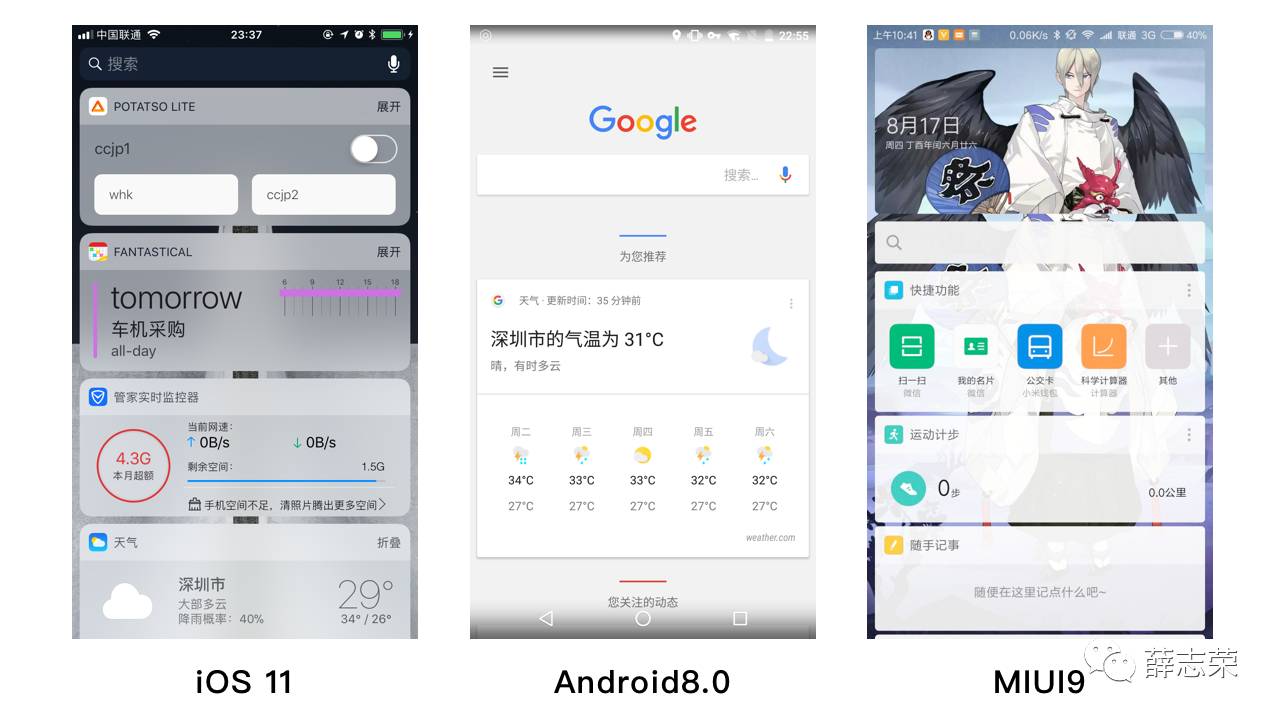
以上三种信息流都采用了模块化设计,模块化设计可以借鉴原子设计的概念。原子设计由原子、分子、生物体、模板和页面共同协作以创造出更有效的用户界面系统的一种设计方法,关于更多原子设计请看下文的推荐阅读。
上文提到,语音助手可以触达每个产品的常用甚至所有功能有助于提高用户的使用效率;全局性的人工智能助手有助于整合信息自我学习提供更多帮助,所以未来我们后续的产品需要在人工智能助手的基础上进行设计。人工智能助手包括了可以被随时唤醒的语音助手,例如Siri,它可以语音对话和提供信息的展示;以及包括了操作系统层面的FEED,例如MIUI9的信息助手,它可以主动展示相关内容和入口。
在设计产品请关注以下几点:
1.为了方便用户使用语音唤醒功能,产品功能应该是可以瞬间被理解的,以及唤醒词是方便记忆和开口的,例如可以映射到常用或者真实生活中的词语;切勿使用使用户难以开口的唤醒词;同时考虑唤醒词的兼容性问题,例如不同方言有着不同叫法。
举例:“打开微信朋友圈”完全没有问题,但“打开微信我”就非常有问题,首先意思完全看不懂,其次用户不会第一时间想到。钱包在粤语里叫做“银包”,意思相同的词语应该可以相互映射。
2.聚合不同功能的页面设计是为了方便管理和发现入口,但本身对用户来说没有太大意义。后续请减少让用户费神思考和记忆的聚合页面,这样可以避免被语音助手或系统FEED唤醒时,展示的全是功能入口。#除非这页面便于用户理解以及里面的功能非常重要#
举例:微信第三个Tab承载着不同功能,用户可能知道“朋友圈”,“摇一摇”,但可能想不到这个聚合页面叫“发现”,因为“发现”这动词太抽象,用户难以第一时间想到。用户想到“钱包”这词更多联想到的是真实世界里装钱的那个钱包,但微信的钱包功能包括了各种服务金融功能,不符合用户第一时间下的心理预期。
3.不同设计对象请考虑模块化设计,尽可能采用不同入口和页面管理设计对象,方便用户唤醒设计对象。
例子:设计对象有可能是一个功能;也有可能是通讯录中的一个名字,他们属性和功能相同,但用户的记忆对象不同。
4.常用功能允许被系统FEED集成,方便用户第一时间使用。系统FEED也会相应提供入口打开相关产品。
5.考虑避免常用功能与其他功能的耦合,降低系统FEED的结构复杂性和操作成本。
例子:在微信朋友圈可以进入朋友的详细资料并进行聊天,朋友圈和聊天两个常用功能可以不断循环,耦合紧密会导致信息架构的复杂。从产品和用户角度设计完全没有问题,但不符合FEED的轻量结构。第四点在FEED内提供产品入口是为了在完全分隔功能的情况下做的体验补偿。
6.具有操作性的功能例如设置闹钟、查看天气、购买机票等需要考虑页面的信息展示和操作流程,也需要考虑语音输入的操作流程,两者的操作步骤在用户认知上需要统一。若做不到,请提供相应场景下的合理流程。
