相信你的模型:初探机器学习可解释性研究进展
XAI 主要解决以下问题:对于使用者而言某些机器学习模型如同黑盒一般,给它一个输入,决策出一个结果。比如大部分深度学习的模型,没人能确切知道它决策的依据以及决策是否可靠。如图 1 的 output 所示,为一般网络给出的决策,缺乏可解释性的结果让使用者感到困惑,严重限制了其在现实任务中的广泛应用。
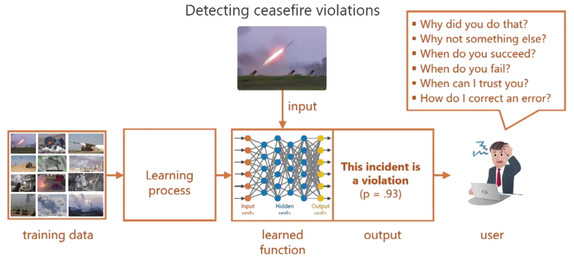
图 1 如今的深度学习 [1]
所以为了提高机器学习模型的可解释性和透明性,使用户和决策模型之间建立信任关系,近年来学术界进行了广泛和深入的研究并提出了可解释的机器学习模型。如图 2,模型在决策的同时给出相应的解释,以获得用户的信任和理解。

图 2 可解释的机器学习 [1]
对于机器学习模型来说,我们常常会提到2个概念:模型准确性(accuracy)和模型复杂度(complexity)。模型的复杂度与准确性相关,又与模型的可解释性相对立。因此我们希望找到一种模型如图 3 所示,具有可解释性的同时尽可能保证模型的准确性和复杂度。
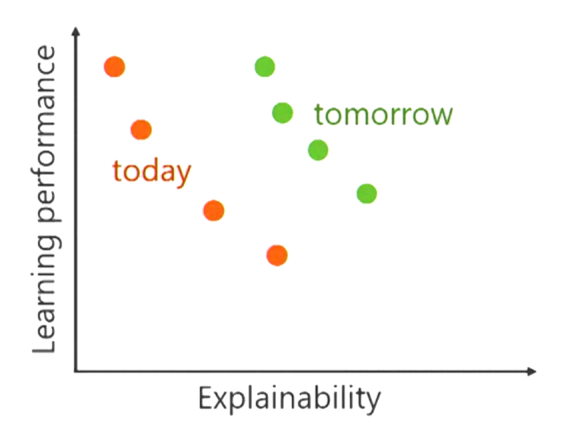
图 3 模型性能与可解释的关系 [1]
由于人机交互这一需求的急剧增加,可解释人工智能(XAI)模型引起了学者的广泛研究。2019 年 Sule Anjomshoae[2] 等人提出将 XAI 分为数据驱动(data-driven)XAI 和目标驱动(goal-driven)XAI。除了 XAI,2018 年英国曼彻斯特大学 Cangelosi 教授和意大利 Chella 团队 [3] 不仅注意到人对机器可解释性的信任,还研究了机器对人的信任模型。他们是基于心理学的 ToM(心智理论)来建立一个认知模型来实现。以下我们将从上述这两方面详细说明。
人对机器的信任
对决策提供解释的能力是智力的一个标志,但什么形式的解释最能促进人类对机器的信任还不明确。朱松纯教授团队最近在 science robotics 杂志上提出了一个 GEP 集成框架 [4],整合数据驱动的触觉模型和符号行动规划器(symbol planner)提供功能和机械解释。研究者设计了一个打开具有多种安全锁机制的药瓶的操作任务,然后通过一个机器人在该任务上对这个集成式框架进行了检验。框架如图 1 所示,主要分为演示、学习和评价三方面。
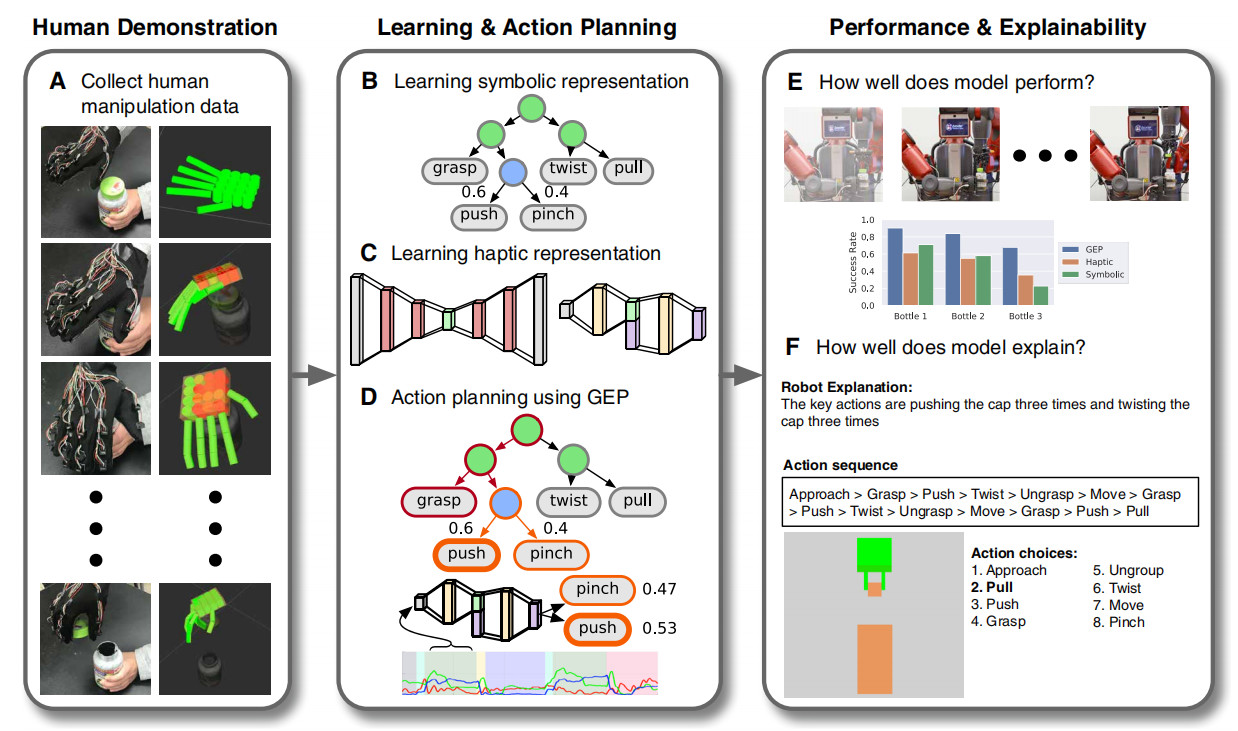
图 1 GEP 总体框架 [4]
(A)使用触觉手套收集人体演示数据。(B)通过诱导语法模型来学习符号表示。(C)使用自动编码器学习触觉表示。对机器人动作的功能解释。(D)使用 GEP 框架对这两部分进行整合,得出行动规划。(E)不同模型的性能比较。(F)产生有效的解释以促进人类的信任。
