模型的可解释性与可视化探索
1、当谈到模型可解释性时我们通常谈什么
1.1.人工智能在我们日常生活中扮演着越来越重要的角色。
随着AI解决方案在金融、监管、司法、医疗和教育等领域的广泛应用,如何提升对模型工作机理的直接理解,打开人工智能的黑盒子,就变得愈发重要。特别是在需要可靠性和安全性的高风险领域(例如医疗、运输等),以及具有重大经济影响的关键金融和监管领域(例如银行、保险、监管部门等),提高模型的透明度和可解释性,协助业务专家建立对模型的信任,已经成为机器学习系统解决方案是否最终被采用的前提。
模型可解释性的意义主要体现在建模前的知识发现,以及建模后的模型验证和诊断。模型可解释性作为知识发现的重要手段,可以被广泛地应用到数据挖掘领域,包括从海量数据中自动挖掘隐含的新知识、辅助机器学习模型提取数据映射模式,以及用于辅助分析与决策,从而提高人工分析和决策的效率等。比如,在智慧医疗领域,可将机器学习模型及可解释性技术应用于开发自动化智能诊断系统,辅助医护人员分析病人的医疗诊断数据,提升人工诊断效率;在化学领域,可将机器学习模型可解释性方法引入到分子模拟任务中,用于辅助分析分子结构与分子性质之间的关系。
模型的可解释性方法可以弥补传统模型验证方法的不足,从而消除模型在实际部署应用中的潜在风险。由于对模型工作机理没有掌握完全,模型可能会输出与业务目标不一致的结果,从而在特定文化语境和业务背景下导致很严重的后果。基于可解释的方法,可以明确模型的某个决定是如何做出的,令每个输出结果可回溯,从而使模型结果在业务场景下更可控。反面例子包括,在由三位机器人担任评委的第一届Beauty.AI选美大赛上,当评比结果公布后(最终脱颖而出的44位胜出者中,有37张面孔是白种人,而黄色人种和黑色人种分别只有6名和1名),很多选手抗议评委有种族歧视。虽然大赛组委会赛前曾表示肤色并不在机器人评分的范畴之中,但主办方对评比结果给出的解释是,机器人判断更深的肤色或不连续的光线有困难。
模型可解释性研究目前面临的挑战包括:
(i)定义模型的可解释性;
(ii)制定可解释性的任务,并为这些任务开发可解释的模型解决方案;
(iii)设计用于评估模型在可解释性任务中的性能方法。
本文从模型可解释性的定义出发,结合项目落地经验,从建模前的可解释性、可解释的模型以及建模后的可解释性几个方面,介绍在各个阶段模型可解释性结合业务目标的应用思路。
1.2.模型可解释性的呈现方式
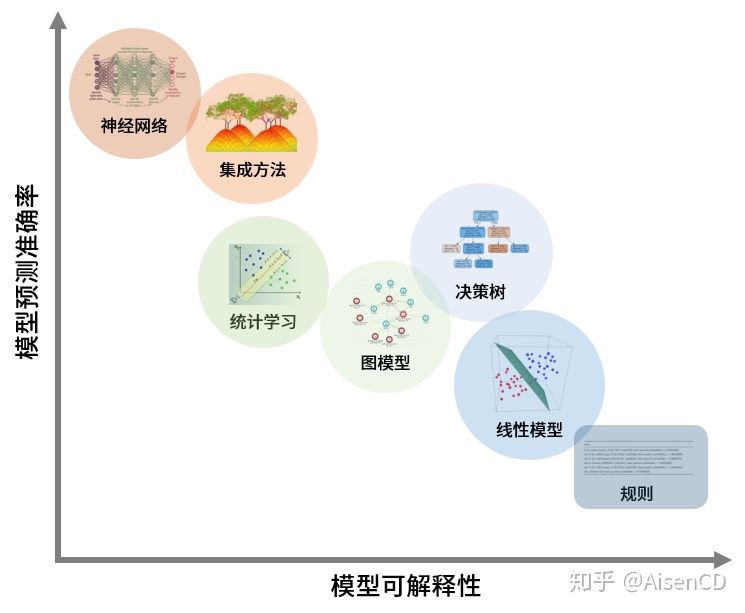
在实际机器学习建模任务中,建模人员需要在模型预测准确度与模型可解释性之间做权衡。简单模型(比如线性模型)虽然原理直观易理解,但常常因为拟合能力差,产生的结果偏差或者方差很高,导致准确率低而无法满足需要;而相对的,更为复杂的模型(集成模型、深度学习模型等)虽然拟合能力强,可以提高模型准确率,但通常是以牺牲模型的可解释性为代价的。
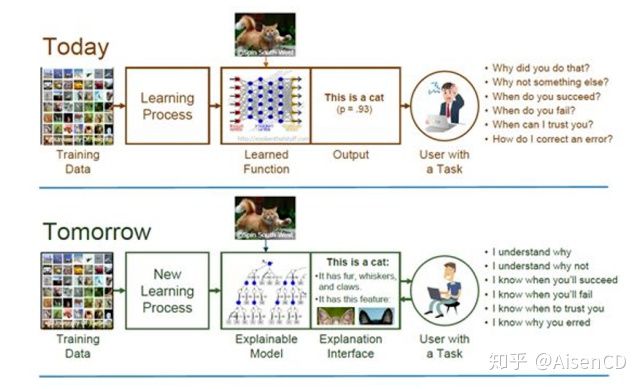
例如,在卷积神经网络训练时,模型方法往往是黑箱方法。首先基于训练集数据构建模型,在训练完成之后,模型可以对给定的输入图片进行评估,比如预测图片里面是不是一只猫,模型会输出一个概率值。通过这种方法,虽然模型可以实现很好的效果,却还是无法说明是如何做出决定的,或者哪些关键因素会影响模型做决定。但恰恰是这些解释模型运行机理的问题,会直接影响我们从主观上是否愿意真正地相信一个模型。在建模的时候,为了更充分地了解一个模型,我们希望一个卷积神经网络模型不仅仅可以检测到一只小猫,还希望模型可以明确提示,它用第一个filter监测到了猫的头,第二个filter检测到了猫的尾巴。因为被这些细节触发,所以模型判断出图像中有一只猫。反过来也一样,当我们知道猫的分类得分是0.7,我还希望模型给出猫的头部所贡献的分数(0.3),猫胡子所贡献的分数(0.2)。总的来说就是,在解释模型的这一条路上,模型输出的概率只是第一步,我们还希望知道,这个概率是如何被计算出来的,为什么模型对于某些类型的数据效果尤其好,但对另外一些类型的数据效果较为一般。还有当我们希望根据实际场景对模型进行调整的时候,模型可以提供一个系统的路径来实现。