解释:眼睛接收信息时可以随处浏览,它具有xyz和时间四个维度;耳朵接收信息时只有时间这个维度,这会导致同时接收或者筛选的信息量具有很大差异。同理,这也是为什么语音识别发生错误时,用语音修正的成本远比用键盘修正文字错误大。
1、2、4和6这四点更多考虑的是用户在使用语音或打开APP操作APP时可能会产生不同的心理预期,所以需要保证设计对象在这两种操作上的一致性。2、3和5这三点是从模块化的角度来考虑,有助于减少功能的耦合,降低信息架构的复杂程度。
新型API和组件
为了保证人工智能底层数据的一致性和完整性,第二章提及的数据仓库需要为第三方应用提供身份信息、健康数据、兴趣爱好、工作信息、财产数据、信用度、消费信息、社交圈子、活动范围9项API服务。获得用户授权后,第三方应用可以得到用户特征并向数据仓库保存用户数据。人工智能也会提供更多功能给第三方应用,例如摄像模块、语音模块、身份验证模块、支付模块等组件,提高用户体验的同时也降低了产品的开发成本。
API
上篇文章提及的数据仓库和用户特征如下:
- 身份信息:名字、性别、年龄、家乡、身份证(身份证包含前4项)、账号、现居住地址和家庭信息
- 健康数据:基础身体情况、医疗记录和运动数据
- 兴趣爱好:饮食、娱乐、运动等方面
- 工作信息:公司、职位、薪酬和同事通讯录
- 财产数据:薪酬、存款、股票、汽车、不动产和贵重物品
- 信用度:由信用机构提供的征信记录
- 消费信息:消费记录(含商品类型、购买时间、购买价格和收货地址)、消费水平和浏览记录
- 社交圈子:通讯录(含好友、同事、同学和亲戚)和社交动态(含线下和线上)
- 活动范围:出行记录、主要活动范围和旅游
以上用户特征以API形式接入,第三方应用获得用户授权后才可访问和存储相关数据,相关细节请看第二篇文章。
组件
AR是人工智能中机器视觉的重要体现,具有机器视觉能力的摄像模块可以将电子世界和现实世界结合得更紧密,第三方应用接入摄像模块可以有更多玩法。
在文章编写期间,开发者已利用苹果的ARKit实现了好多有趣玩法。同时,Google也推出了相应的ARCore,但只能用在android7.0和8.0上,普及率很低。
语音识别是人工智能中自然语言的重要体现,第三方应用接入系统语音模块可以优化自己的产品结构,提高用户的操作效率。
身份验证模块类似于现在的Oauth协议,方便用户注册和登录第三方应用。身份信息API提供的公开信息减少了用户注册时的信息填写成本,也有利于第三方应用获取更完整正确的信息。
应用注册需要个人身份信息已在国内实现,只不过是由国家规定,第三方应用注册时要求绑定手机号码,而手机号码已与个人身份信息挂钩。
由于银行想法和技术的滞后,给予国内第三方公司如阿里支付宝、腾讯财付通等创造移动支付的机会;苹果、Google在iOS和Android系统层面推出了自己的移动支付方式。但是多种支付手段都不利于个人账单管理,在使用流程上微信、支付宝等扫二维码的手段都不如系统层级使用NFC的Apple Pay方便。要统一支付流程,必须由国家机构推出新的政策来执行,统一的支付模块有助于用户移动支付和个人账单管理。
