强化学习介绍及应用
1. 强化学习是什么?
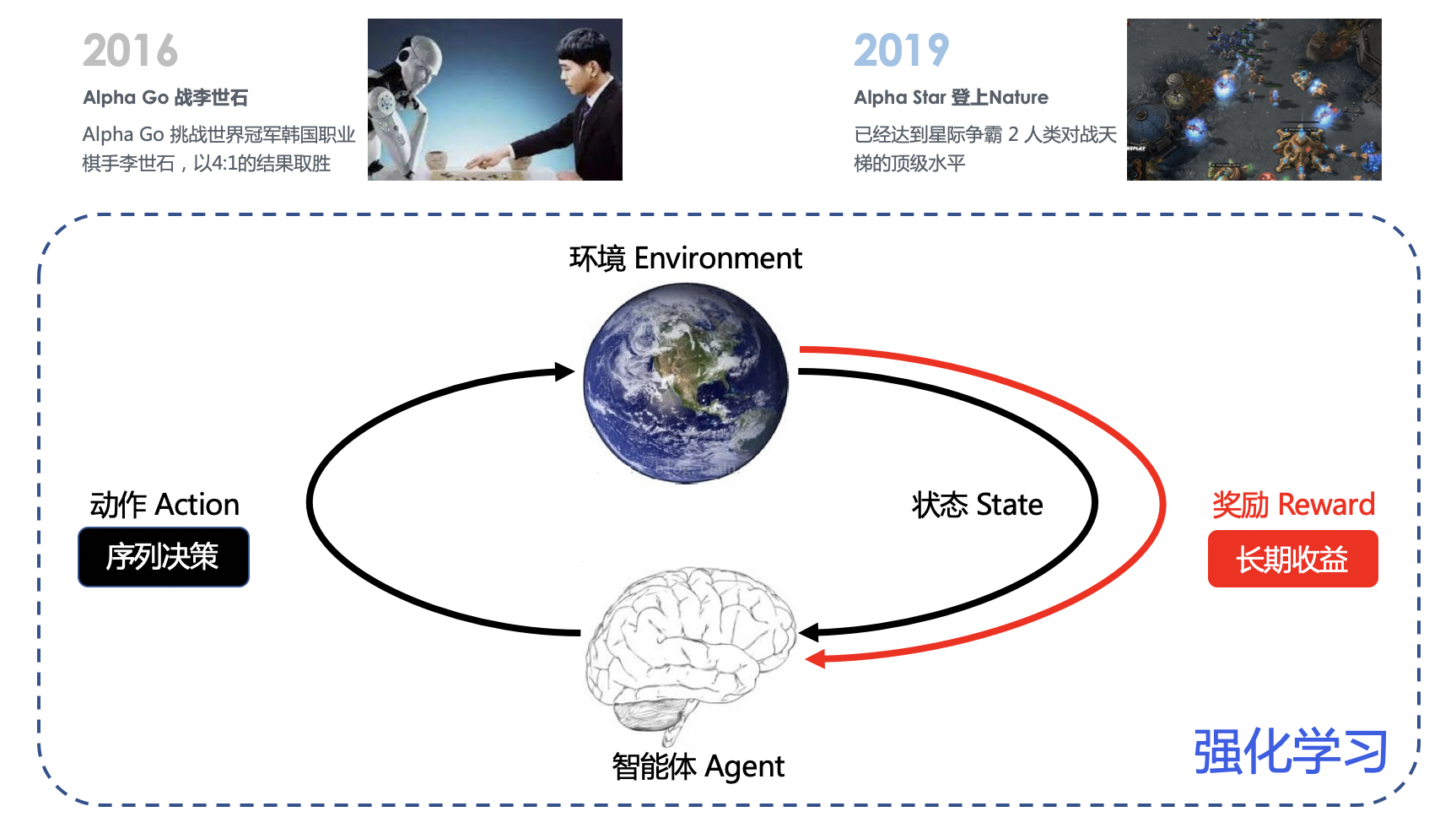
强化学习是一个非常吸引人的人工智能领域,2016年 Alpha Go在围棋领域挑战李世石,以几乎碾压的结果夺冠,引起了人们对于人工智能的广泛讨论。2019年Alpha Star横空出世,在复杂的星际争霸2游戏中达到能和人类顶级玩家PK的水平,登上Nature。这两次与人类顶级玩家的抗衡之战,背后的技术都是强化学习。强化学习是机器学习领域的一个分支,强调基于环境而行动,以取得最大化的长期利益。与监督学习、非监督学习不同,监督学习解决如分类、回归等感知和认知类的任务,而强化学习处理决策问题,着重于环境的交互、序列决策、和长期收益。强化学习与环境的交互模式可以抽象为:智能体Agent在环境Environment中学习,根绝环境的状态State,执行动作Action,并根据环境反馈的奖励Reward来指导输出更好的动作。
2. 强化学习能做什么?