为了学习人类如何打开药瓶,演示部分采用一个带有力传感器 [5] 的触觉手套来捕捉打开药瓶时的姿势和演示者的力。为了测试机器人系统的泛化能力,我们用与训练数据不同的瓶子进行测试。
但由于人类与机器人的表现形式不同,即人有 5 个手指,而机器人可能只有 2 或 3 个。因此机器人系统的触觉模型不能简单地复制人的姿势和施加的力;相反,机器人应该模仿动作,以打开药瓶的最终效果为目标。这就必须使用一个触觉预测模型(haptic model)让机器人根据感知到的人类和机器人的力量,像人类一样想象下一步骤最可能出现的动作及姿势。
触觉预测模型的三步过程如图 2 所示:图 2(A)通过触觉手套(有 26 个维度的力量数据)收集*人类*状态中的力量信息。同时图 2(C)从机器人末端执行器中的传感器(具有三维力数据)记录的*机器人*状态中的力量信息。结合人类和机器人两方面信息,在中间的图 2(B)的 autoencoder 体现了触觉表征和动作预测模型。通过学习一个自动编码器,将触觉映射网络同行动预测网络进行结合,并预测下一步采取什么行动。
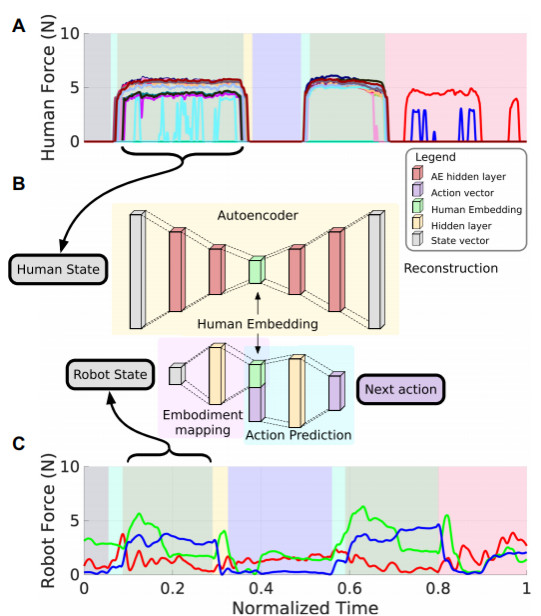
图 2 触觉预测模型 [4]
又因为打开药瓶是一种具有挑战性的多步操作,所以使用符号表示有利于捕捉任务的必要约束。一个优良的符号规划器是机器人系统基于人类演示学习一个随机的语法模型,并将其用作获取任务的组成性质和长期限制的符号表征。符号行动规划器用来编码任务执行序列的语义知识。它使用随机的上下文无关语法来表示任务,其中终端节点 (单词) 是动作,句子是动作序列。给定一个动作语法,规划器根据动作历史找到下一个执行的最佳动作,类似于用给出的一部分句子预测下一个单词。
最后,这种动作序列被输入到 [6] 中提出的语法归纳算法中用来解析和预测机器人动作序列。我们用 the Earley parser [7] 解析器和动作语法作为符号规划器(symbolic planner)来表示计划动作的过程。另外,利用这种规划器还可解决单样本的模仿学习问题,详见论文《Continuous Relaxation of Symbolic Planner for one-shot Imitation Learning》[8]
