空中悬停、翻滚转身、成功着陆,我用强化学习「回收」了SpaceX的火箭
我自己造了个「火箭」,还把它回收了。
SpaceX 作为一家太空探索技术公司是美国一家民营航天制造商和太空运输公司,由伊隆 · 马斯克于 2002 年创办,目标是降低太空运输的成本,并进行火星探索。SpaceX 成立近 20 年以来,吸引了无数的火箭爱好者。
对于个人来说,怎样实现这个火箭梦呢?据了解,SpaceX 制造一枚猎鹰 9 号的费用实际在 3040 万美元左右。对于个人来说,这个费用简直是天方夜谭,更别说涉及到的技术等问题了。
有困难就要想办法解决,作为 SpaceX 的超级粉丝,来自密歇根大学安娜堡分校的博士后研究员 Zhengxia Zou 也是个火箭迷,一直梦想拥有自己的火箭。最近,他研究了一个有趣的问题,即我们是否可以「建造」一个虚拟火箭,并通过强化学习解决火箭回收这个具有挑战性的问题。在实验中,Zou 尝试了关于火箭悬停和降落的两个任务。
由于这是 Zou 的第一个强化学习项目,包括环境、火箭动力学、RL 智能体等,Zou 表示尽量从头开始实现所有内容,并希望通过这些底层的编码,能够对强化学习有更深入的了解,包括基础算法,智能体与环境的交互,以及奖励的设计。

- 项目主页:https://jiupinjia.github.io/rocket-recycling/
- GitHub 地址:https://github.com/jiupinjia/rocket-recycling
不过对于这个项目,也有网友提出质疑:「如果我们能够用经典的控制方法来完成这项任务,为什么在 SpaceX 之前没有人做过呢?」对于这一质疑,有网友表示:「SpaceX 没有使用强化学习,他们使用论文《 Lossless Convexification of Nonconvex Control Bound and Pointing Constraints of the Soft Landing Optimal Control Problem 》中的方法来解决火箭着陆问题,性能优于 RL。」
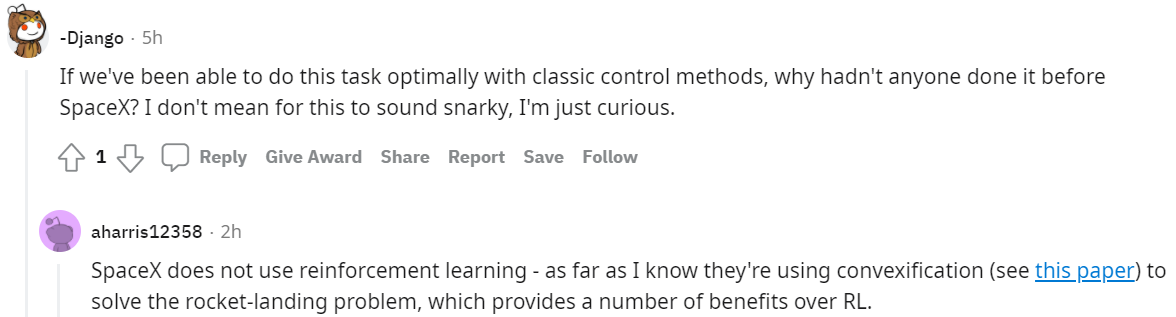
