机器学习模型的可解释性介绍
监督式机器学习极大的提升了预测的准确率,但能否信任这些模型?
部署在生产环节中的模型能否与开发系统中训练的模型工作的一样好?
除了进行预测,关于这个世界,模型还告诉了我们什么?(比如有没有解释什么原理)
本文是对关于模型可解释性的奠基性论文The Mythos of Model Interpretability的主要观点的梳理和解读,作者Zachary C. Lipton是UCSD的著名教授。虽然这篇文章是16年的,但是其对可解释性的思考和分类,并没有随着时间的推移而褪色。
1. 介绍
机器学习模型已渗透到医疗、司法和金融市场等许多关键领域,若不能理解这些模型,会导致问题,比如机器学习已被法院用于预测罪犯再次犯罪的风险,如果无法解释预测结果,后果可以想象。
模型的可解释性(interpretability)被认为是解决上述问题的办法,但可解释性缺乏准确定义,不同文献中指向不同的概念,因此也没有定量指标。
可解释性不是一个单体(monolithic)概念,它体现了多个不同的想法。
许多论文将可解释性认为是可信任的途径,但什么是信任(Trust)?
是对模型表现、鲁棒性还是其他决策属性的信心?
可解释性是否是一种底层的理解模型的机制?
如果是,可解释性是否适用于特征、参数、模型和算法?
可解释模型与其揭示的数据中的因果结构(Causal Structure)之间的关系是怎样的?

法律上的“解释权”(right to explaination)提供了可解释性的另一视角。欧美数据安全法GDPR赋予了用户向算法要解释的权利,如果未来我国实行类似条款,意味某程需要向用户解释其大数据杀熟的机制,外卖小哥可以问算法为啥给我派的单子都那么远,你也可以问某条为啥给你推不想看的新闻。换言之,厂商有必要向用户解释算法是如何进行决策的。使用深度学习的厂商,目前绝大多数都解释不了算法的结果,大数据模型则背上了用户权益被侵犯的锅。
机器学习问题的定义通常与真实世界要解决的问题并不能完美的匹配:
- 简化的优化目标不能完全捕捉复杂的真实目的,例如:我们可能希望发现吸烟与癌症的因果关系,但监督机器学习的优化算法只是最小化误差,以一种完全的相关性的方式来实现。(下文解释);
- 生产系统与离线训练模型的开发系统之间的数据差异,导致训练出来的模型不能完美的处理实际情况,生产环境的数据通常是非平稳的(non-stationary),比如在产品推荐场景中,新产品的引入或用户喜好的日常变化;
- 模型的输出改变了环境和数据,令模型失效(下文有案例)。
模型的什么属性与可解释性相关?有些论文将可解释性等同于可理解性(understandanility / intelligibility),这样我们就能理解模型是如何工作的,理解模型也被称为透明(transparent),而不能被理解的模型则被称为是黑盒。
但什么是透明?是算法能收敛吗?会产生唯一解吗?我们是否理解每个模型参数所代表的含义?要考虑模型的复杂性,是否简单到一个人能立刻检查所有参数?

也有一些论文研究了事后解释(post-hoc),就像人们会在事后对其行为进行解释那样,事后解释是指在训练完成后,我们从模型中能了解到的东西,或者说,如何以自然语言来解释模型的决策,比如分析深度神经网络的显著性映射(Saliency Maps)。
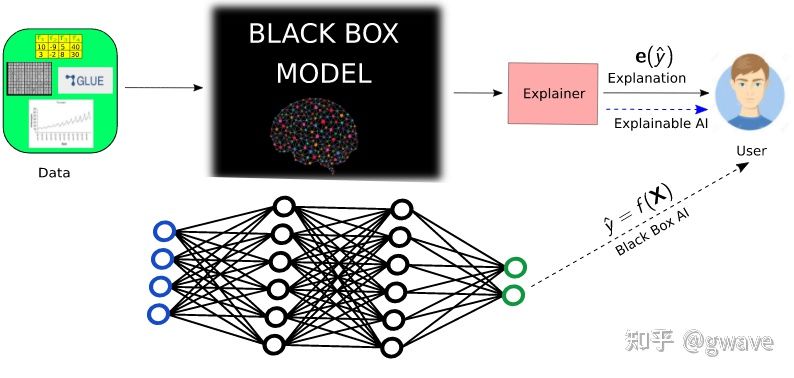
本文将讨论限制于监督式机器学习,强化学习和贝叶斯方法不是重点。
2. 可解释性研究的急需品
真实世界的很多情况很难被建模成一个实数的函数。比如一个招聘算法,要同时优化业务需求,道德伦理与法律(如性别和种族歧视等),但是后者又很难被直接优化。可解释性服务那些很重要但是难以建模的情形。
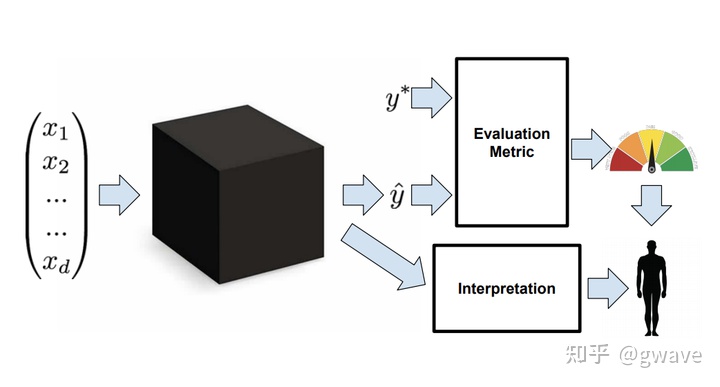
2.1 信任:
什么是信任?