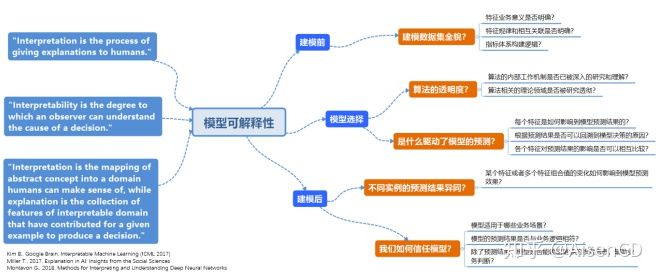
针对模型的解释性,Kim等学者给出了不同的定义,比如:
- “解释就是一个向人类说明的过程。”
也有从可回溯的角度来定义的,比如:
- “可解释性是一个观察者可以理解一个决定背后原因的程度。”
还有的定义把解释(interpretation)和说明(explanation)分开进行了表达:
- “解释,是将抽象概念映射到人可以理解的范畴;说明,是可解释范畴特征的汇总,基于给定的例子所做出的决策。”
这里也可以理解成,“解释”被看成是一个个人类基于经验和常识可以理解的概念,而“说明”被看成是通过对这些概念进行组合和加工,实现对输入信息的处理以及输出信息的创造。结合模型项目落地,模型可解释性在项目不同阶段对应着不同的问题。在建模前,主要处理的是对建模数据集全貌的探索,包括明确特征业务的意义、探索特征规律和相互关联、拓展指标体系等等。在有监督模型选择阶段,可解释性对应的问题包括算法本身的透明度以及模型预测驱动因素是否明确,比如算法的内部工作机制是否已被深入的研究和理解?算法相关的理论领域是否被研究透彻?每个特征是如何影响到模型预测结果的?是否可以根据预测结果回溯到模型决策的原因?各个特征对预测结果的影响重要性是否可以相互比较?建模后阶段模型可解释性对应的问题包括对比不同实例的预测结果异同,以及在各个应用场景下如何建立模型信任机制,具体要处理的问题包括:某个特征或者多个特征组合值的变化如何影响到模型预测效果?模型适用于哪些业务场景?模型的预测结果是否与业务逻辑相符?除了预测结果,模型是否能输出更多的线索信息,辅助业务判断等等。针对模型的可解释性定义,Kim给出了一组公式来概括建模前中后各阶段的任务:
- 建模前:
![[公式]](//www.mysecretrainbow.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif)
- 建模中:
- 建模后:
其中Q是一个解释性的评价方程,E是实现可解释性的具体方法。整个过程就是让我们寻求这样一种解释方法:使拥有特定经验的人群(Human),针对特定数据(Data)和特定任务(Task),获得对于特定模型(Model)最大程度的理解。
结合标准建模流程,本文分别对模型可解释性的以下三个部分做出介绍,包括:
(i)建模前的可解释与可视化探索,包括对数据本身可解释性的探索,以及基于统计分析的辅助决策;
(ii)可解释的模型,包括使用内在可解释的模型,以及开发具有可解释性的模型决策和结果输出策略;
(iii)建模后的模型可解释性与可视化,包括使用与模型无关的方法评估模型效果,以及探索特征对于最后结果的影响。
2、建模前的可解释与可视化探索
构建模型之前,首先要做的是探索数据集的全貌,包括每个特征维度,以及多个特征维度作为一个整体展现出的特定特点。具体方法包括数据描述方法和数理统计方法等,比如特征的分布分析、相关性分析、分组差异性分析、数据可视化等。这一节主要从无监督聚类、数据字形和数据降维的角度,来举例说明建模前这一阶段可以用到的一些思路。
2.1.低维数据基于聚类的可视化探索
利用聚类方法探索数据主要的优势包括:
(i)获取未标记的数据比需要人工干预标记的数据更容易;
(ii)无监督方法可以帮助定位对有监督分类有用的特征;
(iii)无监督机器学习可以发现数据中标签以外的各种未知模式。