实现悬停和降落的智能体以及环境
Zou 尝试了悬停和降落这两个任务。如下图所示,火箭被简化成二维平面上的刚体,并且考虑了基本圆柱体动力学模型,并假设空气阻力与速度成正比。火箭底部安装了一个推力矢量发动机,该发动机为火箭提供不同方向的推力值 (0.2g, 1.0g, 2.0g)。喷嘴添加角速度约束,角速度最大旋转速度为 30 度 / 秒。
通过上述基本设置,动作空间(action space)被定义为发动机离散控制信号的集合,包括喷管的推力加速度和角速度。状态空间(state-space)由火箭位置、速度、角度、角速度、喷嘴角度和模拟时间组成。
对于着陆任务,Zou 遵循了 Starship SN10 的 Belly Flop 式降落(腹部朝下的翻转动作以实现空中转身)的基本参数。初始速度设置为 – 50m/s,火箭方向设置为 90 度(水平),着陆 burn height 设置为离地 500 米。

图源:https://twitter.com/thejackbeyer/status/1367364251233497095
奖励函数非常简单。
对于悬停任务:基于两个规则给出 step-reward:1)火箭与预定义目标点之间的距离——它们越近,分配的奖励越大;2)火箭机身的角度(尽量保持直立)。
对于着陆任务:观察看触地瞬间的速度和角度——当触地速度小于安全阈值并且角度接近 0 度(直立)时,则认为它是成功着陆并获得丰厚奖励。其余规则与悬停任务相同。
除了进行上述任务外,有网友表示,「希望将燃料的研究也纳入进来,燃料的有效使用是火箭技术的主要关注点,因此看到有效着陆奖励将是一件好事。开始时火箭有给定的燃料量,剩余的燃料量成为学习者的另一个信号——既用于控制也作为奖励。」

实现效果
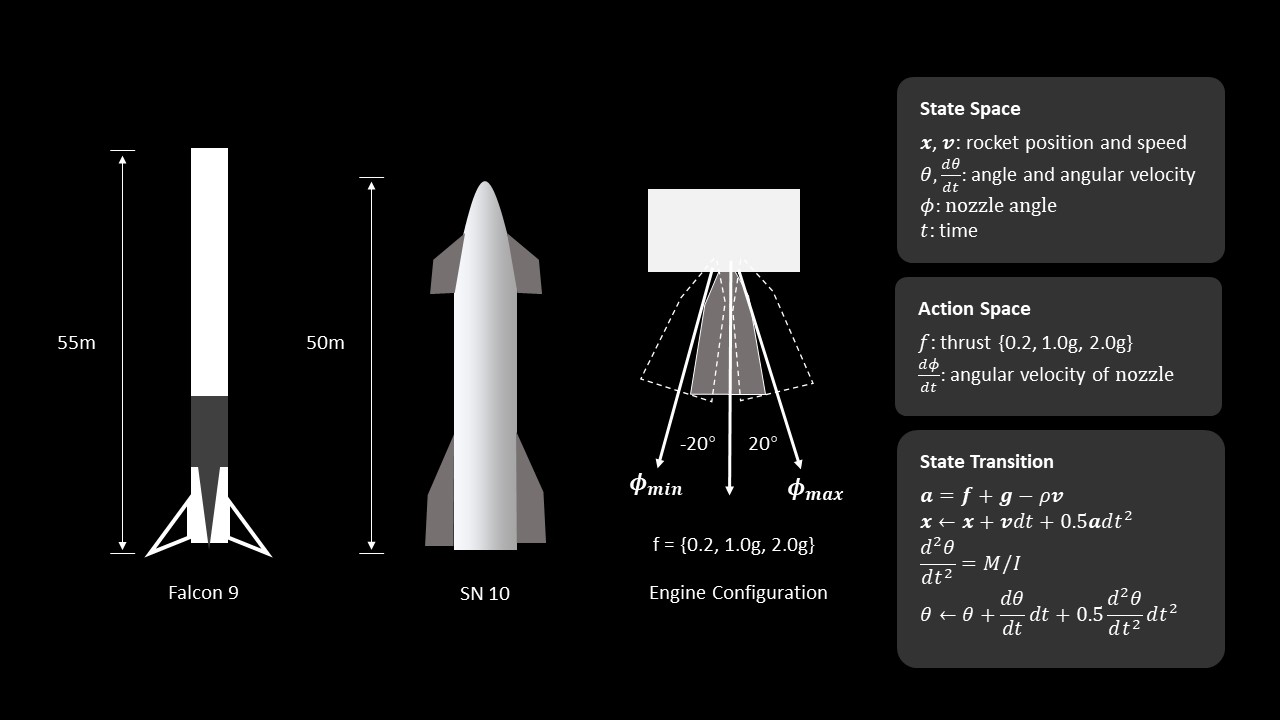
Zou 实现了上述环境,并且训练了一个基于策略的智能体(actor-critic)来解决这个问题。在超过 20,000 个训练 episodes 之后,episode 奖励最终收敛地非常好。
下图左为悬停任务上不同训练 episode 数量时的奖励;图右为着陆任务上不同 episode 数量时的奖励。