为了将符号规划器所引导的长期任务结构与从触觉信号中学习到的操作策略相结合,可以使用 GEP 将符号规划器与具体化的触觉模型 f 相结合 [7],其公式如下式 1,是同时考虑语法先验和触觉信号可能性的一个后验概率。其中 G 为动作语法,f_t 是触觉输入,a_{t+1} 是用符号规划器得到的 t+1 时刻动作,最后找到 t+1 时刻的最佳动作 a_{t+1}^{*}。使用 GEP 框架搜索最有可能发生下一步动作的例子,如图 3c 所示。搜索过程从前缀树的根节点开始,这是一个空的终端符号。当搜索到达叶节点时,搜索就会终止,所有非叶节点都表示终端符号(即动作), 而最后一个非叶节点将是执行的下一个操作的概率。
![]() (1)
(1)
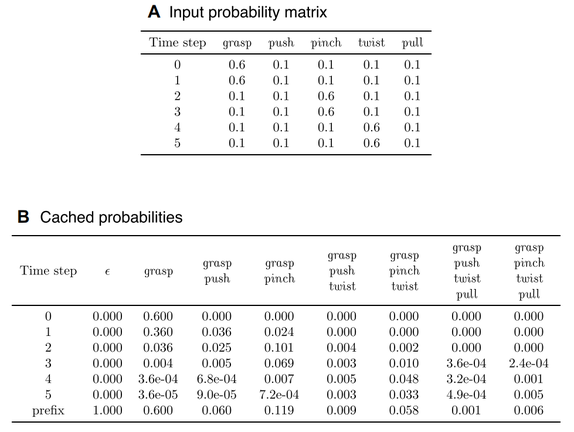
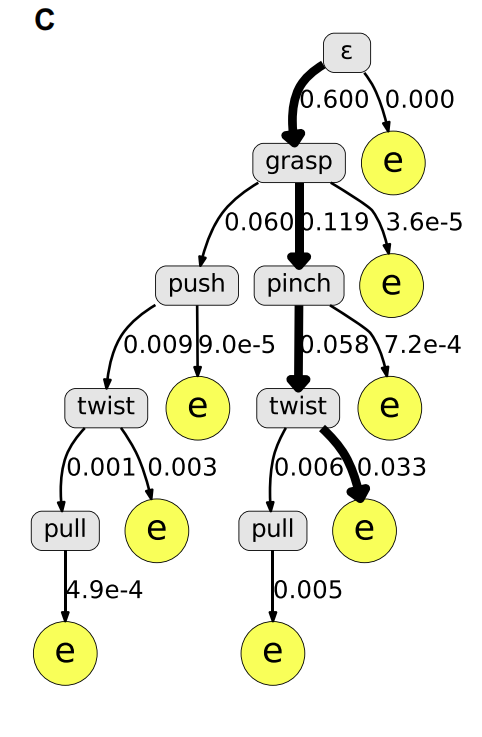
图 3 GEP 搜索过程示例 [4]
实验结果如图 4,显示了机器人打开人类演示的三个药瓶和两个新药瓶的成功率。可以看出触觉模型和符号规划器的性能各有千秋,但使用 GEP 的组合规划器在所有情况下都能产生最佳性能。因此,整合由符号规划器提供的长期任务结构和触觉模型提供的实时感觉信息可以达到最佳的机器人性能。
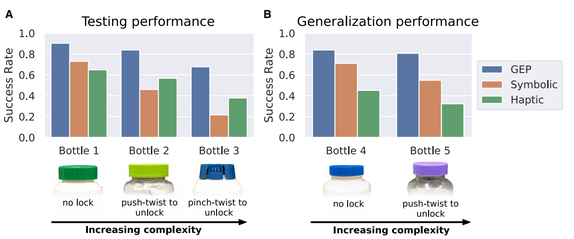
图 4 机器人在不同条件下的性能 [4]
触觉模型和符号规划器能够实时地向人类解释机器人的行为,所以验证机器的可解释性与人类信任的关系由五组实验进行。实验分组为基准不解释组(baseline)、符号解释组(symbolic)、触觉解释组(haptic)、GEP 解释组(GEP)和文本解释组(text)组成。对于基准不解释小组,参与者只观看从试图打开药瓶的机器人录制的 RGB 视频,其余各个组别的解释如图 5 所示。

图 5 不同组别的不同解释形式 [4]
在实验阶段,向参与者提供了两次机器人演示,一次成功打开一个药瓶,一次拧同样的瓶子失败。在不同解释小组下观察机器人演示后,参与者提供一个信任评级的问题:「你在多大程度上相信这个机器人有能力打开一个药瓶?(信任值在 0 到 100 之间)」。这一评级为机器人打开药瓶的能力提供了一个定性的衡量人类信任的标准。
人类对不同解释组的信任结果如图 6A 所示,我们发现,具有符号规划和触觉解释面板的 GEP 组产生的信任度最高,其评分显著优于不解释的基准组。此外,符号组(symbolic)的高信任度表明查看了演示机器人实时内部决策的符号动作规划器解释在培养信任方面起着重要作用。
然而,触觉解释组(haptic)的信任度与基准组确没有显著差异,这意味着仅仅基于触觉信号的可视化界面解释并不是获得信任的有效方法。最后,文本组(text)提供了一个摘要描述来解释机器人的行为反而降低了人们的信任度,这表明在培养人类信任方面,对机器人长期内部决策的详细解释要比解释机器人行为的摘要文本描述有效得多。