在编写文章期间,央行已宣布,从2018年6月30日起,类似支付宝、财付通等第三方支付公司受理的,涉及银行账户的网络支付业务,都必须通过“网联支付平台”处理。同时,国家已关注人工智能服务社会信用体系的建设工作,腾讯也开始建设自家信用体系,在不久的将来相信个人征信也会被国家机构统一。
其他资料阅读
- MIUI 9新体验之信息助手
- 原子设计:https://zhuanlan.zhihu.com/atomicdesign
以上就是第三章的内容,下一章本次更新的最后一篇文章《人工智能与设计的关系》,敬请期待。
人工智能对设计的影响
人工智能的普及是否使设计师失业引起了业界的一股躁动。要回答这问题,应该先弄清楚设计与人工智能的关系,我们可以从本质开始入手。
有人认为设计是为了追求美,和艺术没什么区别;但设计做久了,会有更深刻的理解:设计是为了解决问题。那么设计是什么?在网上看到了一句对设计的定义:设计是有目的的创作行为。这句话解释得非常棒。目的代表主体所追求的目标,创作是把自己的灵感、经验和感觉表达出来。设计是为了解决问题说明设计是为了解决问题的创作方案,设计为了追求美说明设计是为了解决设计对象美感和实用性的问题的创作方案,所以后者属于前者。
艺术是为了将自己的灵感、经验和感觉等主观感受表达出来。设计和艺术的本质在于是否拥有目的;目的是一种观念形态,反映了人对客观事物的实践关系。相比起艺术,设计更多是一种人对客观事物的实践方式,在考虑主观因素的同时也要顾及外界等客观因素。
从定义上来讲,人工智能是使机器代替人类实现认知、识别 、分析、决策等功能,其本质是为了让机器帮助人类解决问题。也就是说,人工智能在一定程度上也是一种设计,其目的是为了帮助人类解决问题,创作出与人类思维模式类似甚至超越人类思维模式的解决方案。
问题的复杂程度会直接影响解题人的最终方案,因为人的知识、经验、精力是有限的,很少甚至没有人会长时间都在解决同一个问题。当解题人找不到最优方案时,他们给出的方案具有一定的主观性,甚至有可能错误的。但也有例外的时候,人有神奇的技能-灵感和直觉,它们可以短时间内帮助人类找到解决问题的捷径。
目前的人工智能属于弱人工智能,暂时无法拥有人类的主观能力:灵感、感觉和感受,也没有人类的跨领域推理、抽象类比能力,只能依赖数据和经验来创作或者解决问题。但计算机比人类拥有三个优势:
- 可以在极短时间内完成超复杂的运算;
- 可以长时间不厌其烦做同一件事,而且不会累;
- 记忆力好,积累的经验可以被随时调用;
- 没有情感等主观因素,比人类更公正客观对待每个方案。