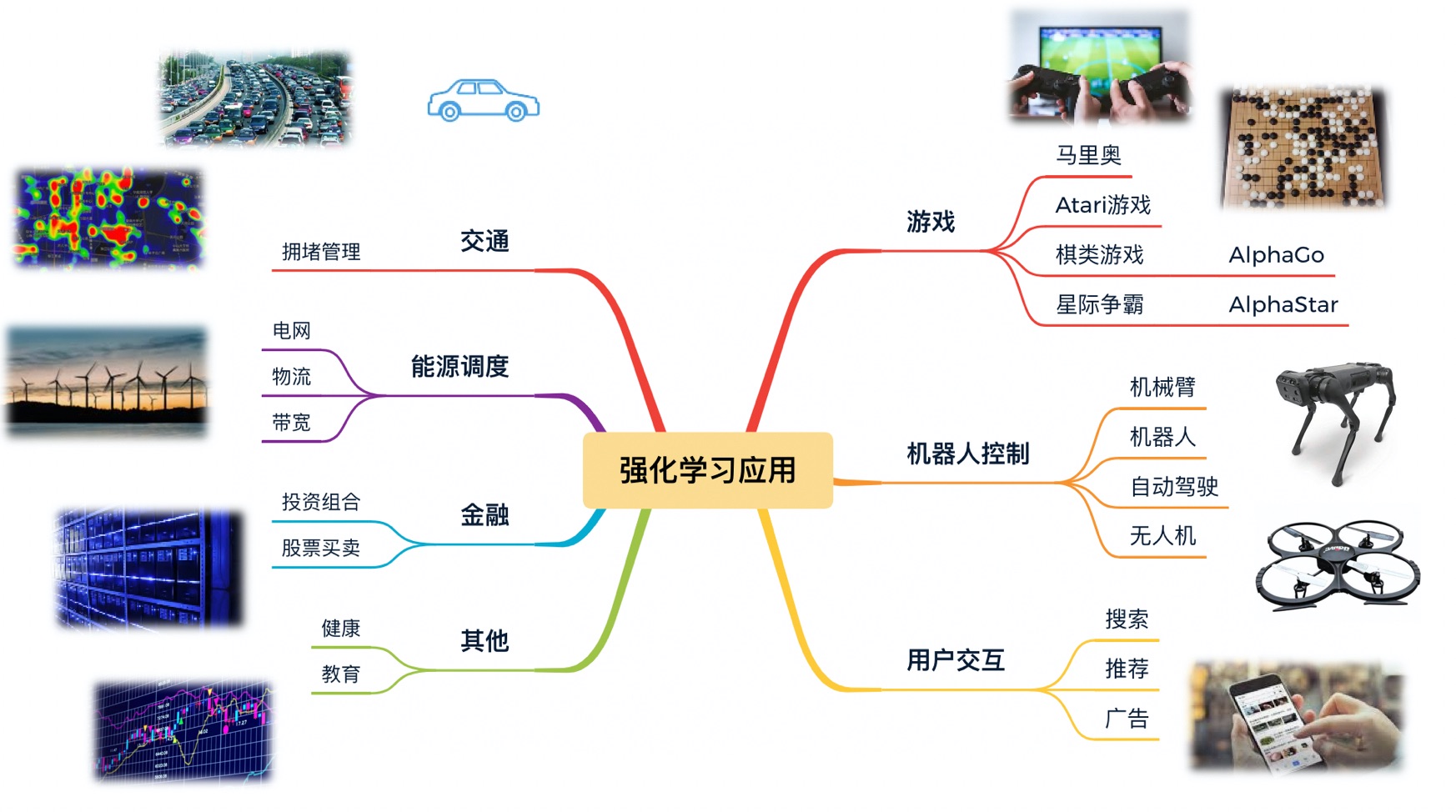
类似心理学中的巴普洛夫强化效应,强化学习采用一种更接近人类和动物习得技能的方式,在探索与利用中学到更优的策略规划与控制,能够最大化序列决策任务中的长期收益。强化学习在复杂环境中可以探索更多的状态空间和同时处理更多样化的动作组合,达到甚至超越人类能探索到的决策能力。因此强化学习的应用非常广泛,可应用于游戏、机器人控制、推荐、交通、能源、金融等等。
3. 现在是强化学习开启商用的时机吗?
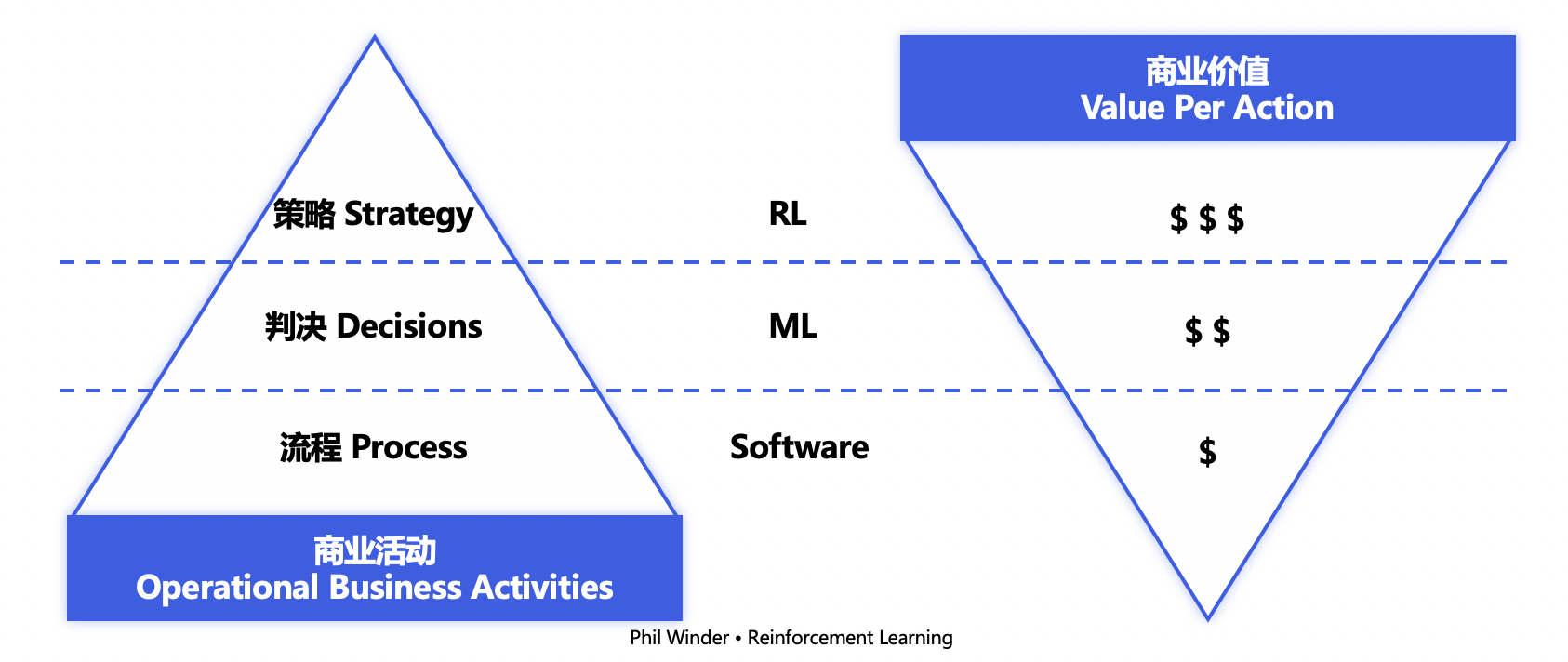
强化学习的应用,不是一件简单的事情。商业活动分为3个级别,底层流程性质的工作(诸如电脑连接打印机)可使用配置化的软件实现自动化,更复杂的判决类的工作(诸如根据人脸识别结果决定是否开门)可基于机器学习实现自动化判决,而策略层面的活动涉及长期收益的考虑,比如在下象棋场景需要不断打磨可以获胜的策略,或是在超市管理场景,管理者每天需要根据销售量与存货决定第二天应该补货的数量与种类组合,来最大化经营利润,这样的商业活动也需要有长期策略来指导行为。强化学习可以处理复杂、随机、长期动态变化的场景问题,商业价值极大,但难度与风险也高居首位。
近年来随着强化学习技术的不断发展和成熟,国内外工业界都已经开始布局相关的落地探索与应用,Indeed雇佣招聘网站于2020年的统计显示,强化学习相关的工作需求正在增长,在美国主要科技中心,强化学习与深度学习的工作岗位需求比例能达到1:9。此外,麦肯锡于今年4月发布了文章”It’s time for businesses to chart a course for reinforcement learning”,同月,哈佛商业评论也刊登了”Why AI That Teaches Itself to Achieve a Goal Is the Next Big Thing”,都释放了一种信号,使用强化学习去实现智能决策的时代,已经不再是遥不可及。
4. 目前什么条件下适合使用强化学习落地?