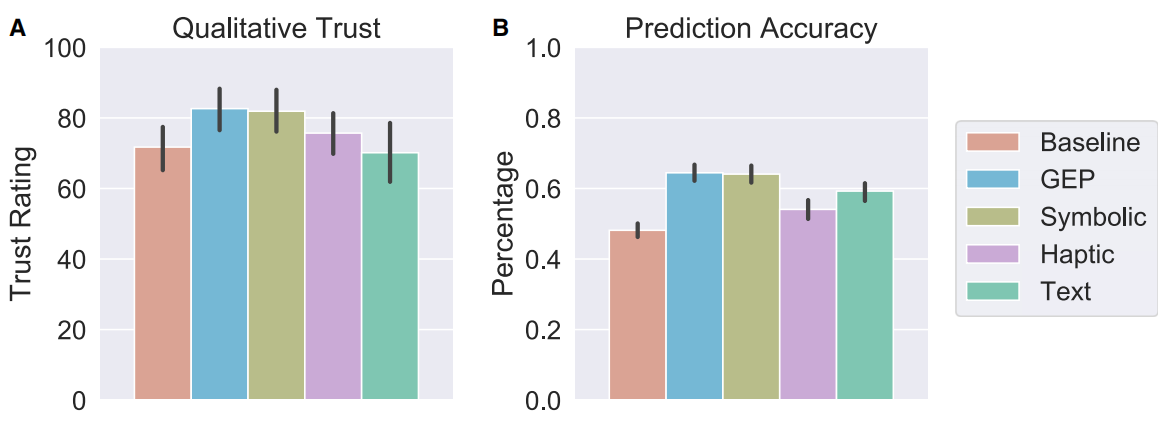
图 6 信任度与性能比较 [4]
除了信任度比较,不同模型的预测正确率也是我们关注的重点。由图 6B 可以看出,基于预测准确性的实验产生了与 A 图相似的结果。GEP 组参与者的预测准确率明显高于基准组。因此,摘要文本解释和仅仅基于触觉信号的解释并不是获得人类信任的有效方法,而 GEP 和符号解释与机器人系统建立了相似程度的人类信任。总之,人类似乎需要机器人对执行的动作序列的内部决策进行实时地解释,以建立对执行多步骤复杂任务机器的信任。
因此,对于任务性能来说,触觉模型对于机器人成功地打开具有高复杂度的药瓶起着重要的作用。然而,获得人类信任的主要贡献是由符号规划器提供的实时机械解释得到的。因此,促进最信任的模型组件不一定与那些有助于最佳任务性能的组件相对应。这种差异意味着应该将高信任组件与高性能组件集成起来,以最大限度地提高人类的信任和任务的成功执行。具有可解释模型的机器人为将机器人融入日常生活和工作提供重要的一步。
机器对人的信任
前面的一个研究着重于如何提升机器人里面的模型,也就是将信任归因于机器人,但很少有人研究相反的情况。Cangelosi 等基于心理学的 ToM(Theory of Mind)理论提出一个机器人的认知模型 (cognitive architecture),可以根据交互信息决策人类的可信程度,模拟机器人被不断被「欺骗」或者被「协助」时的「心理活动」。
ToM 是一个关于人类认知的解释,说明了一个人可以推理别人心理状态的能力。比方说,一个人在与另外一个人相处的时候,会「代入」别人的角色,从而理解对方的意图。这种能力是随着年龄增长而逐渐学习的,比如著名的 Anne-and-Sally 实验。该文在 Patacchiola 和 Cangelosi[9] 研究的基础上设计了一个贝叶斯信任模型,该模型结合了 ToM 和信任的各个方面,并将其用于重现范德比尔特实验 [10]。
该实验本是一个测量不同年龄是否拥有 ToM 的心理学实验,正确判断他人可信度的能力与 ToM 的成熟度密切相关。一个成熟的 ToM 在成年人中具有普遍性,它允许一个人事先进行行为预测并提供可信度方面的线索。但对于学龄前儿童来说,却不一定拥有这种成熟的 ToM。因此范德比尔特实验是给 90 名学龄前儿童(平均分为 3 岁、4 岁和 5 岁)播放了一段视频,其中一名成年演员扮演帮助者或是骗子,分别给参与者提供了正确或错误的建议。最后,参与者将决定是否遵循这一建议。根据儿童提交的选择,我们发现只有 5 岁的孩子才能区分帮助者和骗子的区别,从而证明拥有一个成熟的 ToM。