这四个优势可以使计算机在解决超复杂纯智商难题时不断探索新方案,不断积累经验,不断优化方案,通过穷举和对比,找出最佳的方案。人工智能在不同的领域积累的经验增加,它对事物间关系的洞察力也会逐步提高,它也会不断反哺提高自己解决问题的能力。当人工智能的运算能力、分析能力、洞察力超越人类时,人工智能在很多领域提供的解决方案会上优于人类。
设计除了解决问题外,还有对美的理解和创作。美感是对美的体会和感受,它是复杂的,它包含了历史、文化、环境、情感等客观和主观因素,所以不同时代、阶级、民族和地域,有着不同文化修养和个性特征的人对美的定义也不同。不同人之间有着不同程度的美感能力,有些是先天因素影响,取决于个人的感知能力;有些是在社会实践等后天因素训练出来的。
由于弱人工智能缺乏人类的主观感受和推理类比能力,以及缺乏对当代世界和社会的文化和环境的理解能力,所以弱人工智能对美感一无所知。人工智能不懂美感不代表人教不懂会机器生产美感,就像托福和雅思,即使英语不太好看不太懂文章在说什么,只要懂套路,考生也能考出一个还行的成绩。
图片处理应用Prisma通过深度学习将一张图片的风格特征分析出来,毫无保留迁移至另外一张图片。

阿里鲁班系统通过深度学习来量产Banner,设计师将自身的经验知识总结出一些设计手法和风格,再将这些手法归纳出一套设计框架,让机器通过自我学习和调整框架,演绎出更多的设计风格,上亿的Banner通过素材进入该框架后批量拼装而成。

来自微软亚洲研究院的研究员与清华大学美术学院的艺术设计专家让AI接手了繁杂专业的图文排版设计工作,他们提出了一个可计算的自动排版框架原型。该原型通过对一系列关键问题的优化(例如,嵌入在照片中的文字的视觉权重、视觉空间的配重、心理学中的色彩和谐因子、信息在视觉认知和语义理解上的重要性等),把视觉呈现、文字语义、设计原则、认知理解等领域专家的先验知识自然地集成到同一个多媒体计算框架之内,并且开创了“视觉文本版面自动设计”这一新的研究方向。
以上案例说明人工智能即使不懂审美,也可以替代人类生产可被公式化(规范化)的设计。可被公式化的设计说明这些设计是已成熟的,有规律的(模型)、受限制的(参数)、可量产的。如果不想被人工智能的美感设计领先,设计师的美感设计应该是创新的(未成熟未被发现规律的),包含更多元素的(更多复杂参数如历史、文化、环境、情感等等)。
人工智能与设计师的关系
设计是一个用处非常广泛的动词,可以搭配不同名词成为各种专业术语,例如程序设计、架构设计、交互设计、UI设计、建筑设计、材料设计等等。但设计师更多是指处理好人与设计对象之间的关系,提高体验满意度的职业,例如室内设计师是为了提高人在室内的居住质量;服务设计师是为了提高人在服务流程中的满意度;交互设计师是为了解决人与计算机的交流问题;UI设计师是为了升华人与计算机的交流体验。
