机器学习的可解释性:黑盒vs白盒
作者 | Lars Hulstaert
译者 | Linstancy
责编 | Jane
出品 | AI科技大本营(公众号id:rgznai100)
【导语】模型的可解释性是大多数机器学习系统都需要的一种能力,即能向用户解释模型能做出这些预测的原因。在本篇文章中,作者将与大家探讨一些可用于解释机器学习模型的不同技术,并且重点介绍两种提供全局和局部解释、且与模型本身无关可解释性技术。这些技术可以应用于任何机器学习算法,并通过分析机器学习模型的响应函数来实现可解释性。
前言
在选择一个合适的机器学习模型时,通常需要我们权衡模型准确性与可解释性之间的关系:
黑盒模型 (black-box):诸如神经网络、梯度增强模型或复杂的集成模型此类的黑盒模型 (black-box model) 通常具有很高的准确性。然而,这些模型的内部工作机制却难以理解,也无法估计每个特征对模型预测结果的重要性,更不能理解不同特征之间的相互作用关系。
白盒模型(white-box):另一方面,像线性回归和决策树之类的简单模型的预测能力通常是有限的,且无法对数据集内在的复杂性进行建模 (如特征交互)。然而,这类简单模型通常有更好的可解释性,内部的工作原理也更容易解释。
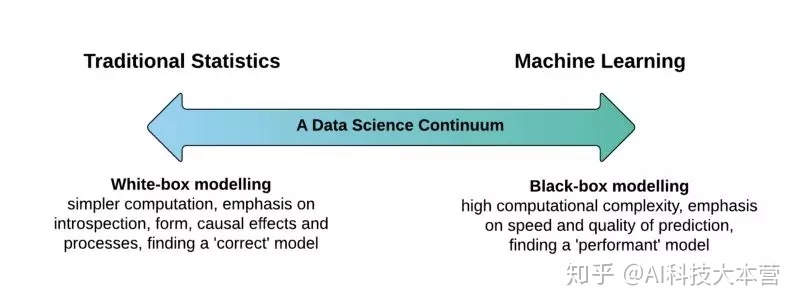
模型准确性与可解释性关系之间的权衡取决于一个重要的假设:“可解释性是模型的一个固有属性”。通过正确的可解释性技术,任何机器学习模型内部工作机理都能够得以解释,尽管这需要付出一些复杂性和计算成本的代价。
模型属性
机器学习模型的可解释程度通常与响应函数 (response function) 的两个属性相关。模型的响应函数 f(x) 定义模型的输入 (特征x) 和输出 (目标函数 f(x)) 之间的输入-输出对关系,而这主要取决于机器学习模型,该函数具有以下特征:
- 线性:在线性响应函数中,特征与目标之间呈线性关系。如果一个特征线性变化,那么期望中目标将以相似的速率线性变化。
- 单调性:在单调响应函数中,特征与目标对于之间的关系始终在一个方向上变化 (增大或减小)。更重要的是,这种关系适用于整个特征域,且与其他的特征变量无关。
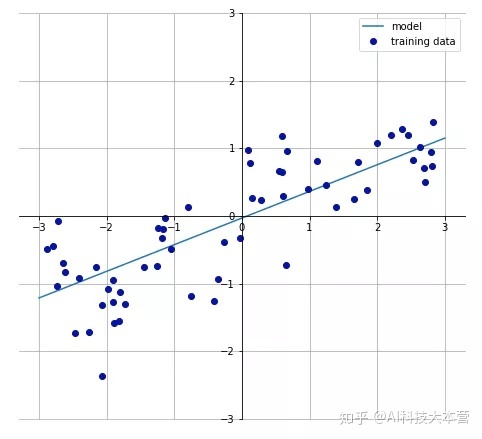
线性回归模型的响应函数就是个线性单调函数,而随机森林和神经网络的响应函数则是高度非线性、非单调响应函数的例子。
下图则阐述了在需要清晰简单的模型可解释性时,通常首选白盒模型 (具有线性和单调函数) 的原因。图的上半部显示,随着年龄的增长,购买数量会增加,模型的响应函数在全局范围内具有线性和单调关系,易于解释模型。
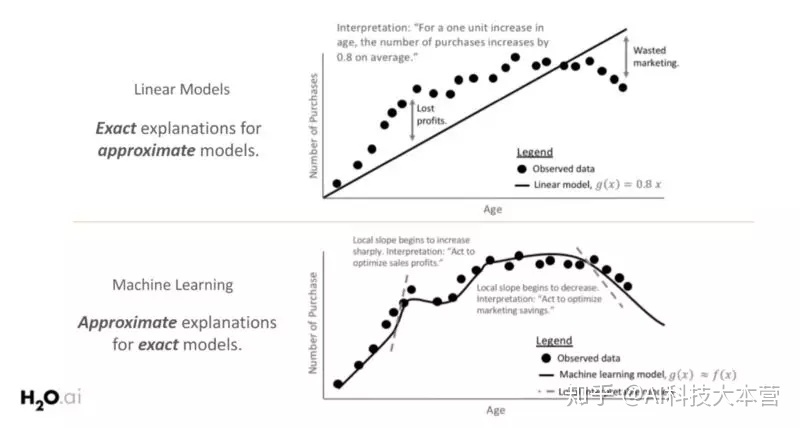
然而,由于白盒模型响应函数的线性和单调约束,通常容易忽略其变化趋势的重要部分。通过探索更复杂的机器学习模型能够更好地拟合观测数据,而这些复杂模型的响应函数只是在局部呈单调线性变化。因此,为了解释模型的行为,研究模型局部变化情况是很有必要的。
模型可解释性的范围,如全局或局部层面,都与模型的复杂性紧密相关。线性模型在整个特征空间中将表现出相同的行为 (如上图所示),因此它们具有全局可解释性。而输入和输出之间的关系通常受到复杂性和局部解释的限制 (如为什么模型在某个数据点进行某种预测?),将其默认为全局性解释。
对于那些更复杂的模型,模型的全局行为就更难定义了,而且还需要对其响应函数的小区域进行局部解释。这些小区域可能表现出线性和单调,以便得到更准确的解释。
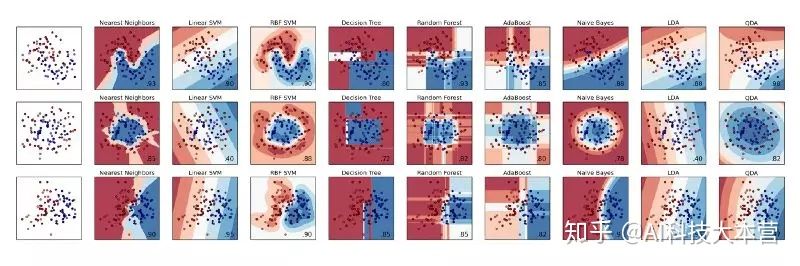