该文利用人形机器人 Pepper,集成了一个基于 ToM 的认知和信任模型,并得到情景记忆系统的支持来重现该实验。该机器能够学会区分值得信赖和不值得信赖的信息来源,并且根据其互动修改信任的行为。这种认知机器人系统需要能够经受发展心理学试验 [10],即 5 岁以上儿童才具有成熟的 ToM 认知能力。机器人需要拥有一个信任和 ToM 计算模型,才能预测交互者的意图。该模型是由 Patacchiola[9] 设计发展的贝叶斯信任模型,它采用概率方法来解决信任估计问题。
模拟机器人和交互者之间联系的贝叶斯网络(BN)如图 1 所示,节点 XR 和 YR 分别代表机器人的信任和动作。节点 YR 的后验分布决定机器选择要执行的操作。YI 和 YR 之间的联系代表了交互者的意见对代理人行动的影响。然后,机器人的行动是其自己的信念 XR 和交互者的行动 YI 的结果。最后,对真实情况 XI 的估计使机器能够有效地区分是否信任交互者。
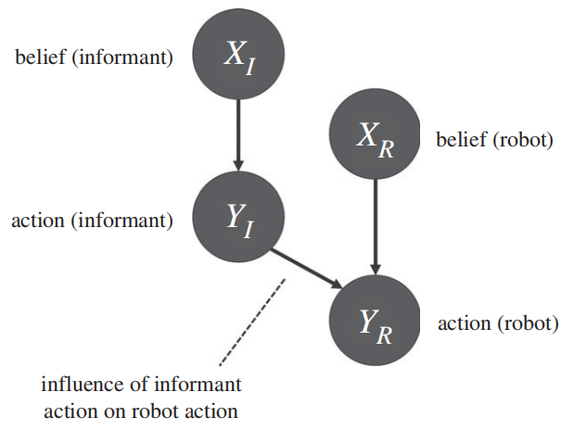
图 1 人机交互联系 [3]
利用自己过去的记忆在现在和未来做出决定是增强认知过程的一项重要技能,将使机器人对一个从未熟悉过的人作出合理的反应。这种算法应该遵循的设计准则是:记忆随着时间的推移而消失;细节与记忆的数量成比例地消失;令人震惊的事件,如惊喜和背叛,应该比普通的经历更难忘记。为此情景信任网络借鉴了在移动机器人定位中广泛使用的粒子滤波技术,当遇到未知的交互者时,该组件都会动态生成一定数量的事件(episode)来训练新的 BN。表示记忆重要度 v 的计算如下式 2,定义在 [0,1] 区间中。其中\varepsilon {j}^{(s{i})} 是形成BN网络 si 中的第 j 次事件,E_{si} 是由不同事件构成的重放数据集。计算的含义为每一事件的信息量 I(\varepsilon {j}^{(s{i})}) 与其重放数据集的总信息熵 H(E_{si}) 之间的差值,再除以与记忆形成时间有关的离散时间差\Delta t+1。
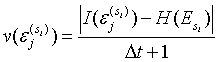 (2)
(2)
一旦计算出了 v 值,就可以将其投影为在重放数据集中的重复次数 F(v),如式 3 所示。通过观察机器人与不同的交互者而得到的重要值 v 的概率分布,将重要度 v 小于或等于 0.005 的值丢弃(即遗忘该记忆)。
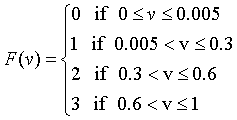 (3)
(3)