Iris鸢尾属植物数据集是一个历史悠久经典的数据集,它首次出现在著名的英国统计学家和生物学家Ronald Fisher 1936年的论文《The use of multiple measurements in taxonomic problems》中。数据集包括了三类不同的鸢尾属植物(Setosa, Versicolour, Virginica),每类收集了50个样本,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度。模型可以通过这4个特征预测鸢尾花卉属于哪一鸢尾属品种。
利用K-Means聚类算法,基于花萼长度(Sepal length)、花瓣长度(Petal length)、花瓣宽度(Petal width)三个数据维度进行聚类,得到下方右图结果:
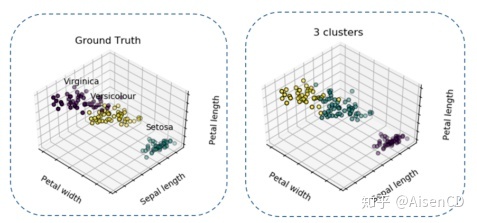
图中左边是样本真实的标签,右边是基于K-Means聚类的结果。比对无监督方法聚类结果和样本真实标签之后,发现Setosa类别的花瓣宽度(Petal width)与另外两类区分较明显,因此可以在没有标签的情况下被区分出来。
2.2.高维数据的可视化探索尝试
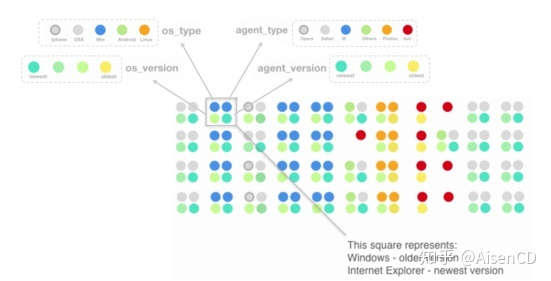
数据字形是可以用来表示多维数据的符号。根据数据集本身的特点,可以通过调整字形的颜色、形状或对齐方式来表示数据的不同特征或值。比如在图5中,彩色圆圈被用于表示不同类型不同版本的操作系统以及浏览器。每一组四个彩色圆圈记录了用户使用某个浏览器访问服务器的信息的行为。对于类型圆圈,颜色代表不同类型的操作系统或浏览器;对于版本圆圈,颜色代表新老版本,新版本偏绿,老版本偏黄。图中可以看到,Windows/Internet Explorer 组合在数据中较常见,OSX和Safari组合也很常见。另外使用Windows和Safari与使用较新的操作系统和浏览器版本相关,而Linux用户和bot与较旧的操作系统和浏览器版本相关。
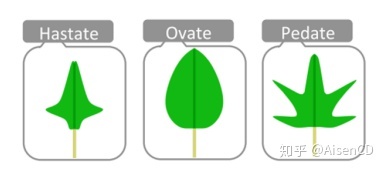
除了彩色圆圈组合以外,其他的元素也可以通过数据字形的方式描绘不同维度的信息,比如树叶。花萼与花瓣的长度和宽度可以作为参数对树叶字形的外观进行调整。将数据字形与树状图结合,再使用层次聚类的方法对Iris数据集中部分样本进行聚类,可以得到下图效果。
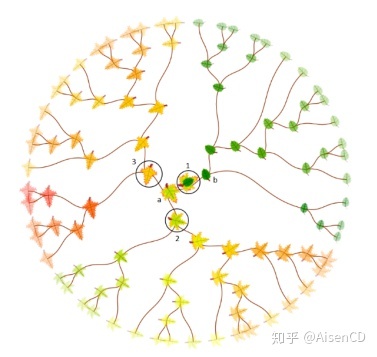
叶子字形可用于对层次聚类结构中的各个样本进行可视化描述。当接近终端叶子节点时,叶子字形的视觉结构会变得越来越精确和稳定。
2.3.高维数据的降维处理
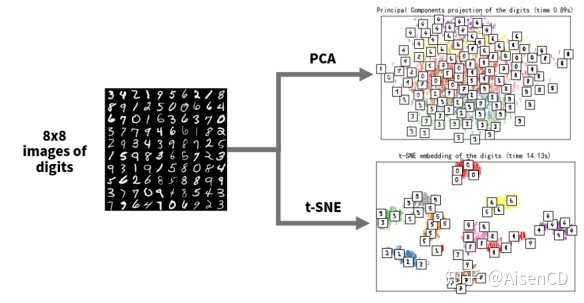
降维方法可以将多维数据映射到适合人类观察的二维或三维,获取数据中的隐藏模式,适用于建模前的探索性数据分析。降维方法输出的结果,也可以进一步用作分类和聚类算法的输入参数。下图中,输入都是8×8像素的图像,共有64个维度,每个维度都包含一个特定像素的值。分别基于线性PCA方法和非线性t-SNE方法对数据集进行降维处理。从右边降维结果看到,大多数样本可以很好地区分开,并与各自的数字分组在一起(t-SNE效果更好一些)。基于降维方法探索数据集特点全貌后,可以使用聚类算法等方式,来挑选单独的聚类或分配标签,作为进一步分析的起点。
3、可解释的模型
3.1.传统机器学习方法
在经典机器学习算法中,各类模型从不同角度提供了解释性,包括线性模型、决策树模型、朴素贝叶斯模型等等。在线性回归模型中,特征权重的大小和方向可以直接反映其对预测效果的影响。数值特征可以解释为:将数值特征增加一个单位,模型会根据其权重改变预测结果的大小。分类特征可以解释为:当特征值从参照类改变为其他类时,预测结果会根据类别的权重而改变的程度。对特征进行标准化处理后,截距可以反映出当所有特征都处于其均值时,模型对于实例的预测结果。