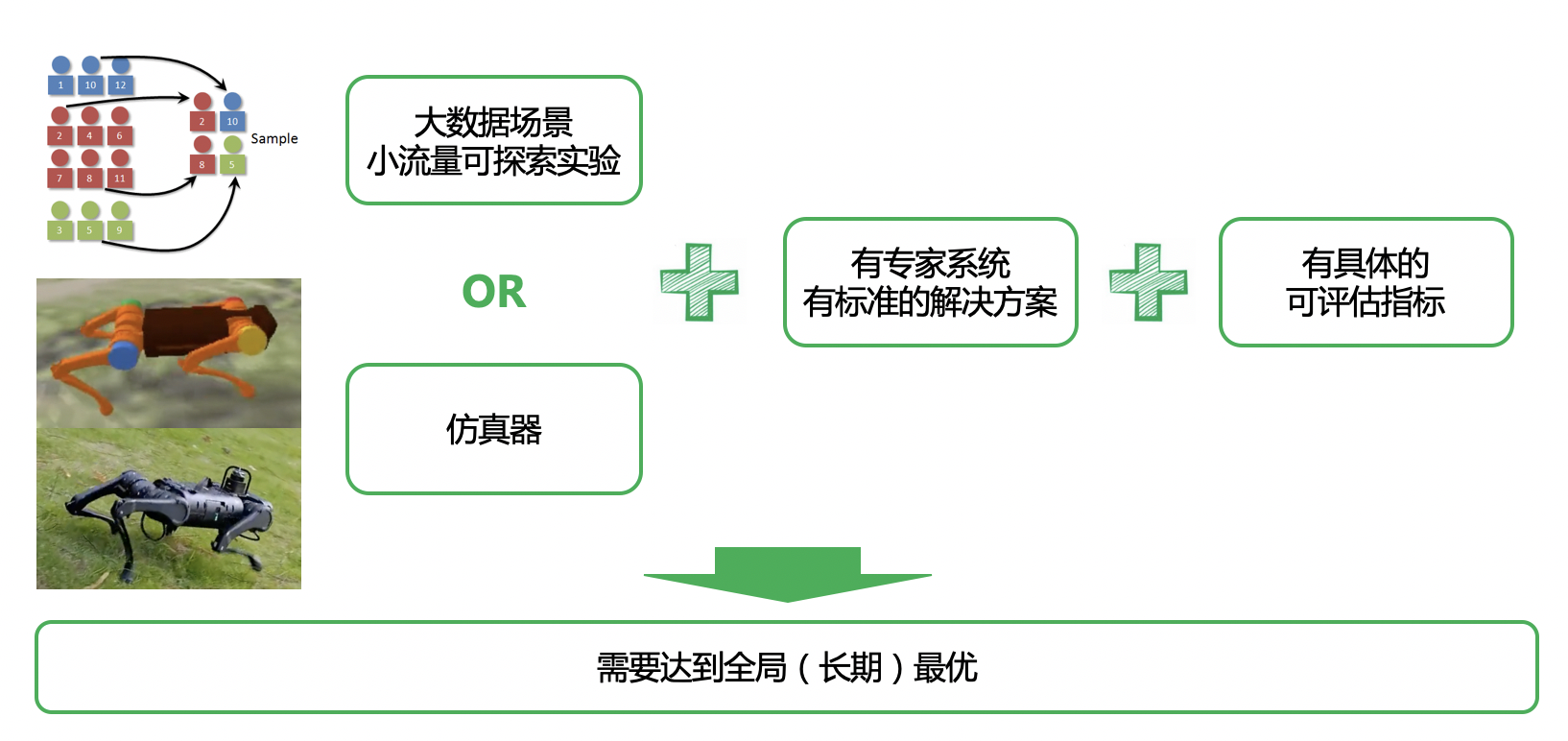
强化学习决策性能的关键除了算法之外,也取决于大量的试错探索。持续地探索更优的决策序列或动作组合,可以应对长期动态复杂的环境。强化学习的应用存在两个困难,一是训练数据量的需求大,例如2020年NeurIPS电网调度大赛中PARL团队的夺冠方案使用的训练数据约等于电网运行时长1万年的数据;二是探索风险高,在真实世界探索决策可能引发无人机炸机或电网崩溃等。目前PARL团队已落地并应用到现实环境中的强化学习场景包括两类,一类是探索成本较低的大数据场景,如公司内搜索、推荐、广告、地图业务,均有同分布的小流量可用于探索实验;第二类是具有和现实世界相差较小的仿真器,如PARL团队在四轴飞行器与四足机器人等真实机器中实践的技术创新与应用。此外,强化学习的落地更适合在一个具有专家系统或成熟解决方案的场景中,用于辅助或替代部分人工的决策行为,来优化提升性能上限。因为从零训练的成本过高,专家系统的存在有利于初始化强化学习模型和加速训练。最重要的一点是,落地场景需要有具体明确的评估指标,以便强化学习算法可以在奖励的引导下优化策略,最大化长期收益。