仅仅是对模型会表现良好的信心吗?如果是这样,一个足够准确的模型应该是值得信赖的,这样的话可解释性就没有必要了。
信任的定义可能也是主观的。例如,一个人可能会对他理解的模型感到更信任。或者,当训练和测试数据来自不同的分布时,信任表示对该模型将在实际目标和情景方面表现良好的信心。
信任机器学习模型的另一层含义是我们觉得可以不用人工控制它。从这个意义上说,我们可能不仅关心模型的正确率而且关心模型在哪些样本上是正确的。如果模型倾向于在人类犯错的输入空间犯错,而在人类准确时它通常也准确,那么它可能被认为是值得信赖的。但如果模型倾向于对人类能准确分类的输入犯错误,那就可能需要保持对算法的人工监督,即对模型缺乏信任。
2.2 因果
虽然机器学习模型是用来发现相关性的,但总有不少研究人员希望能从中发现或者生成假设,比如,一个简单的回归模型揭示了一种名为萨立多胺的镇静剂与出生缺陷或抽烟/肺癌之间存在很强的相关性。机器学习算法发现的相关性并不保证是因果关系。
从观察数据中推理出因果关系也不是不可能(传统统计学认为不可能),但需要较强的先验知识。相关性与因果是两个不同层面的概念,图灵奖得主Judea Pearl的著作《为什么》The book of Why 对其进行了详细的解读。
2.3 可转移性(Transferability)
一般情况下,训练集和测试集是随机生成的,这样可以保证它们来自同一分布。可通过在这两个数据上模型表现的差异来评估模型的泛化能力。
人具有很强的将学习到技能泛化和迁移到其他领域的能力,机器学习算法也需要在这样的环境下工作,比如当环境不平稳(Stationary)的时候。
更严重的情况是:模型的部署和使用改变的数据的模式,破坏了未来的预测。Caruana et al. (2015)描述了一个预测肺炎病人死亡率的模型,该模型将哮喘患者预测为低死亡风险,但如果在分诊时采用这个模型,这些哮喘病人将可能得不到足够的医疗服务,死亡率将上升,使现有模型失效。
2.4 信息(Informativeness)
监督式机器学习除了输出结果在真实世界采取行动(如产品/内容的推荐,派单等)以外,也经常为决策者提供决策支持(Kim et al. 2015, Huys-mans et al. 2011),比如在人机协同时,提供一个可解释的交互模型。虽然机器学习模型的目标是最小化误差,但实际情况是希望能提供有效信息而不是一个简单的结果,如:病人被告知肿瘤是良性或恶性之后,他往往希望知道更多,为什么是这个结果。
即便在不了解模型内部工作原理的情况下,解释也可能是有意义的,如:在诊断性决策中,诊断模型给决策者提供一个类似的案例将很有帮助。
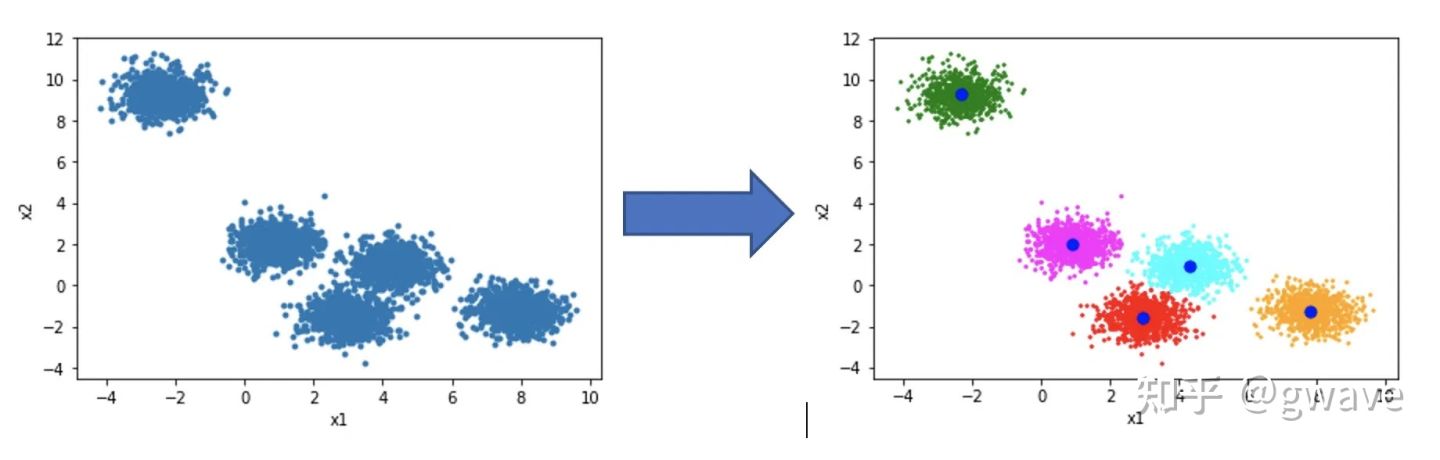
有时,我们训练一个监督式机器学习模型,但真正的目的更接近于非监督学习,因为我们实际上是希望对数据进行探索,而为弱监督服务。在更了解数据分布的规律后,少量的标注数据就能产生不错的结果。
2.5 公平与道德决策
看一个例子,法院使用机器学习模型对罪犯再次犯罪的概率进行评估,评估结果将影响是否会被释放或继续羁押,已引发了道德伦理上的担忧。准确率和AUC曲线并不能使人信服,公平的诉求要求模型具有可解释性。
原文:https://zhuanlan.zhihu.com/p/386295805
既然来了,说些什么?