逻辑回归中权重的解释不同于线性回归,权重不再线性地影响概率,而是变为影响几率,即特定事件发生的概率除以不发生的概率。对于数值特征,如果将特征 ![[公式]](http://www.mysecretrainbow.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif) 增加⼀个单位,则可以解释为模型预测的几率将乘以因子 ,其中 为特征系数。分类特征基于one-hot编码思路可以解释为当特征从参照类别更改为其他类别时,模型预测的几率将乘以因子。
增加⼀个单位,则可以解释为模型预测的几率将乘以因子 ,其中 为特征系数。分类特征基于one-hot编码思路可以解释为当特征从参照类别更改为其他类别时,模型预测的几率将乘以因子。
决策树模型输出结果中,每一条从根节点到不同叶子节点的路径都代表着一个决策规则,因而每一棵决策树都可以被转化为一个具有分支判断结构的决策规则系统。
朴素贝叶斯模型,根据条件独立性的假设,决策过程可转化为类概率乘以给定类条件下每个特征的概率,从而计算每个特征值对最终分类结果的贡献程度。
3.2.集成模型
解释基于规则的复杂模型时,可以通过提取和融合决策规则的方法进行,比如对于深度很深的决策树或者树集成模型(如随机森林等),可以通过如下几个步骤构建决策规则学习器:
1)从集成树模型中每棵树从根节点到叶子节点的每一条路径中提取决策规则,并对提取的规则进行组合;
2)对组合后规则基于出现的频率、误差、复杂度等评估指标进行排序;
3)基于排序评估结果,对规则中的冗余项,以及初始规则中区分度不强的区间进行剪枝;
4)选择一组相关的非冗余规则来构建一个可解释的规则学习器,用于决策和解释。例如由Ando Saabas开发完成的随机森林解释python框架treeinterpreter,用于描绘特征值变化对模型预测贡献的变化,比如左下图呈现递增趋势,增加的shell weight对应于更高的贡献值;或如右图展示出的非单调趋势。
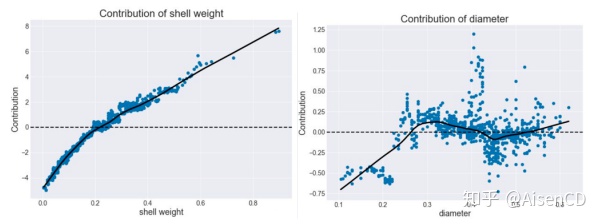
随机森林解释python框架treeinterpreter输出结果
3.3神经网络方法
深度神经网络被认为是最复杂的黑盒模型之一。随着算力的不断增强,网络结构越来越复杂,参数空间越来越庞大(参数空间可能包含上千亿个参数,比如OpenAI出品的1700亿参数的GPT-3模型),深度神经网络模型的预测能力也变得越来越强,甚至在很多特定任务上的表现已经远超人类。但与此同时,理解这些模型,却也变得越来越难。
从神经网络自身结构出发对模型可解释性的探索,很多是从注意力模型出发进行的。注意力模型旨在揭示网络在决策时关注的输入部分,具体的例子如类激活图(Class Activation Maps)。虽然,基于注意力的模型能输出模型关注的是输入信息的哪一部分,但不能揭示为什么会关注这一部分。对此,Chen等学者提出了一种类似于人类解释复杂特征的模型可解释方法(ProtoPNet),即专注于复杂特征的各个部分,并将它们与给定的人类能理解的“原型特征”进行比较。比如,放射科医生将X射线扫描中的可疑肿瘤与原型肿瘤图像进行比较以诊断癌症;再比如人们对鸟类做分类时,会比较鸟喙是什么样子的,鸟爪是什么样子的,羽毛是什么样子的,翅膀是什么样子的,之后再把这几个特征组合起来,去判断属于什么鸟类。

ProtoPNet模型效果
上图中的第一列为测试照片,其中圈出来的部分为典型区域特征;第二列和第三列表示的是训练图片中的原型;第四列为“激活图”,用于显示测试图像中的原型所在的显著性位置。如上图例子所示,为什么ProtoPNet模型会将左图给定的鸟归类为红腹啄木鸟(red-bellied woodpecker)呢?模型会将给定图片中的区域特征与每一个通过训练提取的“原型特征”进行比较,来找到给定图片属于红腹啄木鸟的证据。通过第四列“激活图”可以看到,红腹啄木鸟类的第一个原型在测试鸟的头上激活最多,而第二个原型在鸟翼上激活得最多。在这种情况下,模型发现给定图片中鸟头区域和红腹啄木鸟的原型头(相似度为6.499)之间,以及鸟翼和原型鸟翼之间都具有高度相似性得分(4.392)。对这些相似度分数进行加权和求和,可以得出属于该类别的鸟类的最终分数。通过通过对其他所有鸟类[比如右图红冠啄木鸟(red-cockaded woodpecker)]进行相似推理过程,模型最终将给定图片中的鸟归类为红腹啄木鸟。