5. 目前PARL团队的强化学习应用与落地
PARL团队在公司内落地的强化学习业务场景包括搜索、广告、推荐、地图,这几大类均属于大数据流量的场景。PARL在2020年初始就已开源进化算法工具EvoKit,并在代码层面与业务部门合作,多次推全上线取得正收益。在ToB的产业化项目中主要涉及能源、交通、多智能体博弈三大领域的探索落地,这三大领域均有贴近现实的仿真器。为进一步缩短落地周期,我们构建了智能决策平台架构,以解决方案和平台机器设备销售的方式开发强化学习的商业价值。而两方面的业务落地,都离不开基于飞桨及PARL的底层核心技术研发和我们在强化学习智能决策与控制的创新能力。
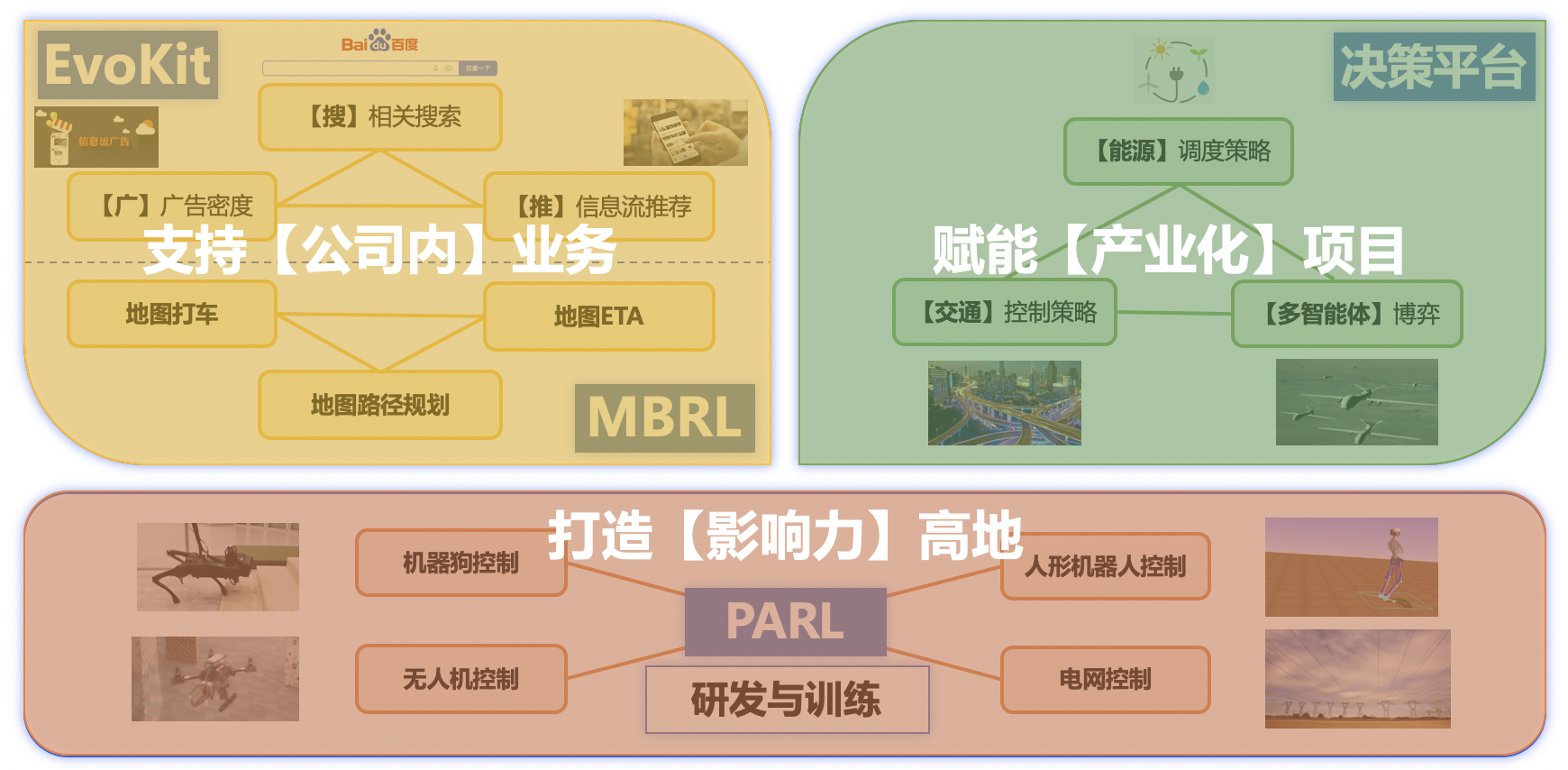
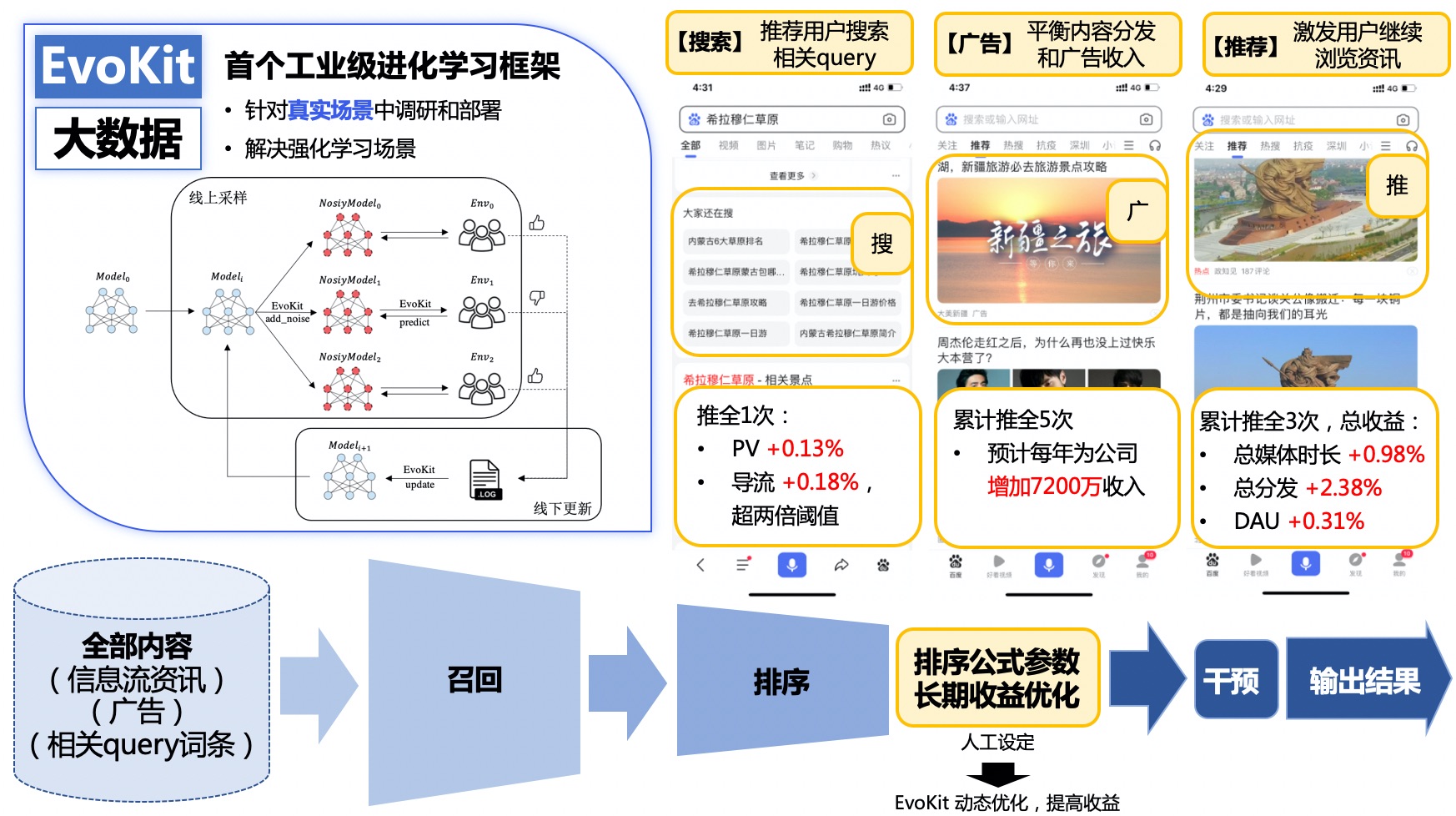
(1)EvoKit大规模进化算法工具库支持公司内业务落地
进化算法是一类同样可用于智能决策的强化学习的替代方案,巧妙地借鉴了自然界种群进化、物竞天择、适者生存的思想,通过参数扰动去实现强化学习里的探索功能,拿到更高收益的子代能生存下来迭代下一代,可用于强化学习建模的场景。