ML 库 (例如 sklearn) 允许对不同分类器进行快速比较。当数据集的大小和维度受限时,我们还可以解释模型的预测结果。但在大多数现实问题中,情况就不再是如此。
接下来将为大家重点介绍两种提供全局和局部解释、且与模型本身无关可解释性技术。这些技术可以应用于任何机器学习算法,并通过分析机器学习模型的响应函数来实现可解释性。
可解释性技术
1、代理模型 (Surrogate models)
代理模型通常是一种简单模型,用于解释那些复杂模型。常用的代理模型有线性模型和决策树模型,主要是由于这些模型易于解释。构建代理模型,将其用于表示复杂模型 (响应函数) 的决策过程,并作用于输入和模型预测,而不是在输入和目标上训练。
代理模型在非线性和非单调模型之上提供了一个全局可解释层,但它们不完全相互依赖。它的作用只要是作为模型的“全局总结”,并不能完美地表示模型底层的响应函数,也不能捕获复杂的特征关系。以下步骤说明了如何为复杂的黑盒模型构建代理模型:
- 训练一个黑盒模型。
- 在数据集上评估黑盒模型。
- 选择一个可解释的代理模型 (通常是线性模型或决策树模型)。
- 在数据集上训练这个可解释性模型,并预测。
- 确定代理模型的错误度量,并解释该模型。
2、LIME
LIME 是另一种可解释性技术,它的核心思想与代理模型相同。然而,LIME 并不是通过构建整个数据集的全局代理模型,而只是构建部分区域预测解释的局部代理模型 (线性模型),来解释模型的行为。有关 LIME 技术的深入解释,可以参阅 LIME 有关的文章
文章链接:
https://towardsdatascience.com/understanding-model-predictions-with-lime-a582fdff3a3b
此外,LIME 方法能够提供一种直观的方法来解释给定数据的模型预测结果。有关如何为复杂的黑盒模型构建 LIME 解释模型的步骤如下:
- 训练一个黑盒模型。
- 采样局部感兴趣区域的样本点,这些样本点可以从数据集中直接检索,也可以人工生成。
- 通过邻近的感兴趣区域对新样本进行加权,通过在数据集上使用变量来拟合得到一个加权的、可解释的代理模型。
- 解释这个局部代理模型。
结论
总的来说,你可以通过几种不同的技术来提高机器学习模型的可解释性。尽管,随着相关领域研究的改进,这些技术也将变得越来越强大,但使用不同技术并进行比较仍然是很重要的。
本文没有讨论的 Shapley 技术在模型可解释性方面的应用,感兴趣的话可以查阅 Christoph Molnar 关于“可解释的机器学习”的书 (Interpretable Machine Learning),以了解更多相关技术的知识。
原文链接:
https://towardsdatascience.com/machine-learning-interpretability-techniques-662c723454f3
福利:开源书籍《可解释的机器学习》
开源书籍《可解释的机器学习》,由作者 Christoph Molnar 历时两年编写而成。书籍累计 250 多页、7.8 万词、1200 多次提交。先上 GitHub 地址:
https://christophm.github.io/interpretable-ml-book/

全书包括十个章节,从”什么是 Machine Learning“开始、到什么是可解释,可解释性的方法与案例,最后探讨了机器学习与可解释的未来。相信这本书可以帮助大家对机器学习的可解释性有更深的了解,真的是要感谢作者的无私贡献。
既然来了,说些什么?