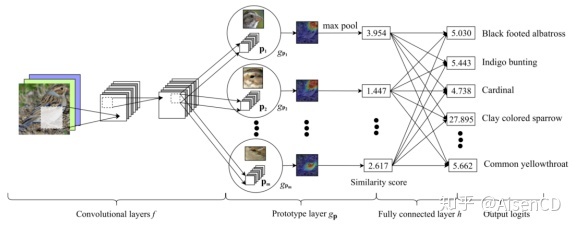
ProtoPNet模型推理过程
如图所示,ProtoPNet网络主要由卷积网络(conolutional layer),原型层(prototype layer)以及一个全连接层(fully connected layer)组成。卷积网络部分根据常见的特征提取作用构建,其中网络可以是VGG、ResNet等经典结构,并且基于ImageNet的预训练参数进行初始化。在原型层部分,网络学习了m个原型,不同的原型可以表示不同的典型部位。这些原型以卷积层的特征图为输入,经过 m 组的卷积网络得到推理图片不同区域分块patch的原型激活值(计算原型和卷积输出之间的L2距离,并将这个距离转换为相似度分数)。这种由分数表示的激活图表明了图像中的典型部分的显著强度。在全连接层,经过前面的提取特征及相似度分数计算后,m个相似度分数通过全连接层,最终得到经过softmax之后得到分类预测概率。
在模型训练阶段,我们的目标是学习到一个原型空间。在这个空间中,根据不同图像中相似的“原型区域”,可以对区分度最高的图像分块进行聚类(基于L2距离),最终使不同的原型可以被很好地分离。为了能够将原型可视化,我们将每个原型投影到与该原型同一类中最近的一个训练样本图像分块上。这样,我们就可以在概念上将每个原型等同于一个训练图像块。
4、建模后的模型可解释性与可视化
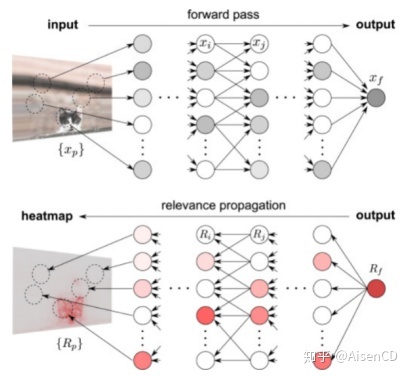
建模后的模型可解释性指的是在模型训练完成后,事后尝试解释这个模型的工作原理。基本思路是,我们把训练完成的模型看成是一个黑盒子,不去对模型本身进行显式地拆解,而是基于假设和输入的数据去观察这个模型,再去推测这个模型可能是怎么工作的。这种做法的好处是跟模型无关,适合于任意训练完成的模型。建模后的模型可解释性包括敏感性分析、局部近似,以及基于神经网络结构和基于反向传播思路进行解释的方法等。
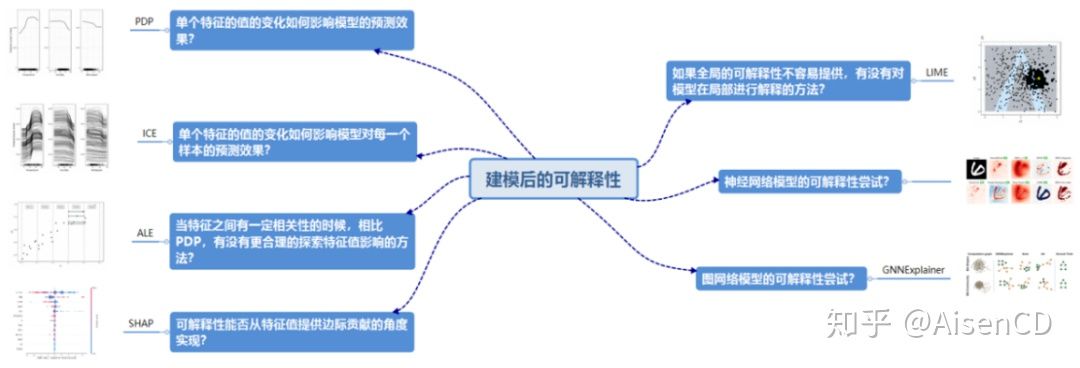
建模后可解释性实现思路
敏感性分析是指在给定假设下研究自变量变化对某一特定的因变量影响程度的一种方法,其核心思想是通过逐一改变自变量的值来解释因变量受自变量变化影响大小的规律,具体方法包括部分相关图(Partial Dependence Plot)、个体条件期望(Individual Conditional Expectation)、累积局部效应图(Accumulated Local Effects Plot)、SHAP方法(SHapley Additive exPlanations)。对应解决的问题包括:单个特征的值的变化如何影响模型的预测效果?单个特征的值的变化如何影响模型对每一个样本的预测效果?当特征之间有一定相关性的时候,相比PDP,有没有更合理的探索特征值影响的方法?可解释性能否从特征值提供边际贡献的角度实现?
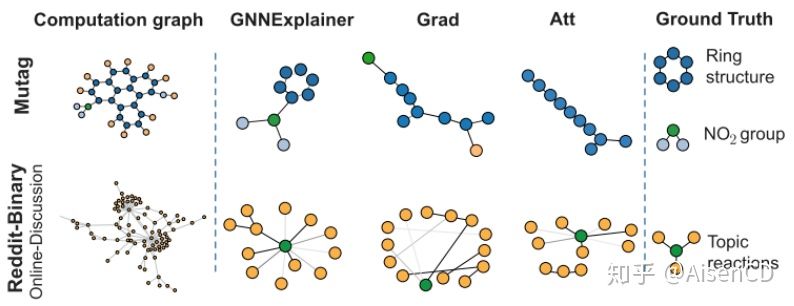
关联网络模型的可解释性
关联网络模型也可以基于敏感性分析的思路对节点或者关系重要性进行评估,基于GNNExplainer的思路,当把节点从关联网络子图中移除后,预测结果如果降低很多,那么我们可以认为此节点在子图中很重要。类似地,当把关系边从关联网络子图中移除后,如果模型预测结果降低很多,那么我们也可以认为这条关系边对于子图的预测很重要。