针对公司内搜索、广告、推荐等大数据大流量场景,PARL于2020年初发布了首个工业级进化学习框架EvoKit并在icode开源,支持大规模神经网络在真实业务场景中的调研、部署。相比较纯粹的强化学习算法,进化算法可以适应搜索、广告、推荐这类可能存在人工干预输出的黑盒场景(因业务链条过长而导致奖励目标与模型之间不可导,例如模型超参数的搜索、召回类别组合比例的优化等)。同时,搜广推这类大数据场景也避开了进化算法本身在样本稀疏场景中迭代效率低下的缺点,使得智能决策的应用与迭代更加稳定。EvoKit采用线上日志采样,离线更新模型的方式,可大大降低上线成本,提高调研迭代效率,支持同步异步参数共享,适应日志有延迟的场景,目前已在公司内上线多次。
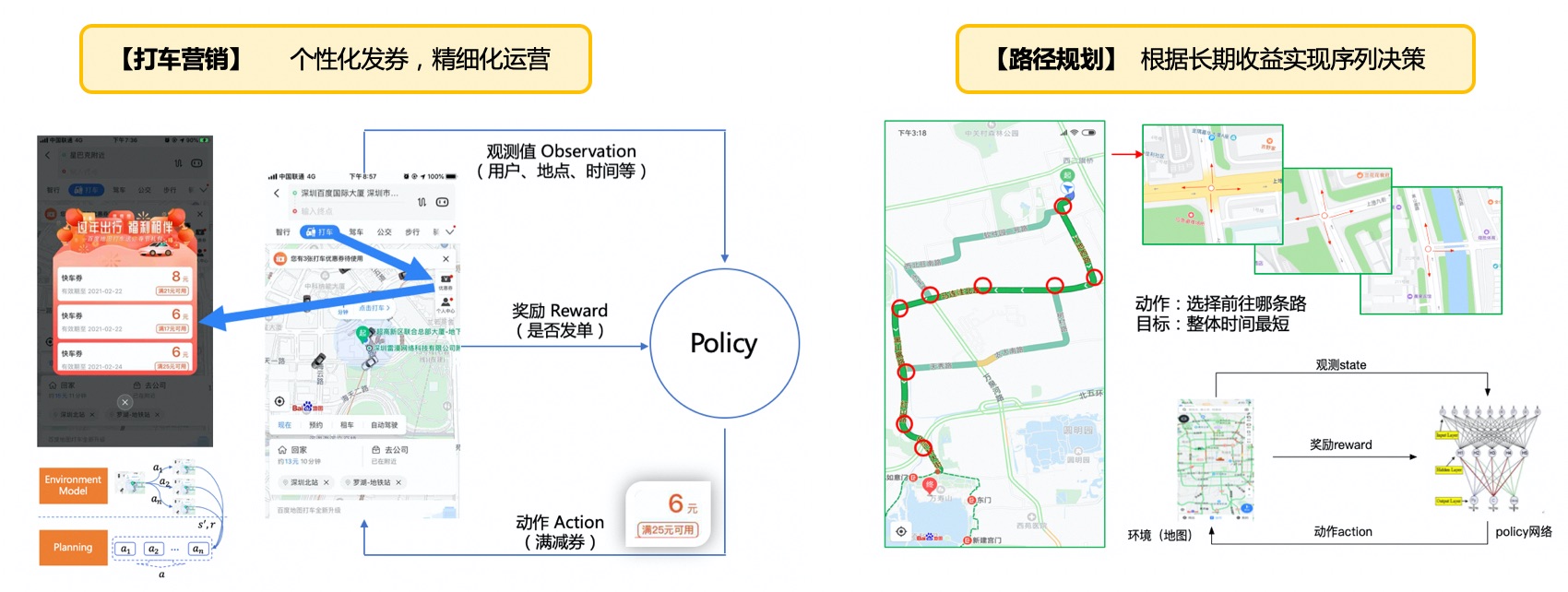
在公司内的地图打车营销场景,通过对用户的个性化建模和场景的动态建模,根据收益规划优化策略,可以探索更高性能和更细粒度的决策方案,有效提升运营补贴效率。此外,我们也在地图ETA和路径规划场景,通过图神经网络提升建模效率,实现了更精准的通行时长预估和更优的路径决策。
(2)智能决策平台赋能产业化项目
