偏差与方差, 欠拟合与过拟合
前言
这篇文章是关于调参中常遇到的欠拟合与过拟合问题,通过将四个概念: 偏差,方差,欠拟合,过拟合连接起来,能够更好的理解这个问题。 最后,针对该问题,我提出了几点建议。
泛化能力[1]
机器学习算法的目的是使得我们的算法能够在先前未预测的新输入上表现良好,而不只是在训练集上表现良好。 而这种在新数据上表现良好的能力被称为算法的泛化能力。
简单来说, 如果说一个模型在测试集上表现的与训练集一样好,我们就说这个模型的泛化能力很好;如果模型在训练集上表现良好,但在测试集上表现一般,就说明这个模型的泛化能力不好。
从误差的角度来说,泛化能力差就是指的是测试误差比训练误差要大的情况,所以我们常常采用训练误差,测试误差来判断模型的拟合能力,这也是测试误差也常常被称为泛化误差的原因。
欠拟合与过拟合
我们在训练模型的时候有两个目标:
- 降低训练误差,寻找针对训练集最佳的拟合曲线。
- 缩小训练误差和测试误差的差距,增强模型的泛化能力。
这两大目标就对应机器学习中的两大问题: 欠拟合与过拟合。 具体来讲:
- 欠拟合是指模型在训练集与测试集上表现都不好的情况,此时,训练误差,测试误差都很大。
- 过拟合是指模型在训练集上表现良好,但在测试集上表现不好的情况,此时,训练误差很小,测试误差很大, 模型泛化能力不足。
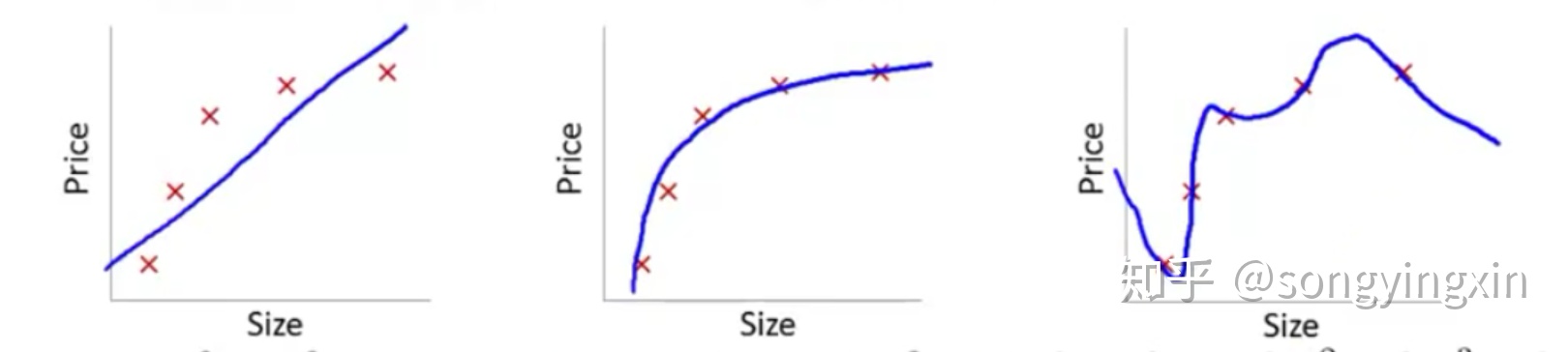
如上图所示, 左边这幅表示欠拟合,其不能很好的拟合所有的点;最右边这幅为过拟合,其太认真的拟合所有的点,导致模型的泛化能力很差。
偏差与方差 — bias 与 variance [2]
上文是从泛化的角度来谈,本节从数学角度来分析一下误差的两大来源:偏差与方差。
- 偏差指的是模型在训练集上的错误率, 如5%。其实是与训练误差成线性关系的。
- 方差指的是模型在开发集(或测试集)上的表现与训练集上的差距。如开发集的错误率比训练集差1%。其实是与 测试误差 – 训练误差 成线性关系的。
从偏差与方差的角度来分析模型常常会有四种情况:
- 偏差很低,方差很高: 意味着训练误差很低,测试误差很高,此时发生了过拟合现象。
- 偏差很高,方差很低: 意味着训练误差,测试误差都很高,此时发生了欠拟合现在。
- 偏差,方差都很高: 意味着此时同时发生了欠拟合和过拟合现象。
- 偏差很低,方差很低: 意味着训练误差很低,测试误差也很低,表示我们的模型训练的结果很好。
偏差与方差的权衡
从上面的分析我们可以看出,在实际中,从偏差与方差的角度能够比欠拟合,过拟合的角度更好的对当前的模型状态进行很好的评估。在实际中构建模型的过程中,其实就是对于偏差与方差之间的权衡,因为很多改进算法在减少偏差的同时往往会增大方差,反之亦然。
通过学习曲线来判断偏差与方差
在代码中添加一些曲线能够帮助你更好的分析模型状态,本节仅探讨对于分析偏差,方差有帮助的学习曲线,更多的学习曲线需要根据自己的需要来给定。
训练集样本数量与训练误差,测试误差。 对于模型来说,当训练集的数据量达到一定程度之后,数据量的提升对于模型的提升已经微乎其微了,此时你需要权衡是否需要花费精力去获取更多的数据来提升模型性能。假设你的训练集有1000个样本,那么通过规模为100,200, 300,…,1000的样本集分别运行算法,我们就能得到训练误差,测试误差随训练集数据变化的曲线:
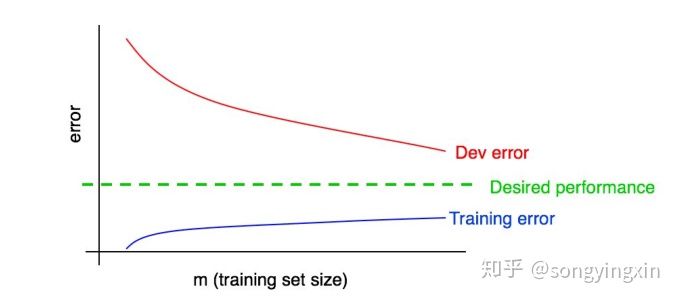
从上图中,我们根据 Training error 与 Dev error的收敛情况完全可以很轻松的判断出此时偏差与方差的状况。
如何降低偏差[2]
当你发现你的模型的偏差很高时,这也意味着你的训练误差很高,建议从以下几个角度试试:
- 加大模型规模(更换其余机器学习算法,神经网络可以增加每层神经元/神经网络层数):偏差很高很有可能是因为模型的拟合能力差,对于传统机器学习算法,各个方法的拟合能力不同,选择一个拟合能力更好的算法往往能够得出很好的结果。 对于神经网络(拟合能力最强)而言,通过增加网络层数或增加每层单元数就能够很好的提高模型的拟合能力[3][4][5]。
- 根据误差分析结果来修改特征: 我们需要将错误样本分类,判断可能是由于什么原因导致样本失败,在针对分析结果,增加或减少一些特征。
- 减少或去除正则化: 这可以避免偏差,但会增大方差。
- 修改模型结构,以适应你的问题:对于不同的问题,不同的模型结构会产生更好的结果,比如在CV中常用CNN,而在NLP领域常用LSTM。
如何降低方差[2]
当你发现你的模型的方差很高时,说明你的模型泛化能力弱,可以从以下几个角度分析:
- 重新分析,清洗数据。 有时候,造成方差很大的原因往往是由于数据不良造成的,对于深度学习来说,有一个大规模,高质量的数据集是极为重要的。
- 添加更多的训练数据。增大训练数据能够往往能够提高模型的泛化能力。
- 加入正则化。正则化是机器学习中很重要的一个技巧,你必须掌握它。
- 加入提前终止。意思就是在训练误差变化很慢甚至不变的时候可以停止训练,这项技术可以降低方差,但有可能增大了偏差。 提前终止有助于我们能够在到达最佳拟合附近,避免进入过拟合状态。
- 通过特征选择减少输入特征的数量和种类。 显著减少特征数量能够提高模型的泛化能力,但模型的拟合能力会降低,这意味着,该技术可以减小方差,但可能会增大偏差。 不过在深度学习中,我们往往直接将所有特征放入神经网络中,交给算法来选择取舍。
- 减少模型规模,降低模型复杂度(每层神经元个数/神经网络层数): 谨慎使用。 一般情况下,对于复杂问题如CV或NLP等问题不会降低模型复杂度,而对于简单问题,采用简单模型往往训练速度更快,效果很好。
- 根据误差分析结果修改输入特征。
- 修改模型架构,使之更适合你的问题。 一般可以选择简单模型的情况下,不选择复杂模型。
Reference
[1] Deep Learning — 花书
[2] Machine learning yearning: Technical Strategy for AI Engineers, in the era of Deep learning
[3] can shallow network fit any function — 李宏毅视频
[4] Deep Potential of Deep — 李宏毅视频
[5] Is Deep better than Shallow? — 李宏毅视频
既然来了,说些什么?