回到类粒子滤波的算法中,我们知道在粒子滤波中粒子的生成和分布都有技巧。在本文中,如何生成重放事件(replay episode)中的样本数 k?我们应该假定:k 太低会导致一个容易受骗的信任网络,高值则会使它对变化不敏感,而目标是让机器人对交互者的信任是坚定但多变的。在不同 k 值下产生的情景信任网络的平均熵如图 2 所示,可以看出当取 k=10 时,大小适中、偶数并且还是局部熵的最小值。
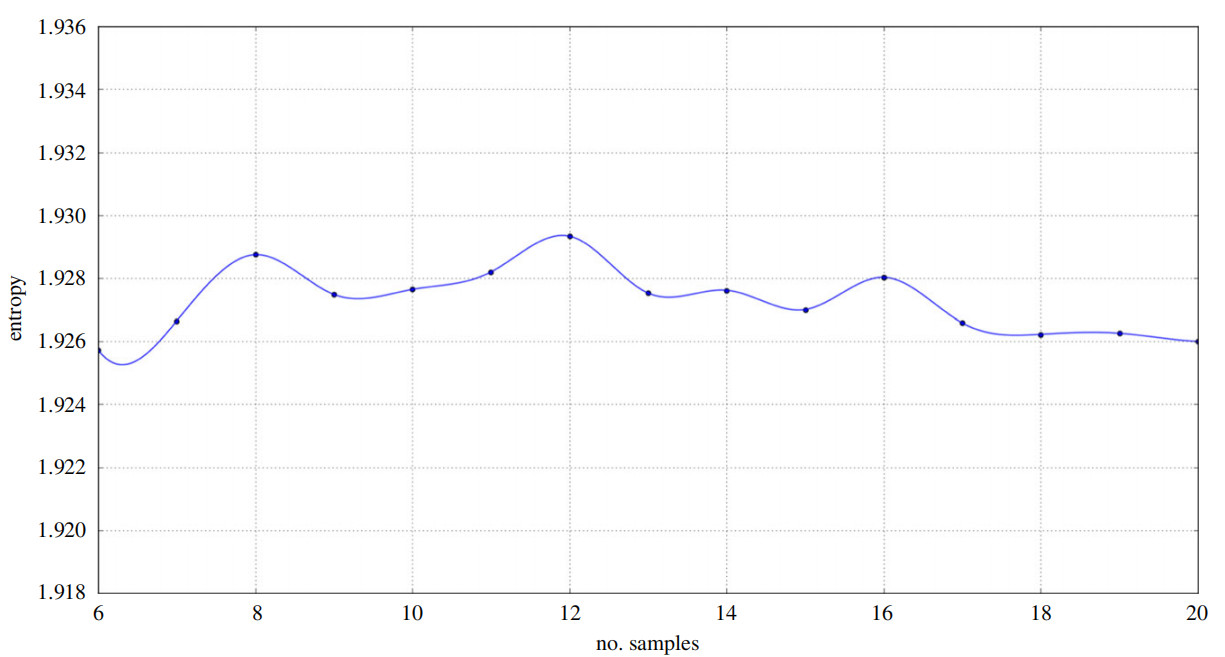
图 2 不同样本数产生的情景信任网络的平均熵 [3]
实验中,让机器人分别与 8 位交互者沟通,其中有帮助者(helper)和欺骗者(tricker)。结果如图 3 所示,绿色条表示信任,红色条倾向于不信任。当横坐标信任因子 T=0 时,交互者既不可信也不信任,机器人会随机行事。由此可见,一个经常被骗的机器人会倾向于不信任它第一次遇到的人,而一个受到善待的机器人会尝试去信任,直到提出相反的证据。
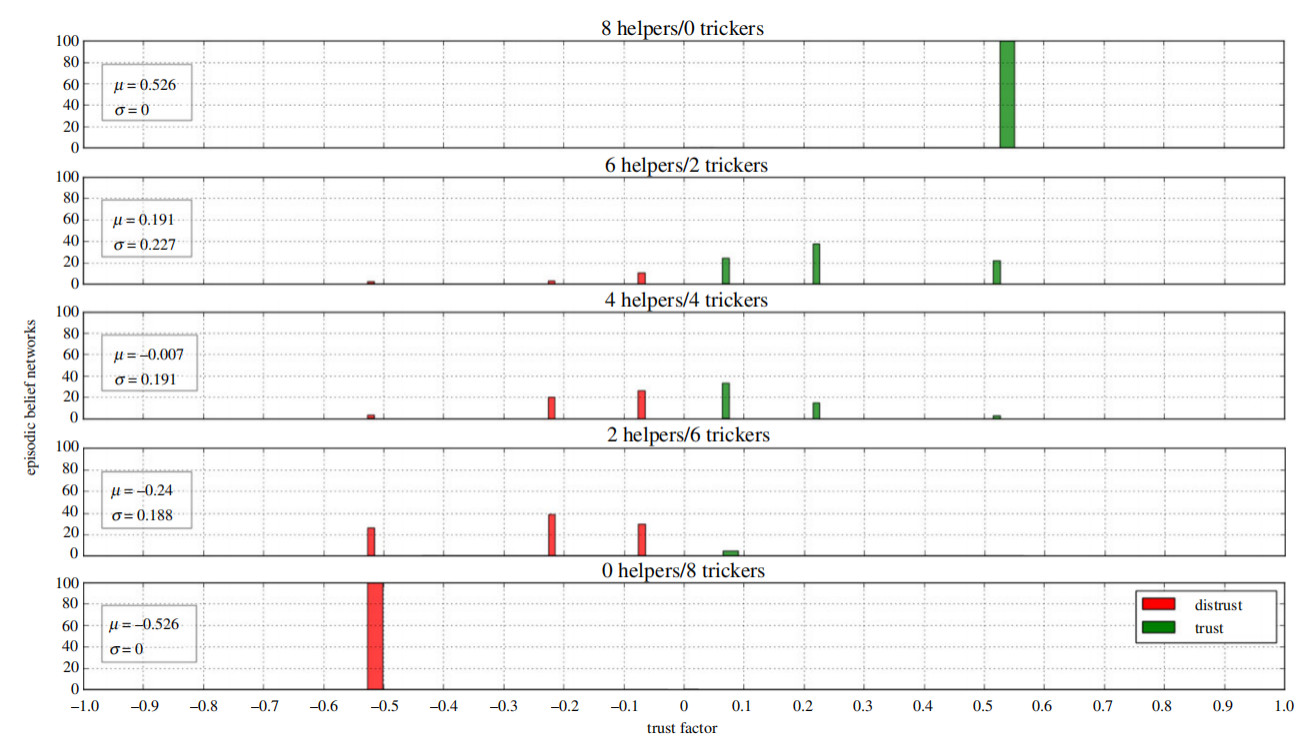
图 3 不同交互下情景信任网络的可靠性直方图 [3]
训练时采用一种人形机器人模拟交互场景,如图 4 所示,机器人通过与交互者的沟通,进行人脸识别并训练 ToM 模型,决策是否相信该交互者提供的信息。其中 helper 提供正确信息,tricker 提供错误信息。
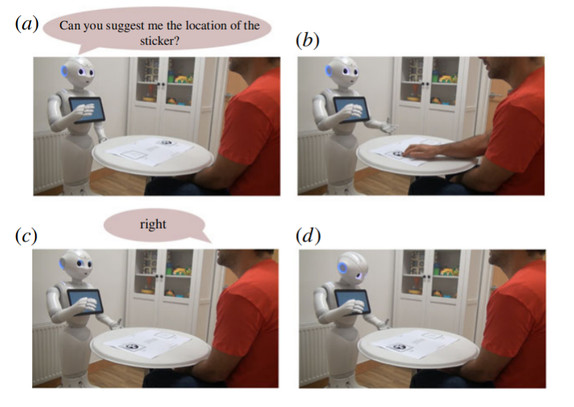
图 4 人机交互场景步骤 [3]
在测试时,当识别到已知人脸时,会调用相关的信任值并在随后的计算中使用。否则,将使用情景记忆为交互者快速生成一个新的信任值。如果信任的结果与事实不符,则检测错误,更新信任值,使机器人逐渐适应交互者的行为。
这种方法将原始模型集成到一个完整的机器人体系中,并扩展了一个情景记忆组件,使其能够利用过去的经验来发展性格,以提高其认知能力与互动安全。未来,由于 BN 网络的灵活性,重新组织节点和边缘权值使其在现实生活中会更加通用,并且可以拓展到机器人辅助手术、老年人护理和自主驾驶 [11] 等领域。
总结
可解释机器学习在机器人上的应用主要体现在人机交互中,这两篇文章从不同角度和不同方法衡量和提高机器对人的信任与人对机器的信任。朱松纯教授团队的文章主要利用可解释性 AI 方法,令用户清楚机器人的动作选择。另外利用 GEP 框架,该模型在某程度上结合了人类的触觉力度,从而使概率框架中的学习和搜索更有效率。但本文基本上只是学习了开瓶子一个任务动作,该框架如何学习多任务,或者甚至归纳出新的行为动作,还是一个疑问。通过人机交互的问卷实验,从而定量检验人的信任程度也是一个创新之处。
而 Cangelosi 等的文章,则利用一个巧妙的方向,考虑模仿机器人的心理「变化」。也是因为事件比较简单,所以可以利用类蒙地卡罗的方法学习各种的离散状况。但如果当事件变得复杂时,该方法是否可以 scalable,怎样有效率地学习,应该是下一步的方向。
