生成超逼真的肖像画
深度卷积神经网络已经被广泛用于显著目标检测,并获得了 SOTA 的性能。在 CVPR 2019 的一篇论文中,来自加拿大阿尔伯塔大学的研究者曾提出了边界感知显著目标检测网络 BASNet,并衍生出了一系列流行的工具。今年,该团队又提出了一种用于肖像画生成的深度网络架构 U^2-Net,不仅所需的计算开销较少,而且生成肖像画具有丰富的细节。该论文被 ICPR 2020 会议接收。

从人脸图片生成艺术肖像画的 AI 应用不在少数,但效果惊艳的不多。上面这张图片中的输入 – 输出结果,来源于一个 GitHub 热门项目 U^2-Net (U square net),开源至今已经获得了 1.7K 的 star 量。

这项研究来自阿尔伯塔大学的一个团队,论文此前已被国际模式识别大会 ICPR 2020 会议接收。

- 论文链接:https://arxiv.org/pdf/2005.09007.pdf
- 项目地址:https://github.com/NathanUA/U-2-Net
最近,研究者又将其应用于人脸肖像画的生成中,并基于 APDrawingGAN 数据集为此类任务训练了新的模型。不管是儿童肖像还是成年男性、成年女性,都能获得相当细致的生成结果:


近年来,显著性目标检测广泛应用于视觉跟踪和图像分割等领域。随着深度卷积神经网络(CNN)的发展,尤其是全卷积网络(FCN)在图像分割领域的兴起,显著性目标检测技术得到了明显的改善。