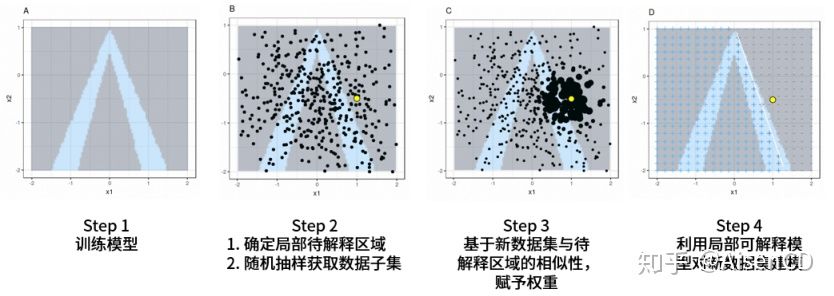
局部代理方法,比如LIME模型,对模型进行解释的基本思路是:选取目标局部区域实例,并基于其邻域内样本构建新的建模数据集。基于新数据集可以训练一个易于解释模型(比如线性回归),然后基于该易解释模型为目标局部区域实例提供决策依据。
对于深度神经网络,解释方法的核心思想之一是利用反向的传播机制,将模型的决策信号逐层反向传播到模型的输入,用于推导输入样本的特征重要性。
4.1.部分相关图与个体条件期望图
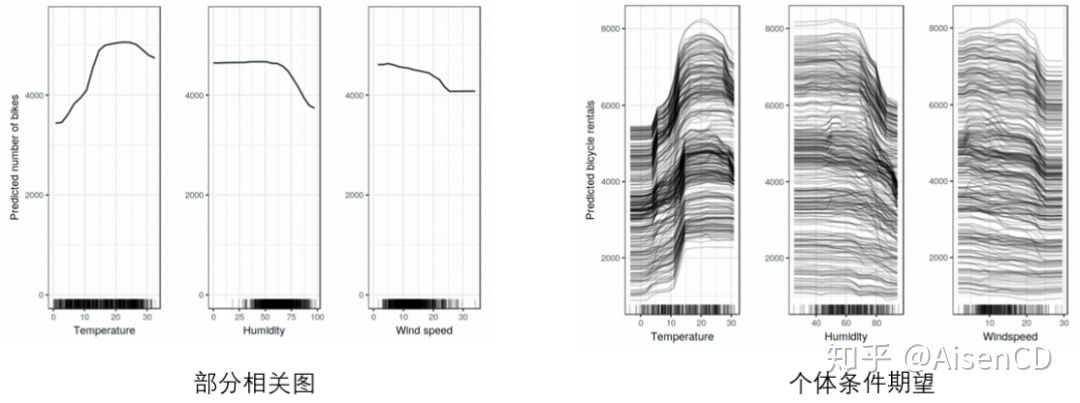
模型训练完成后(比如训练一个random forest模型),可以评估,在其他自变量取值不变的情况下,特定的自变量变化对因变量的影响。再通过计算原模型针对每个样本预测出来的平均值,可以获得部分相关图(Partial Dependence Plot)。在实际应用中,部分依赖图最大的好处是,可以很直观地展示某个特征对于模型预测效果的影响。类似建模之前基于特征黑白样本分布进行的单变量分析,部分依赖图可以很直观地展示,当一个特征取值变化时,模型预测效果会如何变化。
如果取的不是所有样本预测结果的均值,而是把每一个样本的变化趋势画出来,那就可以得到个体条件期望图(Individual Conditional Expectation)。通过个体条件期望图,每个实例对每个特征的预测依赖关系可以可视化展示出来。每个特征下的每个实例都会分别产⽣⼀条线,⽽部分依赖图是个体条件期望图的平均值,因此每个特征只有⼀条线。
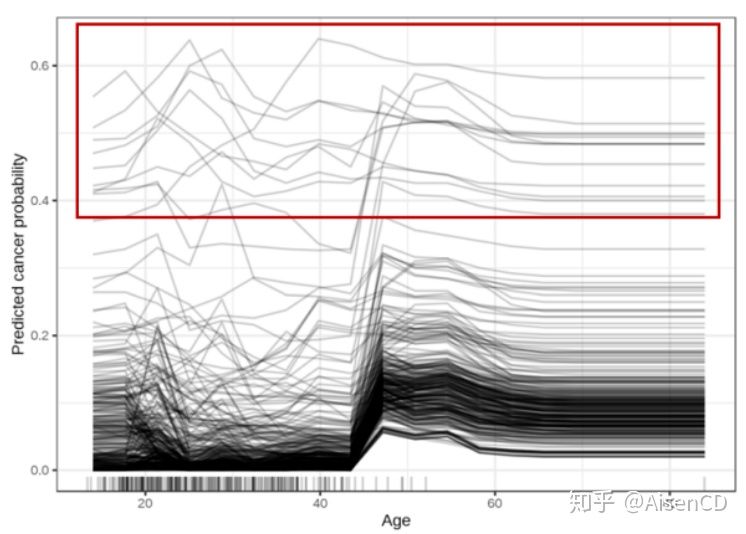
个体条件期望图还提供了识别异常样本的能力,如上图所示,对于⼤多数样本⽽⾔,年龄效应遵循 50 岁时平均增加的趋势,但也有⼀些例外:对于少数⼏位在年轻时(年龄20到40岁之间)就具有较⾼预测概率的样本(比如概率0.4以上),预测的癌症概率不会随年龄变化太⼤。
4.2.累积局部效应图
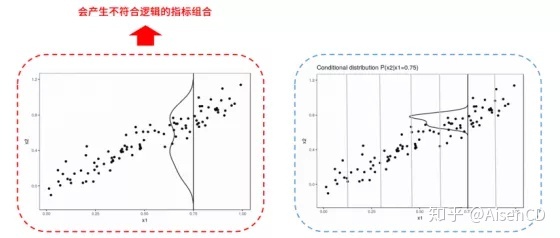
当某个特征与其他特征不相关时,部分依赖图可以最好地描述这个特征的变化与预测结果之间的关联性。但是,当这个特征与其他特征有一定相关性时,部分依赖图会输出超过实际情况的预测结果(如左图)。比如随着住宅面积增加,理论上房间数量也会相应增加;当身高增加时,体重也会相应增加。由于部分依赖图会基于构建完成的模型参数,假设在其他所有特征值保持不变的情况下,输出单个特征值变化时模型预测结果的变化。因此随着某个特征值不断增加时,部分依赖图可能会在不现实的指标值组合的基础上,输出不符合现实逻辑的预测结果。
解决这个问题的一种方法是使用基于条件分布的累积局部效应图(ALE:Accumulated Local Effects Plot),替代基于边际分布的部分依赖图。ALE 图是通过基于特征的条件分布来计算模型预测的差异,而不是预测的平均值。比如当希望计算居住面积这一特征在30平方米左右时对模型预测房价的影响,基于ALE方法可以首先选取所有30平方米左右的房屋,假定这些房屋为31平方米时模型的预测,减去假定为29平方米时模型的预测。通过这种方法可以尽量关注更纯粹的居住面积特征变化所带来的影响,排除不符合逻辑特征组合对模型预测的影响。
4.3.SHAP
Shapley值理论是一种基于边际贡献的利益分配方案,考虑合作联盟中各参与者对项目总收益的重要程度,也即是通过参与者的贡献度进行联盟收益分配,现在广泛应用于供应链利益分配、PPP项目风险分担、城镇化发展差异分析等领域。Shapley值解决的问题可以通过这个例子说明:假设A、B、C三个人合作经商,单干每人可以收入100元。A、B合作俩人可收入700元,A、C合作俩人收入500元,B、C合作俩人收入400元。三个人一起合作可以收入1000元。问:三个人合作时如何合理地分配1000元的收入?