机器对人的信任在实际应用中占有重要地位。在军事安全中,如果机器盲目相信操作者指令,则可能导致错误的决策。在医疗手术中,如果医生盲目相信机器作出的判断,则很有可能危及病人的生命。所以,如何平衡两者之间的关系还需进行广泛的研究。我们也希望未来的人机协作可以更安全、可信地进入社区,服务大众。
分析师简介:张雨嘉,现在西安理工大学攻读模式识别方面的硕士学位,主要研究基于深度学习的图像视频处理方法,对机器学习也抱有极大的兴趣。作为机器之心技术分析师的一员,希望能跟各位一起研究探讨,共同提高学习。
参考文献:
[1]DARPA 2019 人工智能研讨会
[2]Anjomshoae S, Najjar A, Calvaresi D, et al. Explainable agents and robots: Results from a systematic literature review[C]//Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems. International Foundation for Autonomous Agents and Multiagent Systems, 2019: 1078-1088.
[3]Vinanzi S, Patacchiola M, Chella A, et al. Would a robot trust you? Developmental robotics model of trust and theory of mind[J]. Philosophical Transactions of the Royal Society B, 2019, 374(1771): 20180032.
[4]Edmonds M, Gao F, Liu H, et al. A tale of two explanations: Enhancing human trust by explaining robot behavior[J]. Science Robotics, 2019, 4(37).
[5]Liu H, Xie X, Millar M, et al. A glove-based system for studying hand-object manipulation via joint pose and force sensing[C]//2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017: 6617-6624.