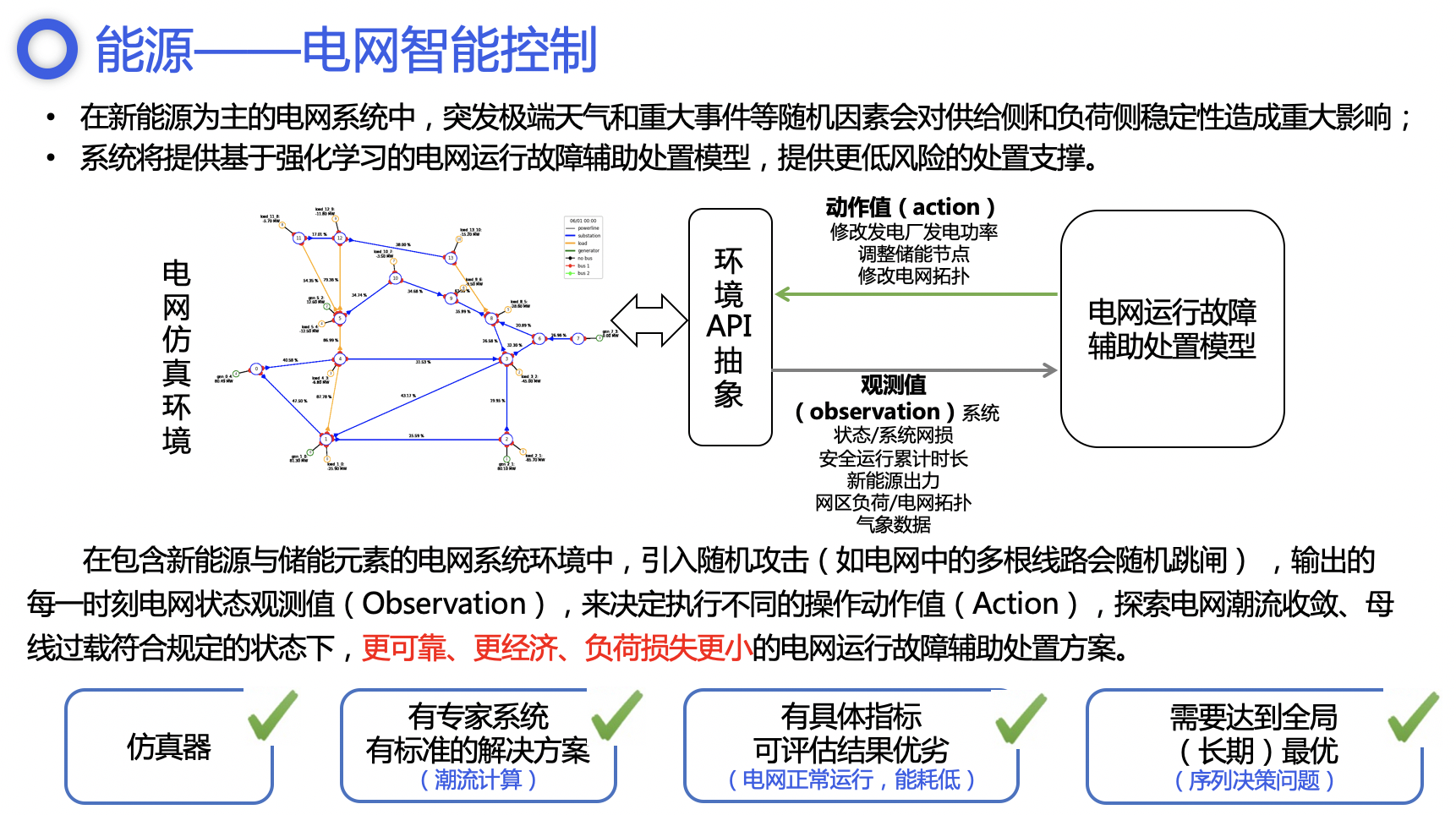
目前PARL团队已经进入能源、交通、多智能体博弈领域,探索强化学习在ToB业务的落地。以能源领域举例,在电网调度的问题上,国家的能源领域基于【碳中和】的目标正在发生一些转型和变革,最直接的体现在于新能源的地位从原来的补充能源的角色往主体能源方向转变。伴随着风能、太阳能等严重依赖气象条件的新能源供应的增加,能源供给的波动性和非持续性也正在增强,对电网调度的灵活性和适应性造成巨大挑战。这样的动态复杂场景很适合使用强化学习来持续长期优化。
PARL团队基于在NeurIPS 2020 电网调度大赛中双赛道冠军的技术能力,将AI技术应用于能源领域,助力实现AI在电力调度场景的智能决策应用。为此,我们针对性地投入和设计了针对智能电网的一系列调度解决方案,构建智慧决策中台,包含从最前端的电网仿真、电网运维的辅助决策系统和基于深度学习的模型的训练服务等等。
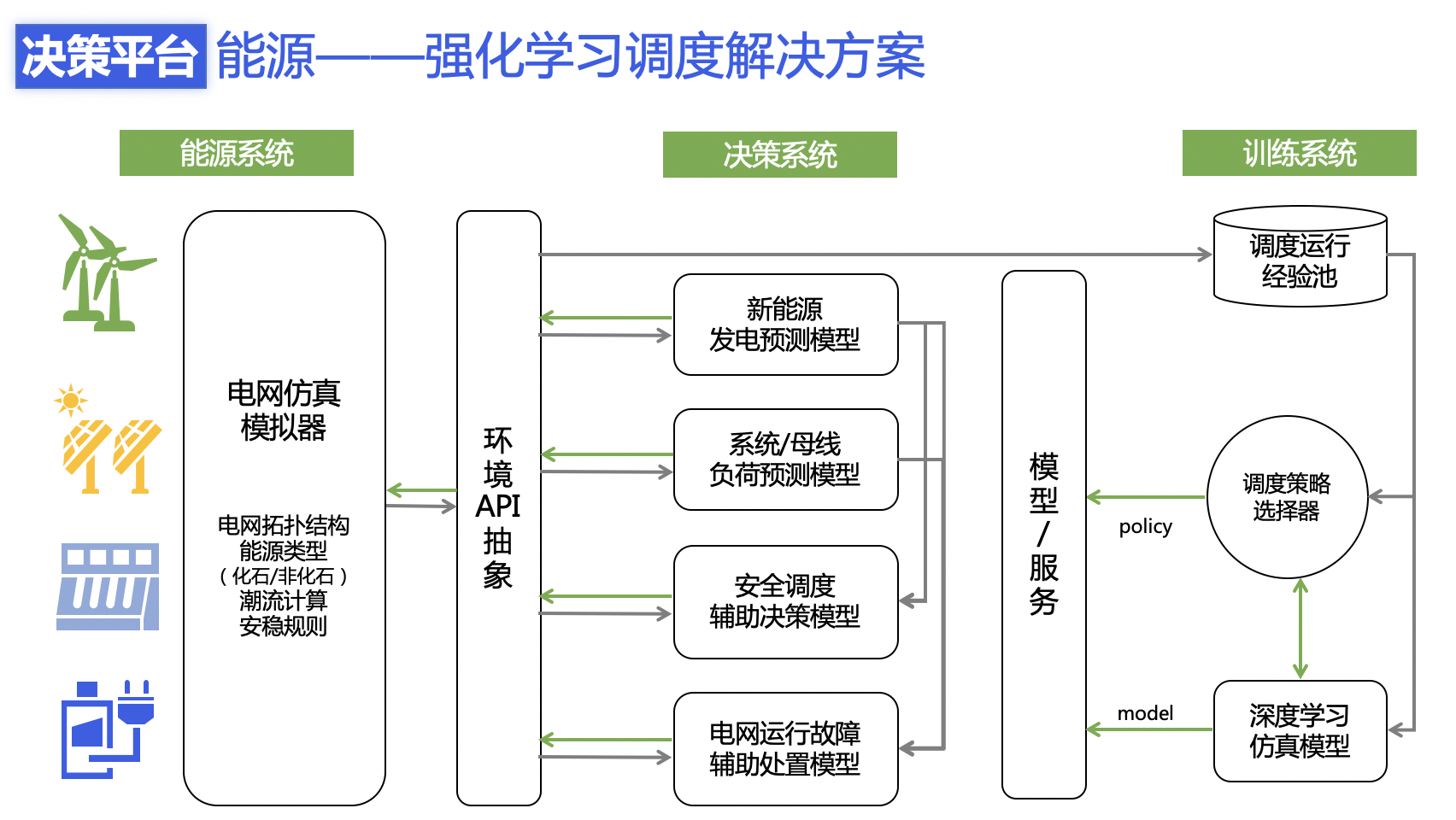
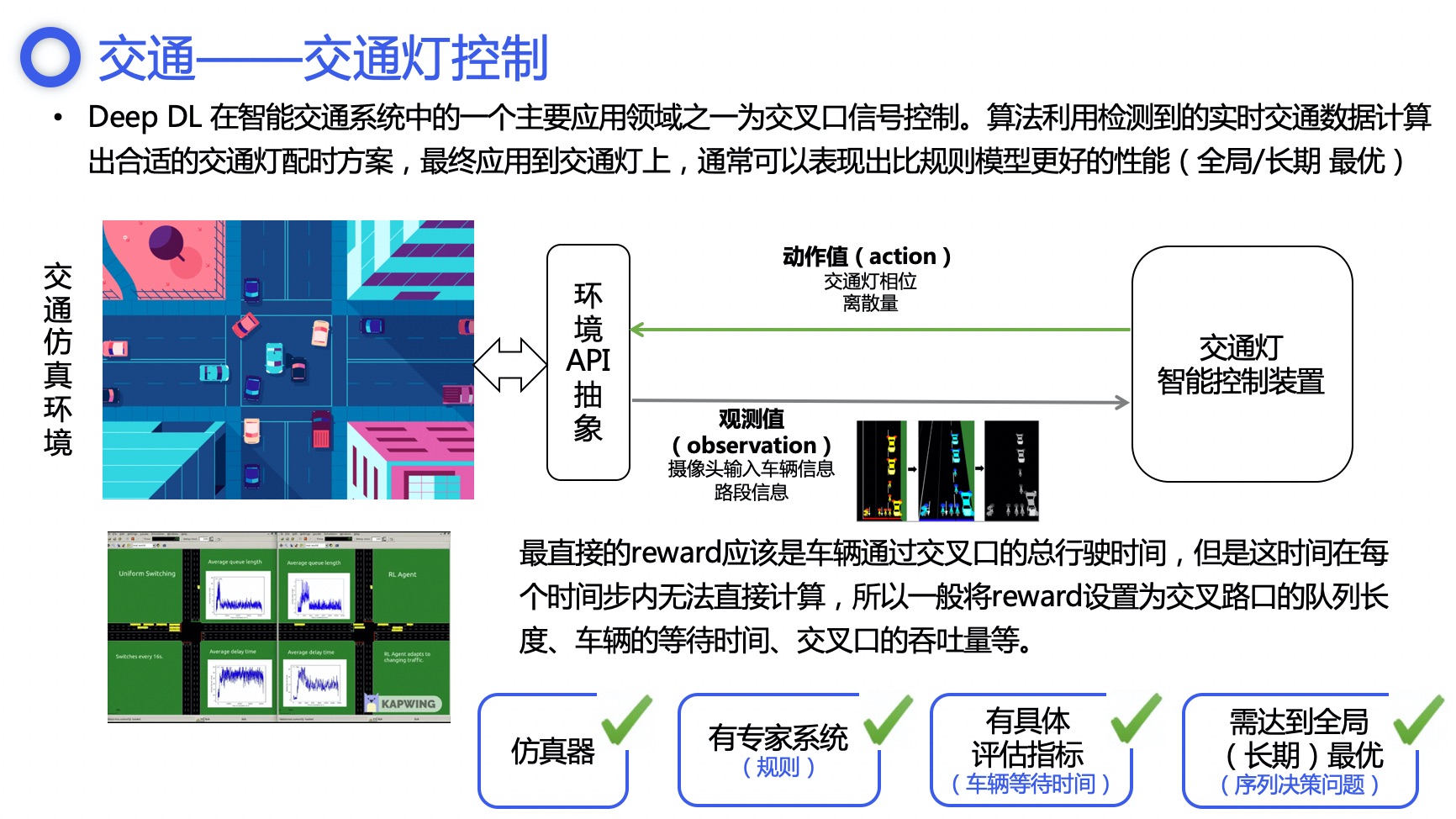