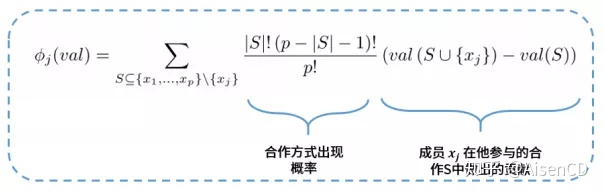
基于Shapley值理论方法,如上图所示,可以找到上面问题的最优收益分配方案。即Shapley值是唯一满足如下四个前提的公平支出方法:
- 效益性(Efficiency):特征贡献必须加起来等于特征值和平均值的预测差;
- 对称性(Symmetry):如果两个特征值对所有可能的联盟均贡献相同,则它们的贡献应相同;
- 虚拟性(Dummy):假设无论将特征值添加到哪个集合,都不会改变预测值的特征,它的Shapley值应为0;
- 可加性(Additivity):有多种合作时,每种合作的利益分配方式与其他合作结果无关。
这四个性质可以被直观地理解为:1)全部收益都会被分配;2)多干多得;3)不干不得;4)干就完了,先后无所谓。Shapley值计算的基本思路可以理解为,计算一个特征加入到模型时的边际贡献,然后考虑到该特征在所有的特征序列的情况下不同的边际贡献,再取均值,即得到该特征某一个值的Shapley值。
SHAP是基于Python在Shapley值合作博弈论的启发下开发的一个”模型解释”包,可以解释任何机器学习模型的输出。所有的特征都视为“贡献者”,对于每个预测样本,模型都产生一个预测值,SHAP 值就是该样本中每个特征所分配到的数值。假设模型对某样本打分是0.8,某个特征值的SHAP值是0.5,说明性别这个特征值将样本的打分提升了0.5,相应的SHAP值也有负值,相当于降低打分,如下图:
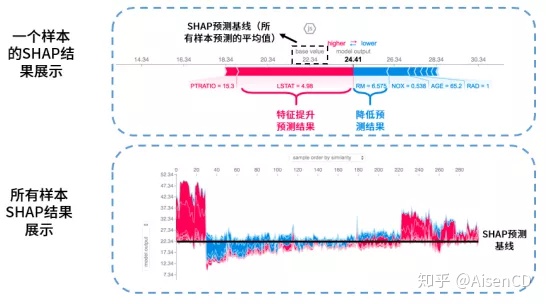
基于SHAP值也可以输出每个指标的重要性,如下图:
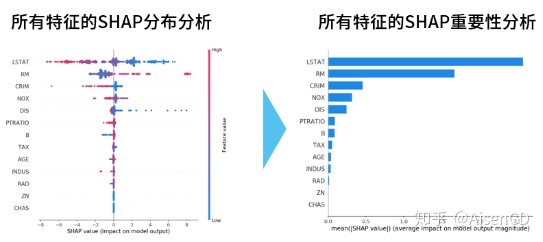
4.4.局部代理(LIME: Local Interpretable Model-agnostic Explanations)
LIME 算法的思路可以理解成,将样本空间拆解到局部之后,针对一个局部可以尝试用易于解释的简单模型(比如线性模型)去拟合原来不易解释的复杂模型。这样,一旦局部跟一个简单的线性模型之间产生了近似的拟合关系,就可以用简单模型去解释这个局部。所有局部得到解释之后,整体也就可以解释了。下图介绍了LIME在结构化数据上进行分类是如何工作的。
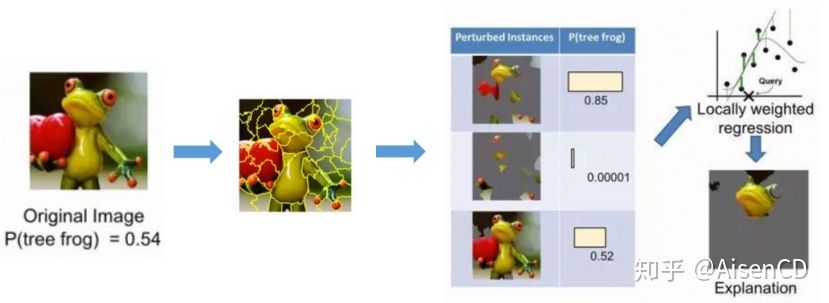
对于图像,下面的例子说明了LIME如何在图像分类领域工作的。假设我们想解释一个可以预测树蛙的分类器,我们可以首先基于连续超像素(contiguous superpixels)方法,使左边的原始图片分解成多个不同局部。之后通过在分解后的图片上加入扰动因素(比如涂成灰色),来生成不同的新的实例数据集。对于每一个新生成的干扰实例,模型都可以计算一个预测为树蛙的概率。基于不同干扰实例可以构建学习一个新的线性局部权重强化模型,其中预测效果好的局部权重更大。通过这种方法,我们可以找到具有最高正权重的超混合体作为模型的解释,并使其他一切区域都涂成灰色。
4.5.神经网络相关的模型可解释性探索
尝试解释神经网络的研究一直也没有停止过,常用的思路包括比如:
- 基于梯度反向传播的方法(Deconvolution, Backpropagation, Guided Backpropagation, Integrated Gradients, SmoothGrad);
- 基于层节点关联传播的方法(Sensitivity Analysis, Simple Taylor Decomposition, Layer-wise Relevance Propagation, Deep Taylor Decomposition, DeepLIFT);
- 基于类激活映射的方法(Class Activation Map, Grad-CAM, Grad-CAM++);
- 基于输入样本中引入噪声的方法(Rate-Distortion Explanation)。
基于反向传播机制解释方法的核心思想,是将模型的决策信号逐层反向传播到模型的输入,用于推导输入样本的特征重要性,比如利用反向传播算法计算模型的输出相对于输入图片的梯度来求解该输入图片所对应的分类显著图(Saliency Map)。尽管上述基于梯度反向传播的方法可以定位输入样本中决策特征,但却无法量化每个特征对模型决策结果的贡献程度。基于层节点关联传播的方法可以解决这一问题,基本思路是通过反向传播将高层特征的贡献逐层传递到模型的输入,以确定每一层的每一个神经元节点对其下一层神经元节点的相对贡献。给定一个待解释样本,该方法不仅可以定位样本中的重要特征,而且还能量化每一个特征对于分类结果的重要性。
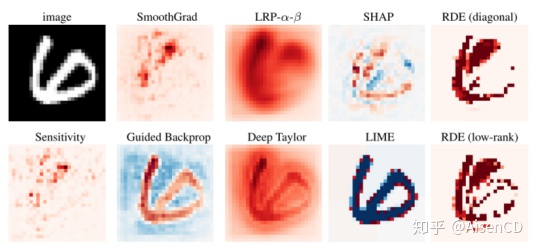
不同神经网络解释方法效果(梯度反向传播、层节点关联传播、输入样本中引入噪声、LIME、SHAP)可以通过如下MNIST和STL-10数据集进行比对:

参考文献:
1)Chen, et al. “This Looks Like That: Deep Learning for Interpretable ImageRecognition.”ArXiv.org,28Dec. 2019, http://arxiv.org/abs/1806.10574.
2)Doshi-Velez,andKim. “Towards A Rigorous Science of Interpretable MachineLearning.” ArXiv.org, 2 Mar. 2017, http://arxiv.org/abs/1702.08608.
3)Doshi-Velez, Finale, and Been Kim.”Considerations for Evaluation and Generalization in Interpretable Machine Learning.”The Springer Series on Challenges in Machine Learning Explainable and Interpretable Models in Computer Vision and Machine Learning,2018,pp.3–17., doi:10.1007/978-3-319-98131-4_1.
4)Fuchs,Johannes,etal.”Leaf Glyphs:Story Telling and Data AnalysisUsingEnvironmental Data Glyph Metaphors.”Communications in Computer and Information Science Computer Vision, Imaging and Computer Graphics Theory and Applications,2016,pp.123–143., doi:10.1007/978-3-319-29971-6_7.
5)Hall,Patrick,etal.”Ideas on Interpreting Machine Learning.” O’ReillyMedia,15Mar.2017,http://www.oreilly.com/radar/ideas-on-interpreting-machine-learning/.
6)Jaju,Saurabh,etal.”Guide to t-SNE Machine Learning Algorithm ImplementedinR&Python.”AnalyticsVidhya,9Oct.2019,http://www.analyticsvidhya.com/blog/2017/01/t-sne-implementation-r-python/.
7)Macdonald,etal.”A Rate-Distortion Framework for Explaining NeuralNetworkDecisions.”ArXiv.org,27May2019,http://arxiv.org/abs/1905.11092.
8)Molnar, Christoph.”Interpretable Machine Learning.” Christoph Molnar, 1 June 2020, http://christophm.github.io/interpretable-ml-book/.
9)scikitlearn.org,”MeansClustering.”,http://scikitlearn.org/stable/auto_examples/cluster/plot_cluster_iris.html.
10)Slundberg.”Slundberg/Shap.”GitHub,22May2020,http://github.com/slundberg/shap.
11)Tam,Greg.”Interpreting Decision Trees and Random Forests.”PivotalEngineeringJournal,PivotalSoftware,Inc.,19Sept.2017,http://engineering.pivotal.io/post/interpreting-decision-trees-and-random-forests/.
12)Ying, et al. “GNNExplainer: Generating Explanations for Graph Neural Networks.”ArXiv.org, 13 Nov. 2019, http://arxiv.org/abs/1903.03894.
原文:https://zhuanlan.zhihu.com/p/148742186
既然来了,说些什么?