[6]Tu K, Pavlovskaia M, Zhu S C. Unsupervised structure learning of stochastic and-or grammars[C]//Advances in neural information processing systems. 2013: 1322-1330.
[7]Qi S, Jia B, Zhu S C. Generalized earley parser: Bridging symbolic grammars and sequence data for future prediction[J]. arXiv preprint arXiv:1806.03497, 2018.
[8]Huang D A, Xu D, Zhu Y, et al. Continuous Relaxation of Symbolic Planner for One-Shot Imitation Learning[J]. arXiv preprint arXiv:1908.06769, 2019.
[9]Patacchiola M, Cangelosi A. A developmental Bayesian model of trust in artificial cognitive systems[C]//2016 Joint IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob). IEEE, 2016: 117-123.
[10]Vanderbilt K E, Liu D, Heyman G D. The development of distrust[J]. Child development, 2011, 82(5): 1372-1380.
[11]Helldin T, Falkman G, Riveiro M, et al. Presenting system uncertainty in automotive UIs for supporting trust calibration in autonomous driving[C]//Proceedings of the 5th international conference on automotive user interfaces and interactive vehicular applications. 2013: 210-217.
原文:https://mp.weixin.qq.com/s/7ngrHNd4__MN3Wb5RMv6qQ
既然来了,说些什么?