上文已提到,人工智能在解决超复杂纯智商难题上最终会超越人类,而且可以生产出可被公式化(规范化)的设计,例如符合规范可批量生产的平面设计、符合规范已成熟的网页和移动端交互设计。但对于人工智能,设计师不用过多担心被取代问题,因为设计师的工作是为了提高体验和满意度,体验和满意度都是主观的,这是人工智能很难去衡量的。既然人工智能也是一种设计方案,那么设计师可以利用人工智能这工具创造出什么价值?
1. 在互联网和移动互联网时代,由于产品用户量大以及技术的限制,产品无法针对每位用户在不同场景下的需求进行设计,所以产品功能只能绝满足大部分用户都有的核心场景;还有每位用户的审美能力的差异,设计师只能考虑用更简洁的设计语言来满足大部分用户的基础审美。在人工智能的帮助下,产品有能力做到根据用户的使用场景和行为分析出用户的当前诉求,并提供相应服务。人工智能为个性化服务提供了基础,个性化服务意味着要考虑更多关于该名用户的特点,包括文化,经历,心理等因素,如何设计能更满足该名用户,这是一个全新的机会和挑战。
2. 人工智能为艺术型设计师带来更多机会。进入个性化时代的产品基本满足用户需求,相同类型的产品结构和功能会越来越接近,能为产品带来活力和差异的除了自身的底层技术基础,更多是艺术型设计师的理念和风格,以及自身品牌。就像时尚品牌优衣库和Gucci,单件商品两者的品牌和设计产生所带来的利润差距巨大,人工智能产品也可以做到。
3. 人工智能使产品的使用成本降低,信息架构扁平化,整体体验提高;但个性化设计意味着需要考虑更多元素。简单和个性化貌似矛盾,如何保持产品简单可用又能突出个性化,这也是一个全新的机会和挑战。
新的设计对象
计算机的普及和难以使用,催生出交互设计这个术语,交互设计专门解决计算机如何更好地与用户交流互动的问题。交互设计师在设计过程中总结出一个新术语:以用户为中心的设计,在设计时密切关注用户的体验和感受。用户体验设计这个术语逐渐扩散到各行各业,它所带来的价值让各个企业明白提高体验的重要性,并着手优化自家产品服务,到后面也衍生出服务设计等专业术语。
产品体验不好,用户还有其他替代选择,所以大家开始关注用户体验。但现在用户体验设计存在着一个局限性:它设计对象仍然是产品,它只关心用户在使用产品期间的体验,不关心产品对用户其他方面的影响。这是可以理解的,因为企业间之间存在着竞争,以及互通数据分析数据需要非常高的成本。所以产品体验好了最大收益自如是产品和企业,并非用户。
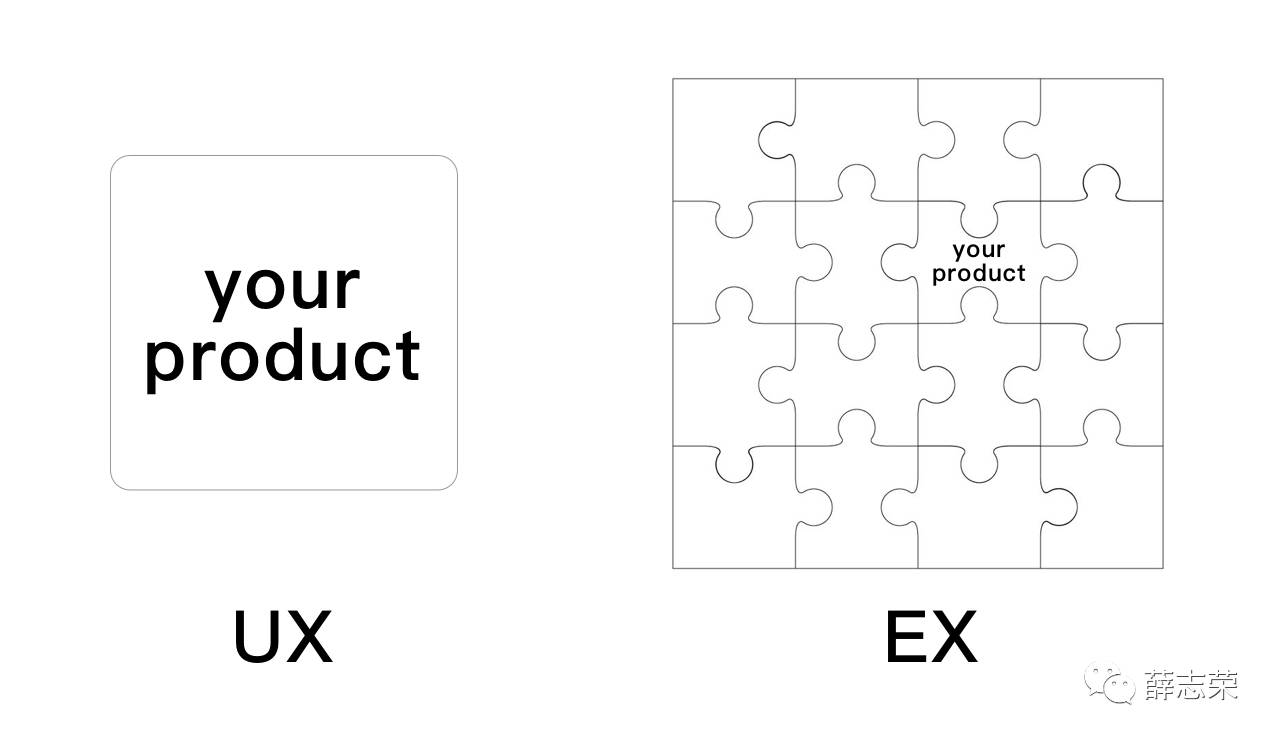
辛向阳教授提出了一个更领先的观点:EX-Experience Design,以用户经历为中心的设计。简单点说,生活中每天发生的琐碎小事不会被记住,例如吃饱睡饱;但特殊的经历会被记住,例如在迪士尼公园的路上突然跑出来一群鸭子,你会记住那次惊喜。UX构建的是每一件小事,EX构建的是用户经历,基础是每件小事之间的联动。EX更多关注全局性,就像迪士尼乐园把控全局体验为游客带来惊喜。EX是个性化服务的基础,它会从多个维度包括用户画像和行为、场景和环境、上下文的理解(上一件事情发生了什么,后面安排的事情)等为用户创造价值。