大多数 SOD 网络的设计都有一个共同的模式,也就是说,它们专注于充分利用现有的基础网络提取的深度特征,例如 Alexnet、VGG、ResNet、ResNeXt、DenseNet 等。但这些主干网络最初都是为图像分类任务设计的。它们提取代表语义含义的特征,而不是代表局部性细节或全局对照信息,这对于显著性目标检测至关重要。并且这些网络通常需要在 ImageNet 数据上进行预训练,效率比较低。
为了解决这个问题,阿尔伯塔大学的研究者提出了 U^2-Net。研究团队在论文中介绍,U^2-Net 是一个简单而强大的深度网络架构,其架构是两层嵌套的 U 形结构。该研究提出的 ReSidual U-block(RSU)中混合了不同大小的接收域,因此它能够从不同尺度中捕获更多的语境信息。此外,RSU 中使用了池化操作,因此在不显著增加计算成本的情况下,也能够增加整个架构的深度。
方法
在方法部分,研究者不仅详细阐释了其提出的残差 U-block 以及利用该 U-block 构建的嵌套 U 形架构,而且还描述了该网络的监督策略和训练损失。
残差 U-block
受到 U-Net 网络的启发,研究者提出了新型残差 U-block(ReSidual U-block, RSU),以捕获阶段内的多尺度特征。RSU-L (C_in, M, C_out)的结构如下图 2 (e)所示,其中 L 表示编码器中的层数,C_in、C_out 分别表示输入和输出通道,M 表示 RSU 内层通道数。
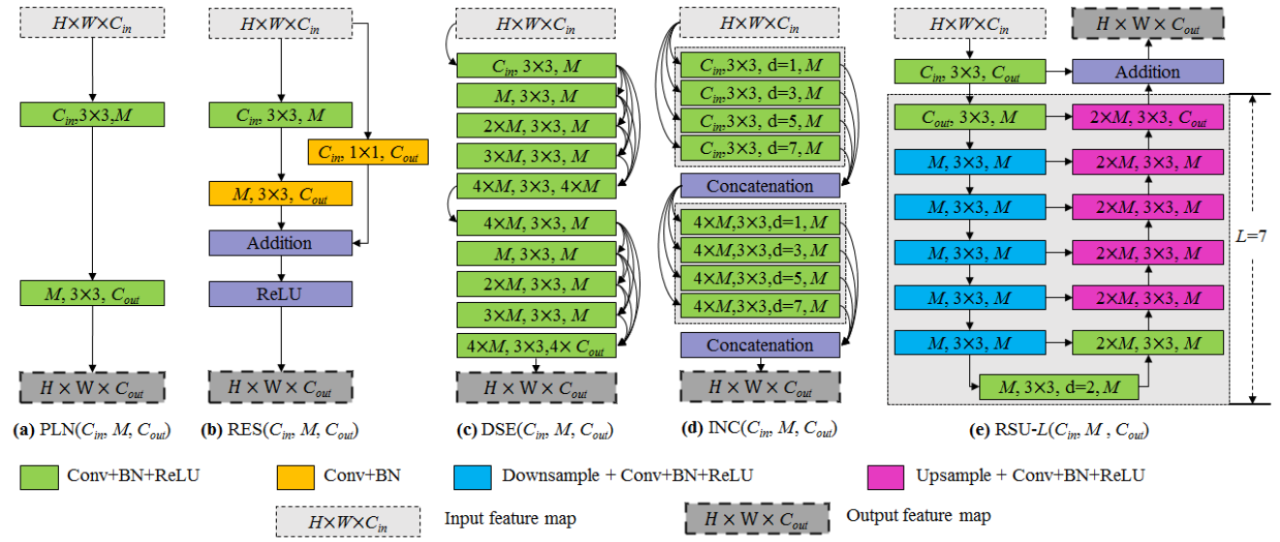
本研究提出的 RSU 与现有其他卷积块的结构对比