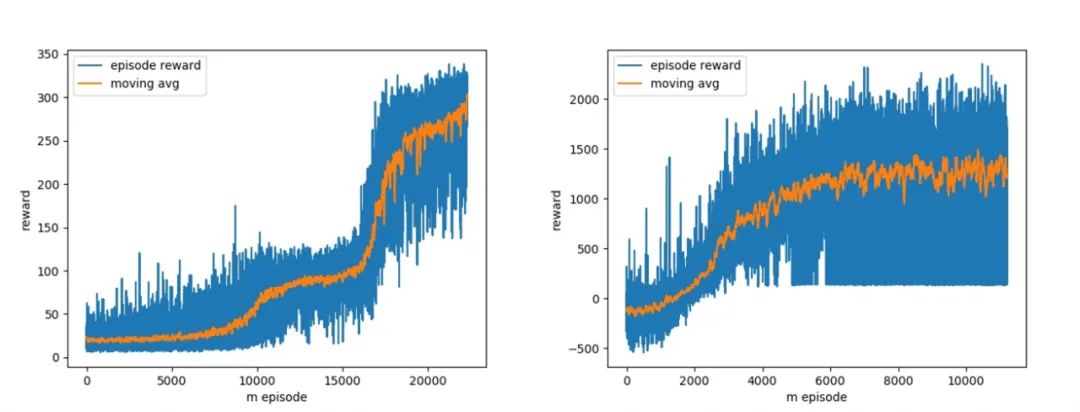
以下几个动图分别展示了经过不同训练 episode 后学习到的 RL 行为:
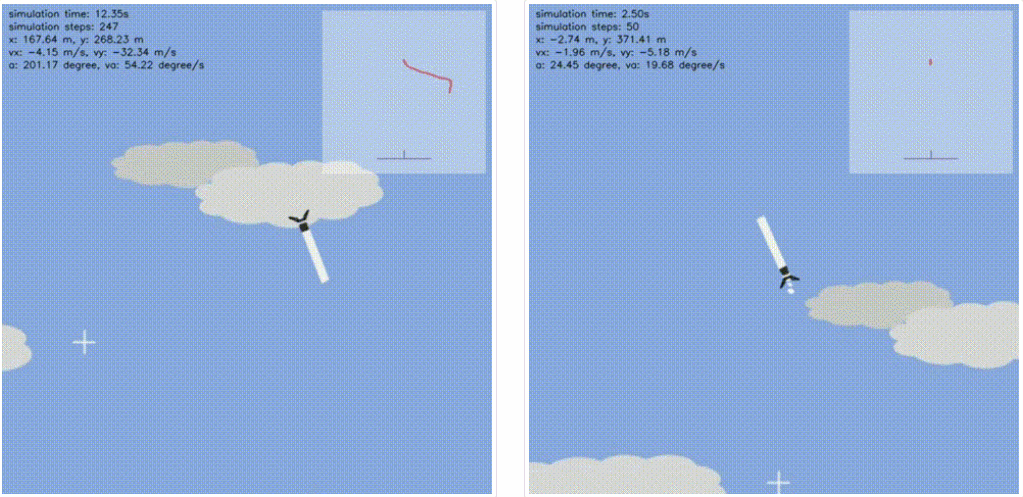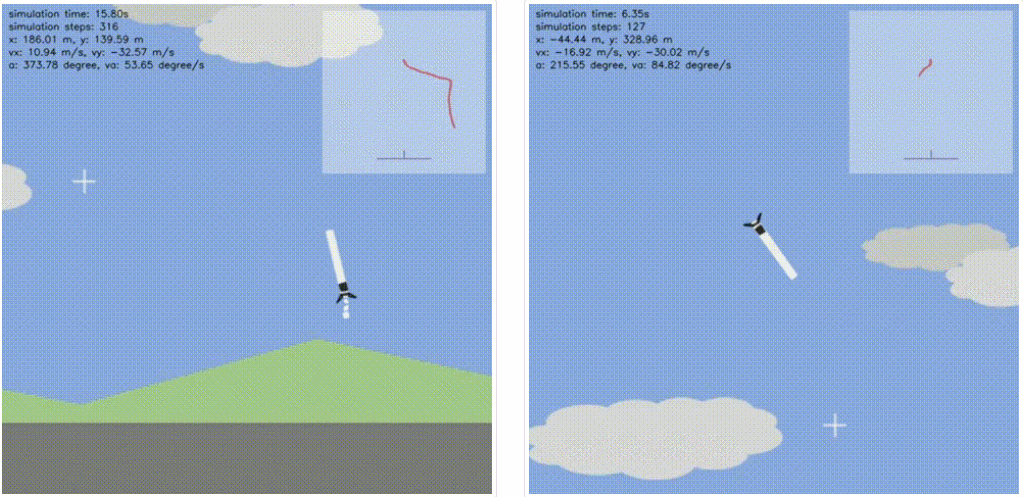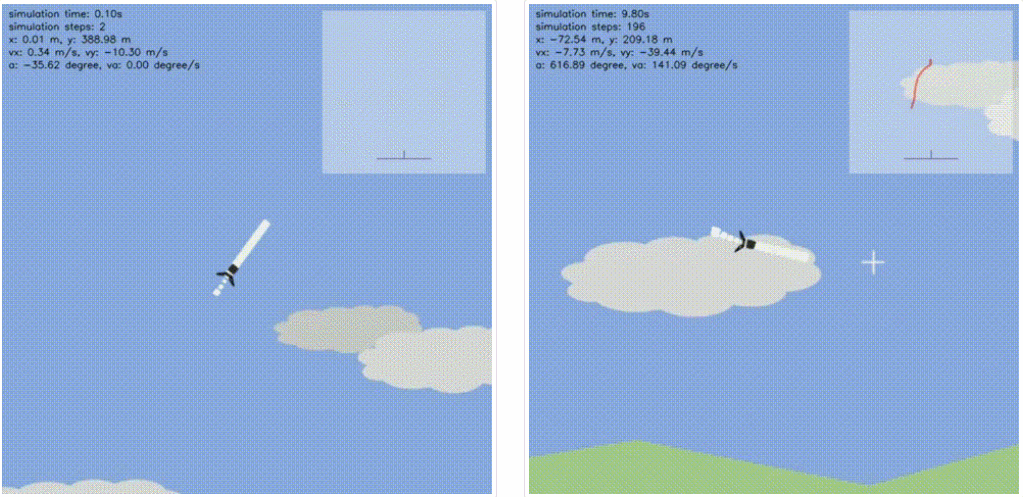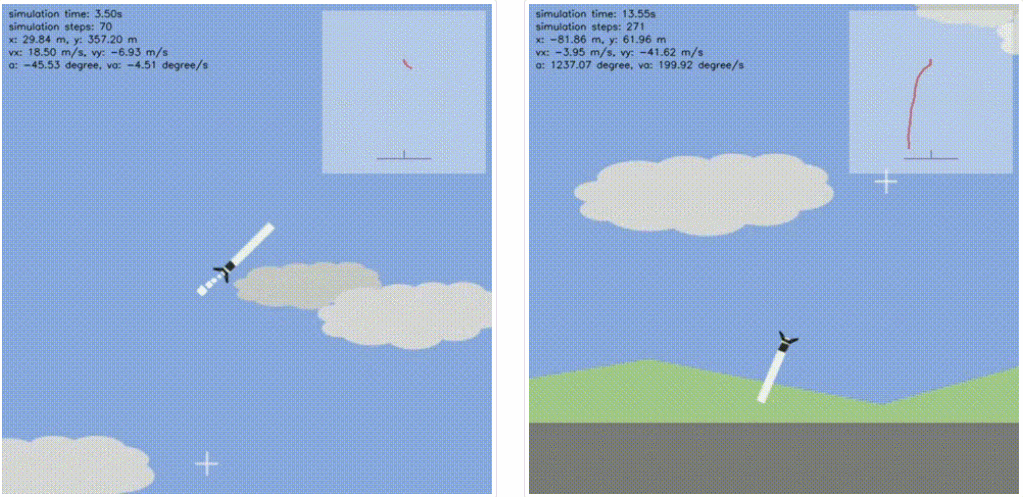
左:训练 episode 为 0(随机智能体),右:训练 episode 为 100。

左:训练 episode 为 2,000,右:训练 episode 为 10,000。

20,000 个训练 episode 之后,左:执行悬停任务的完全训练智能体,右:执行着陆任务的完全训练智能体。
与 SN10 着陆的动效对比
尽管环境和奖励的设置很简单,但经过训练的智能体已经很好地学会了 Belly Flop 式降落。
如下动图展示了真实的 Starship SN10 和从强化学习中学到的智能体在着陆时的比较:

智能体训练与测试
训练智能体,需要./example_train.py。
测试智能体的流程如下:
import torchfrom rocket import Rocketfrom policy import ActorCriticimport osimport glob# Decide which device we want to run ondevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")if __name__ == '__main__':task = 'hover' # 'hover' or 'landing'max_steps = 800ckpt_dir = glob.glob(os.path.join(task+'_ckpt', '*.pt'))[-1] # last ckptenv = Rocket(task=task, max_steps=max_steps)net = ActorCritic(input_dim=env.state_dims, output_dim=env.action_dims).to(device)if os.path.exists(ckpt_dir):checkpoint = torch.load(ckpt_dir)net.load_state_dict(checkpoint['model_G_state_dict'])state = env.reset()for step_id in range(max_steps):action, log_prob, value = net.get_action(state)state, reward, done, _ = env.step(action)env.render(window_name='test')if env.already_crash:break
作者简介
项目作者 Zhengxia Zou 现为密歇根大学安娜堡分校的博士后研究员,此前先后于 2013 年和 2018 年取得北京航空航天大学的学士和博士学位。他的主要研究兴趣包括计算机视觉及其在遥感、自动驾驶汽车和电子游戏等领域的相关应用。
谷歌学术主页:https://scholar.google.com/citations?user=DzwoyZsAAAAJ&hl=en
Zhengxia Zou 参与撰写的论文被 AAAI、CVPR、ICCV、IJCAI、ACM MM 等多个学术顶会接收。他还曾担任 NeurIPS、AAAI、ACCV 和 WACV 等多个学术会议的程序委员,以及 ICLR 会议及 IEEE Transactions on Image Processing 等多份期刊的审稿人。
机器之心此前报道过多篇他参与的研究,包括如下:
参考链接:
https://www.reddit.com/r/MachineLearning/comments/qt2tws/pr_rocketrecycling_with_reinforcement_learning/
原文:https://mp.weixin.qq.com/s/2MAiskAwlY9No5fL19-v5w
既然来了,说些什么?