当设计对象从产品转变到用户经历时,设计师不能只考虑自己的产品体验,还要从全局出发考虑产品与产品之间的联动,考虑不同场景和突发事件时自己的产品如何服务用户。产品从单体变成一块拼图,需要考虑上下左右的关系并兼容,这对设计师来说是一个全新的挑战。
如何设计人工智能产品
人工智能为个性化服务带来新的可能,要想设计一款更友善更像人类的产品,我们先看看人类是怎么交流的。人与人之间的交流分为双向交流和单向交流,双向交流包括了问和答,单向交流包括了指令、陈述和接收信息(单向交流指对方可以给予简单的反馈,甚至不需要提供反馈)。问和指令不太一样。问是因为自己不知道,希望对方能提供相关的完整答案(这里忽略明知故问和反问两种带有目的性的情感交流);指令更多是指上级对下级的指示,他知道对方能做什么,希望对方能帮助自己完成该事情,对方完成后的反馈可能非常简单,一句“OK”“搞定”“对不起,做不到”已经能表达清楚是否完成,其反馈不需要太多内容。陈述的意思是我将信息传达给你就完成了,你可以不给予我反馈,例如演讲、授课、讲述内容等等。接收信息包括了听觉、视觉、触觉,甚至是嗅觉和味觉。
随着信息的增加,当信息超过人类的记忆容量时,人类通过交流获取信息的效率变慢,他们开始将信息通过刻画的方式记录保存下来,到后面逐渐出现了书籍。随着技术的发展,人类获取信息的方式也在逐渐增加,收音机、电视、电脑、手机逐渐出现在我们的生活中,我们先来看看人与媒介交流信息时有什么不同,再来推断人工智能能做什么。(这里的人更多是指接收信息,并非发送信息例如写书、写文章的人)
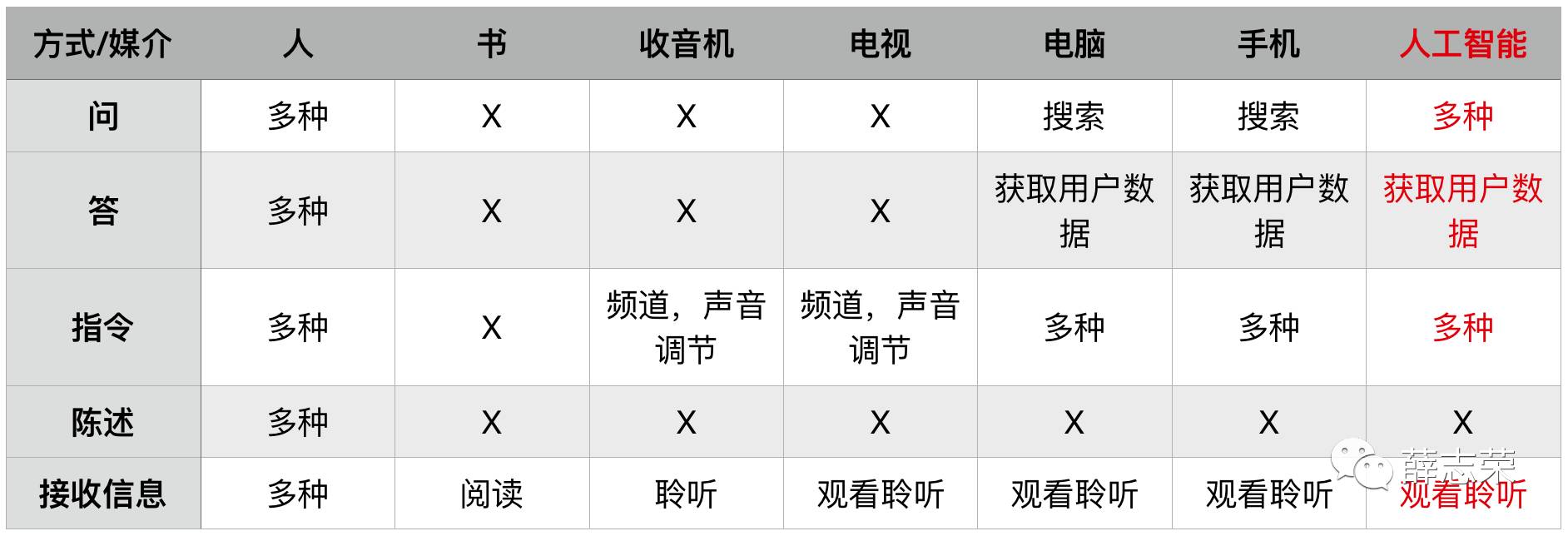
从表格可以推断出,人工智能要做到与人正常交流需要在问、答、指令、接收信息四个方面有所深造。问更多是指人通过语音、文字等对话方式提出问题(语音是最快最直接的表达方式),计算机理解问题后给出正确完整的答案。答更多是指计算机需要通过如传感器、用户事件监听等隐形手段获取更多的用户数据。指令更多是指用户通过语音和界面发出指令,计算机接收并理解指令后完成一系列的操作。接收信息更多是指人给出问题和指令后,计算机如何提供正确的答案和反馈。
如果牵扯到辈分、利益等关系,人类之间的交流务必产生情感上的交流,在交流时最能表达情感和态度的是态度和语气,人和机器交流也毫不例外。人工智能需要学会与人类交流时,根据不同场景和对话内容采用合适的态度和语气。在交流中,机器更多承担的是下级以及朋友的角色,直白点就是要你干嘛你就干嘛(准确性);要你干嘛就赶紧做(即时性);说你不对就得改(自我学习和修正);不能顶嘴(礼貌);尽管我对你很苛刻,你也要对我像好朋友一样(性格一致,需要人物设定)。
结合交流方式和情感表达,设计一款面向用户的人工智能产品时需要注意以下几点:
- 人物设定:为了避免在交流中过于死板或者态度语气时常变化过大(态度语气时常变化过大叫精神分裂),设计师应该针对不同用户群体为人工智能赋予不同角色与性格。例如针对二次元宅男群体,赋予人工智能傲娇、元气、电波女等性格;针对成熟女性群体,赋予人工智能温柔的管家角色;尽量不要赋予人工智能老板、父母、老师等角色,因为指令他们干活时,会让人类感觉到突兀。
- 准确性和即时性:需要听懂用户的问题和指令并立刻给出准确的答案或反馈。准确性和即时性是人工智能的最基础能力之一,多次回答错误显得人工智能很蠢,用户会逐渐对人工智能失去信心和信任。在技术不成熟的时候,可以引入天然呆、冒失女等具有智商不高但又很懂卖萌的角色性格弥补技术上的缺陷,这样可以通过打情感牌减少用户愤怒甚至失望的情绪。
- 自我学习与修正:当人工智能不知道答案和操作时,除了给出抱歉的反馈外,更多需要的是通过自我学习能力来修正自己的数据库,避免多次惹恼用户。
- 礼貌:及时回复、不重复说话、不反驳、不打断用户的说话和操作都属于礼貌问题,就像人类一样,有礼貌的人工智能才会受用户欢迎。
做设计时需要考虑更多数据的交互,关于人工智能底层数据设计请阅读第二章的《下一代人工智能助理》和《人工智能数据仓库》。在设计架构时需要考虑更多产品上下游之间的联动,以及通过接入通用型API和组件完善人工智能的数据库,关于移动端信息架构设计、通用API和组件请阅读第三章的《流的设计》和《新型API和组件》。对话是人工智能的基础,更多对话体验设计请阅读《Google Actions Design》。人工智能为个性化设计提供了基础,设计师需要考虑更多场景下的个性化服务,也可以引入更多风格的个性化设计,彰显出用户的魅力。
推荐阅读
1、解密:用人工智能“攻占”俄罗斯的爆款滤镜Prisma
https://www.leiphone.com/news/201607/9plguMzClDnUNoK2.html
2、设计与AI的现在:设计了1.7 亿个 banner的阿里鲁班
https://zhuanlan.zhihu.com/p/26563244
3、MSRA获ACM TOMM 2017最佳论文:让AI接手繁杂专业的图文排版设计工作
https://www.leiphone.com/news/201708/npFKzTJQuxKyCaNJ.html
4、辛向阳谈体验的EPI框架,From UX to EX
https://v.qq.com/x/page/w0180apdy2a.html
5、Actions_on_Google_Design 翻译by腾讯MXD
http://mxd.tencent.com/weixin/doc/Actions_on_Google_Design.pdf
以上是本轮更新的最后一篇文章。后续会调研人工智能时代下不同设计领域的新机遇和挑战,敬请期待。
原文:http://www.woshipm.com/ai/843133.html
既然来了,说些什么?