具体而言,RSU 主要有三个组成部件,分别是一个输入卷积层、一个高度为 L 的类 U-Net 对称编码器 – 解码器结构以及一个通过求和来融合局部和多尺度特征的残差连接。
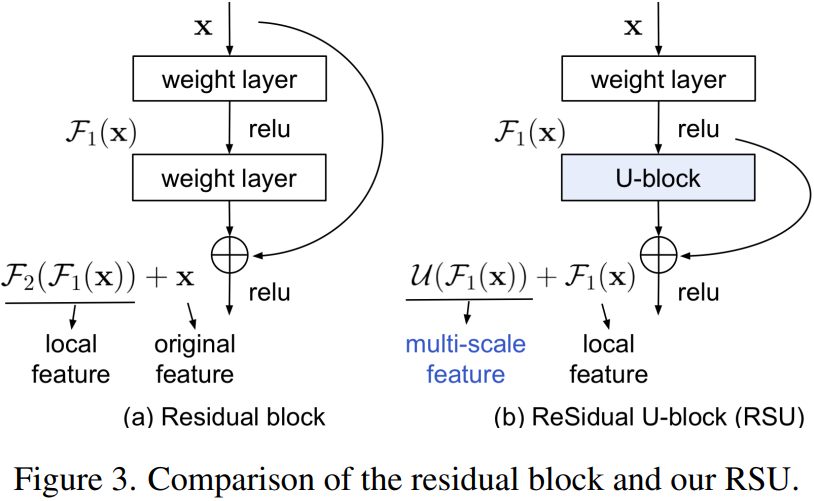
为了更好地理解设计理念,研究者在下图 3 中对 RSU 与原始残差块进行了比较。结果显示,RSU 与原始残差块的最大区别在于 RSU 通过一个类 U-Net 的结构替换普通单流卷积,并且通过一个由权重层转换的局部特征替换原始特征。
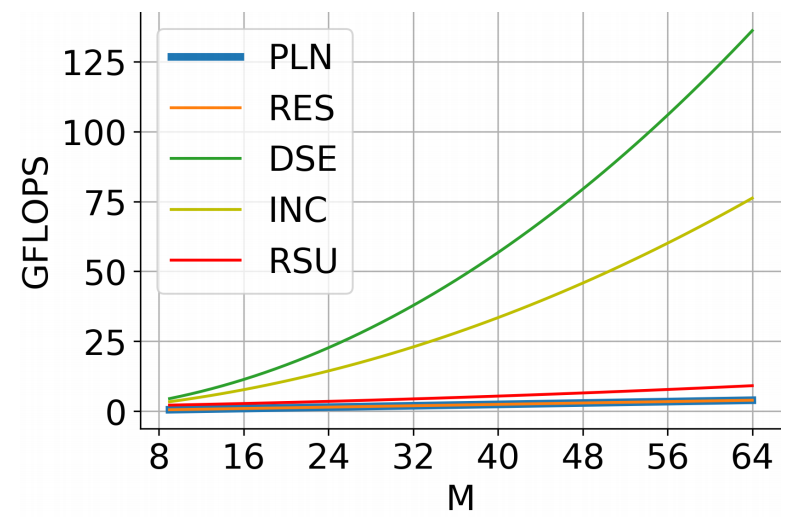
更值得注意的是,得益于 U 形结构,RSU 的计算开销相对较少,因为大多数运算在下采样特征图中应用。下图 4 展示了 RSU 与其他特征提取模块的计算成本曲线图:
U^2-Net 架构
研究者提出了一种用于显著目标检测的新型堆叠 U 形结构 U^n-Net。从理论上讲,n 可以设置成任意正整数,以构建单级或多级嵌套 U 形结构。研究者将 n 设置为 2 以构建二级嵌套 U 型结构 U^2-Net,具体如下图所示:
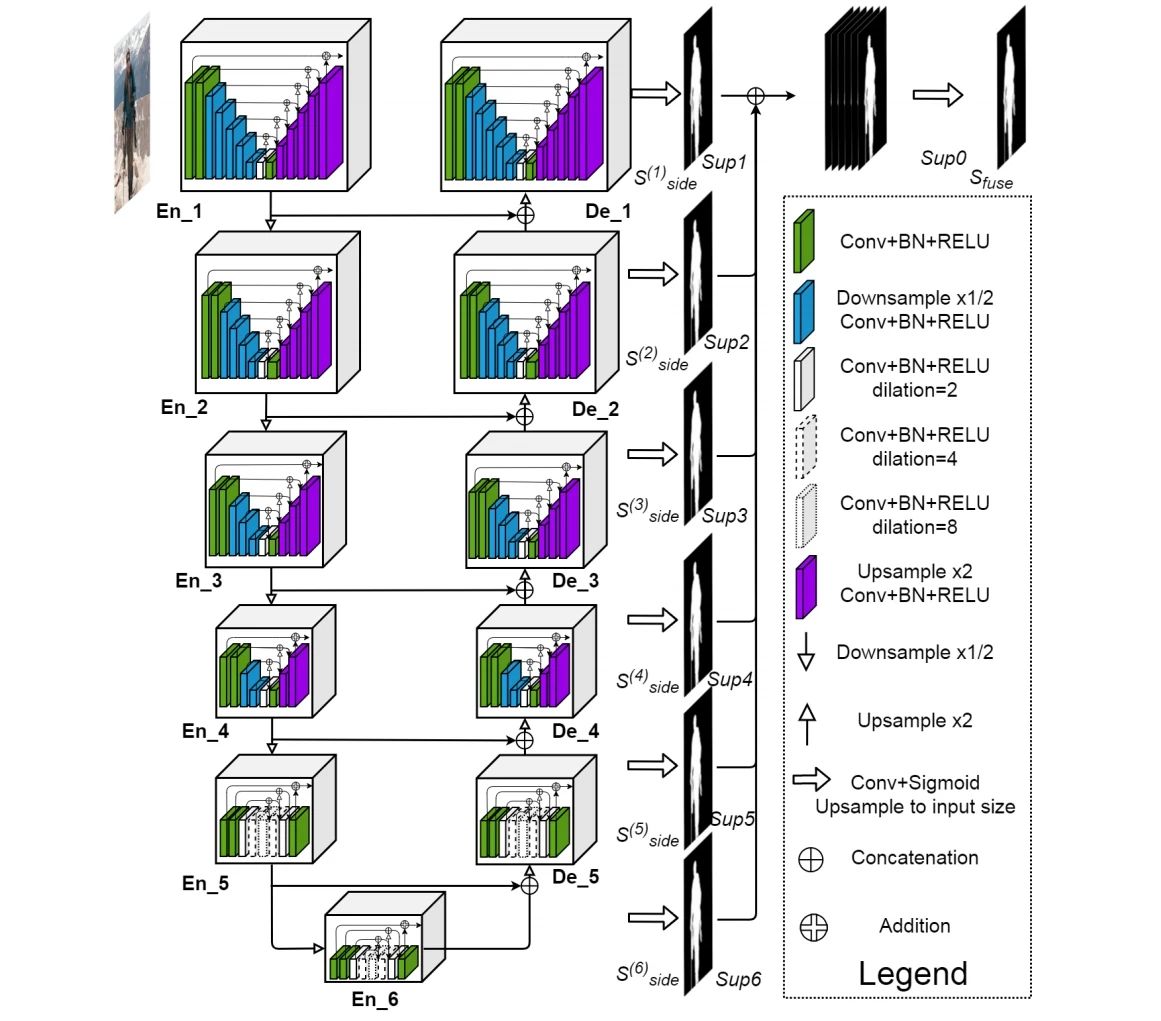
具体而言,U^2-Net 主要由三部分组成:(1)6 阶段编码器;(2)5 阶段解码器;(3)与解码器阶段和最后编码器阶段相连接的显著图融合模块。