我们在智能决策平台中,抽象了目标系统(仿真环境或真实环境)、决策系统与训练系统,作为针对产业化客户定制解决方案时复用的一个通用框架,缩短定制周期,满足客户对于数据安全性、响应即时性的需求。电网调度、交通灯控制、多智能体对抗博弈等场景,均可类似上述调度解决方案,快速生成解决方案。
从强化学习,到智能决策,再到落地,不是一条容易走的路,但得益于PARL团队在强化学习领域的技术积累,也能走在这个商用探索领域的前沿。
(3)强化学习框架PARL建设与技术创新实战
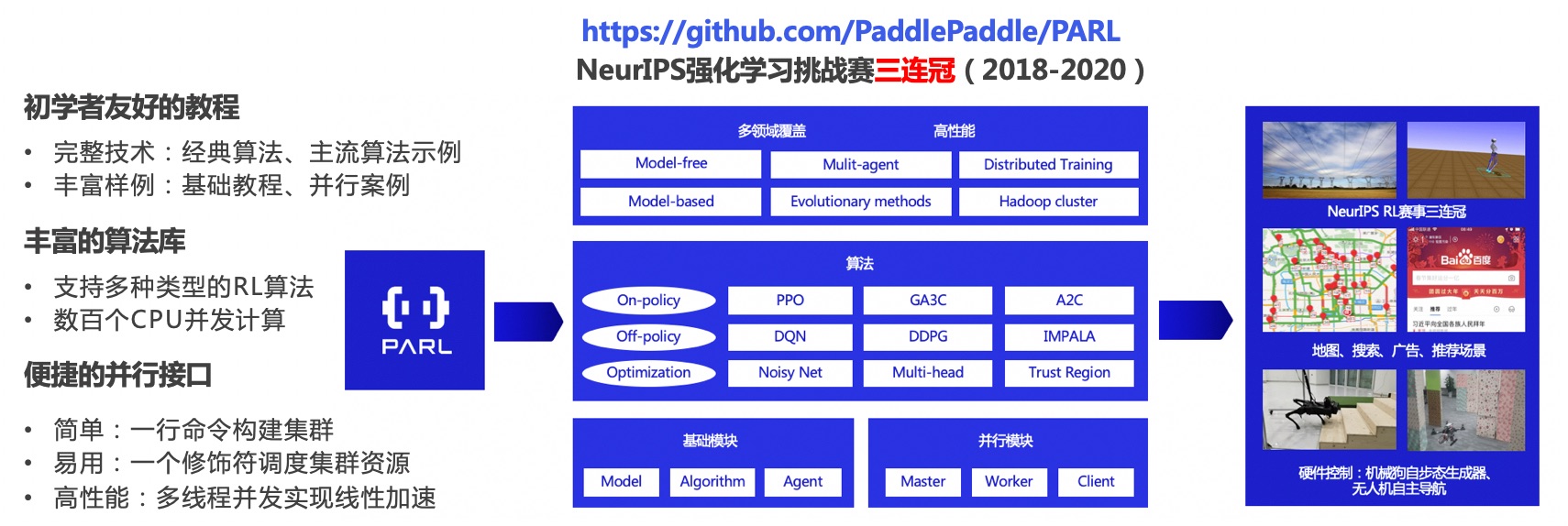
PARL团队在2019年开源了基于飞桨的强化学习框架库,用于快速支持和复现经典及前沿的强化学习算法,来满足不同任务的快速调研。PARL汇聚了百度多年来在强化学习领域的技术深耕和产品应用经验,开发者只需要通过数行代码和命令就能搭建起集群,并行调度资源,低成本地实现数百倍的性能加速,将电网合计总模拟时长一万多年的探索时长缩短为10个小时内训练完成。正是基于这样的能力,百度得以连续拿下了NeurIPS 2018年至2020年竞赛三连冠。此外,PARL也在强化学习未来可能的应用爆发点,即硬件控制的前沿领域持续耕作,包括四轴飞行器和四足机器人等的技术创新、论文研究、和真机实战。
6. 总结
本文通过介绍强化学习及其应用范围,分析了商业落地前景与落地条件。PARL团队从强化学习的框架建设与技术积累出发,通过技术创新打造世界领先的强化学习训练与应用能力,并且通过强化学习并行训练工具库PARL、进化算法工具库EvoKit与智能决策平台,降低强化学习的研究门槛和落地门槛,保持世界领先的技术能力,连续3年在NeurIPS竞赛上夺冠,赋能公司内搜索、广告、推荐、地图等多个业务场景,主动开拓探索能源、交通、多智能体等领域产业化商业落地场景,为公司最大化强化学习能力带来的价值与收益空间。
相关扩展阅读:
1. PARL:https://github.com/PaddlePaddle/PARL
2. EvoKit:http://news.family.baidu.com/newsDetail/205505
3. NeurIPS强化学习竞赛三连冠:https://www.jiqizhixin.com/articles/2020-11-17-6
4. 世界冠军带你从零实践强化学习:https://www.bilibili.com/video/BV1yv411i7xd
既然来了,说些什么?