总的来说,U^2-Net 的设计构建了具有丰富多尺度特征以及较低计算和内存成本的深度架构。此外,由于 U^2-Net 架构仅在 RSU 块上构建,并且没有使用任何经过图像分类处理的预训练主干网络,所以在性能损失不大的情况下 U^2-Net 可以灵活且方便地适应不同的工作环境。
监督
在训练过程中,研究者使用了类似于整体嵌套边缘检测(Holistically-nested edge detection, HED)的深度监督算法。训练过程定义如下:
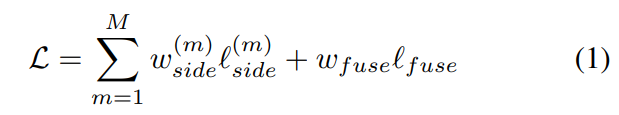
训练过程努力将上述公式 (1) 的整体损失最小化。在测试过程中,研究者选择将融合输出 l_fuse 作为最终显著图。
实验
研究者在 DUTS-TR 上训练了 U^2-Net 网络,该数据集包含 10553 张图片,是目前最大和最常用的显著目标检测数据集。研究者对数据进行了水平翻转,总共获得了 21106 张训练图像。在评估阶段,研究者使用了 DUTOMRON、DUTS-TE、HKU-IS、ECSSD、PASCAL-S、SOD 六个常用的基准数据集来评估方法。
控制变量研究
实验从三个方面来验证 U^2 -Net 的效果:基本块、架构和主干网络。
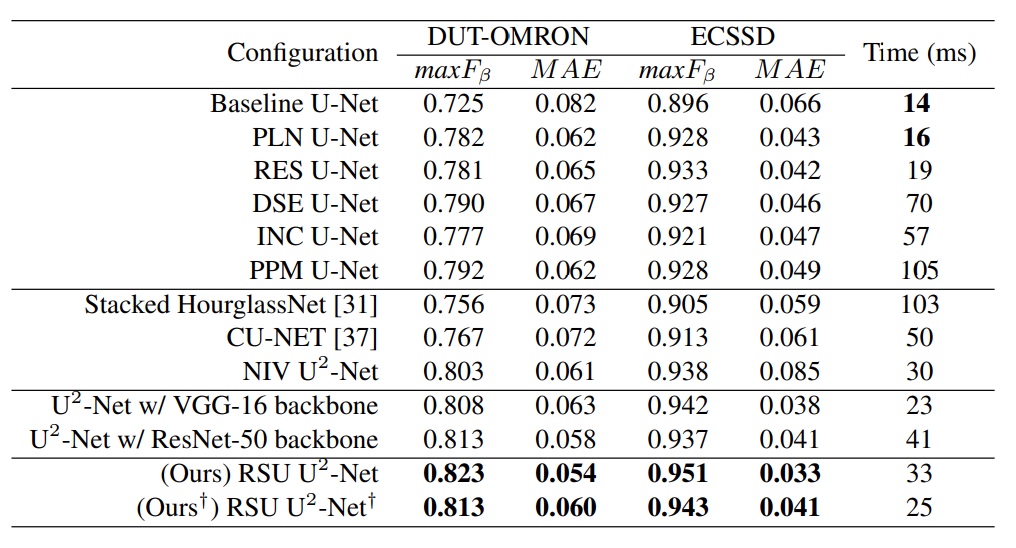
表 2:不同模块的控制变量实验结果。“PLN”、 “RES”、 “DSE”、“INC”、“PPM” 和 “RSU” 分别代表普通卷积块、残差块、 密集块、初始化块、金字塔池化模型和残差 U-block。粗体字代表的是性能最佳的两种。
不同方法性能对比
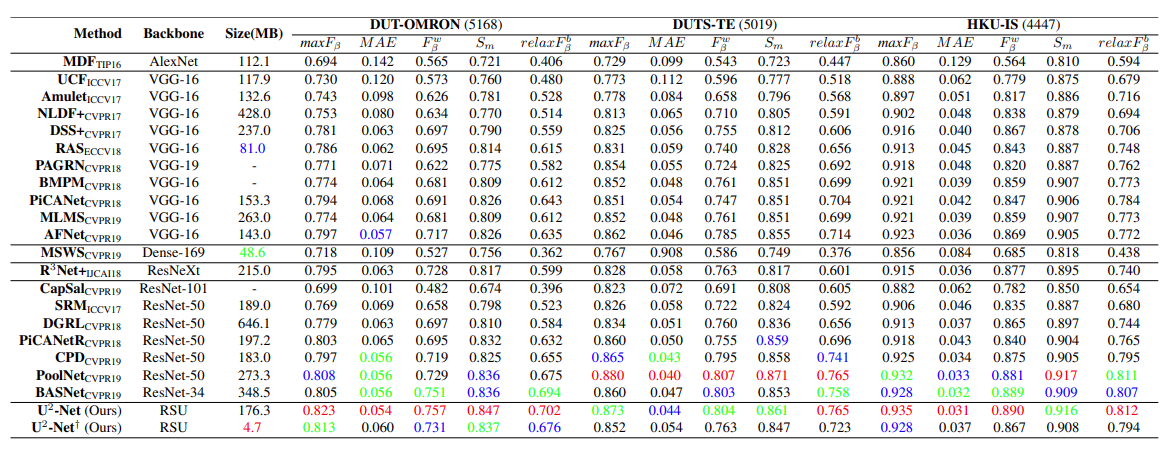
下表 3 展示了在 DUT-OMRON、DUTS-TE、HKU-IS 三个数据集上,本文方法与其他 20 种 SOTA 方法的对比。红、绿、蓝分别代表了性能上的最佳、第二和第三。
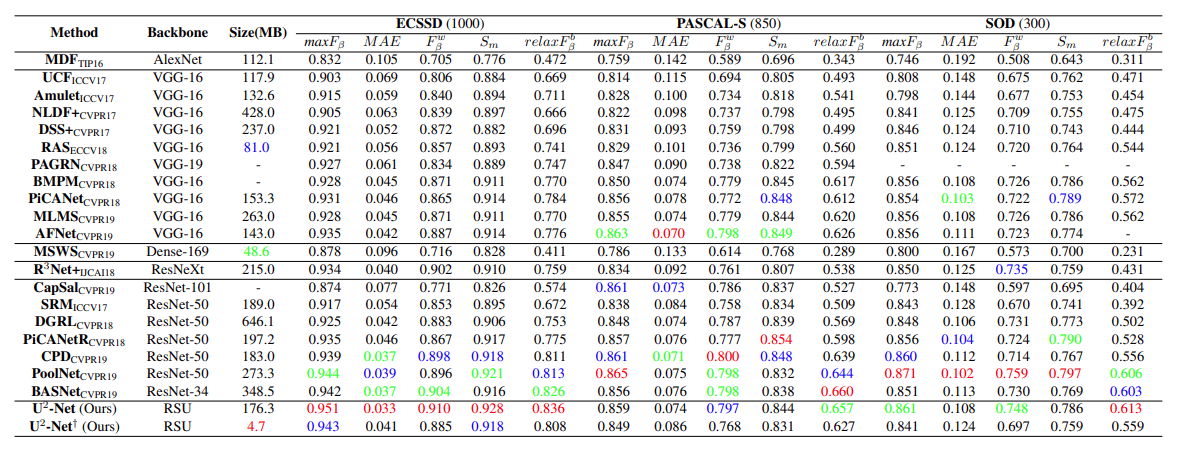
下表 4 展示了在 ECSSD、PASCAL-S 和 SOD 三个数据集上的方法对比结果。
下图 7 展示了本文方法与其他 7 种 SOTA 方法定性比较的结果。(a) 是原图, (c)是本文方法的生成结果。

研究团队
该研究的第一作者秦雪彬,目前是加拿大阿尔伯塔大学的一名计算机科学在读博士,共同作者还包括 Zichen Zhang、Chenyang Huang、Masood Dehghan、Osmar R. Zaiane 和 Martin Jagersand。

左起:秦雪彬、Zichen Zhang、Chenyang Huang。
此前,机器之心也介绍过秦雪彬等研究者在显著目标检测方面的另一篇论文《BASNet: Boundary-Aware Salient Object Detection》,该论文被 CVPR 2019 接收。研究公布后,业界随之诞生了许多基于 BASNet 的图像处理工具,比如「隔空移物」神器 AR Cut & Paste、在线抠图程序「ObjectCut」等。
原文:https://mp.weixin.qq.com/s/DTVjncaERBmDfOkvXv_3qg
既然来了,说些什么?