XAI进行到底 — SHAP值理论(一)
最近在系统性的学习AUTOML一些细节,本篇单纯从实现与解读的角度入手, 因为最近SHAP版本与之前的调用方式有蛮多差异,就从新版本出发,进行解读。
不会过多解读SHAP值理论部分,相关理论可参考:
关于SHAP值加速可参考以下几位大佬的文章:
官方: slundberg/shap
1 介绍
文章可解释性机器学习_Feature Importance、Permutation Importance、SHAP 来看一下SHAP模型,是比较全能的模型可解释性的方法,既可作用于之前的全局解释,也可以局部解释,即单个样本来看,模型给出的预测值和某些特征可能的关系,这就可以用到SHAP。
SHAP 属于模型事后解释的方法,它的核心思想是计算特征对模型输出的边际贡献,再从全局和局部两个层面对“黑盒模型”进行解释。SHAP构建一个加性的解释模型,所有的特征都视为“贡献者”。
对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。
基本思想:计算一个特征加入到模型时的边际贡献,然后考虑到该特征在所有的特征序列的情况下不同的边际贡献,取均值,即某该特征的SHAPbaseline value
文章kaggle | Machine Learning for Insights Challenge提及: Permutation importance很不错,因为它用很简单的数字就可以衡量特征对模型的重要性。但是它不能handle这么一种情况:当一个feature有中等的permutation importance的时候,这可能意味着这么两种情况:
– 1:对少量的预测有很大的影响,但是整体来说影响较小;
– 2:对所有的预测都有中等程度的影响。
SHAP 就可以应用的上,来看一下SHAP呈现的几种图,本轮笔者 是直接拿slundberg/shap中的代码,发现0.39.0版本,跟之前的版本差异非常大,很多函数名称都发生了变化。
笔者实验下述代码的环境:anaconda + py3.7 + jupyter notebook + shap==0.39.0
安装方式:
pip install shap
or
conda install -c conda-forge shap2 可解释图
那就从拆解当下slundberg/shap的案例入手,开始解读SHAP值的各类神图:
注意画图前需要加:
shap.initjs()2.1 [微观]单样本特征影响图一:waterfall
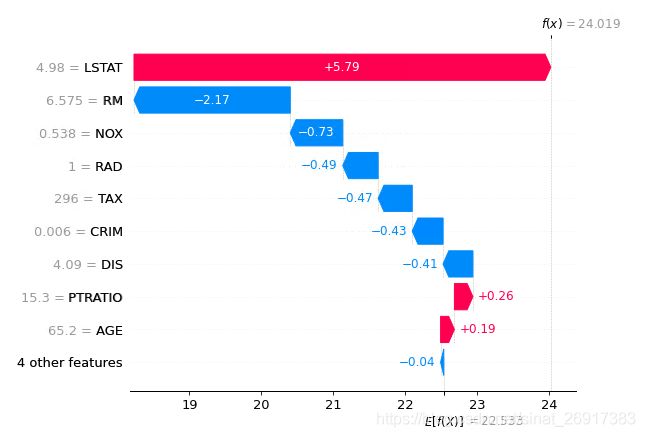
图一:
该图代表第0个样本,
Y轴代表不同特征值,
X代表SHAP值,
E[f(x)]代表所有样本f(x)的期望,base_values,model.predict(X)的预测值的平均值
f(x)代表第0个样本,f(x)值的大小为第0个样本的预测值, model.predict(X[0]) = base_values + sum(shap_values[0].values)
红色代表,该特征对第0个样本是正向增益的。 蓝色为负向,由此可以看到哪些特征增益好 / 坏
import xgboost
import shap
shap.initjs()
# train an XGBoost model
X, y = shap.datasets.boston()
model = xgboost.XGBRegressor().fit(X, y)
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap.Explainer(model)
shap_values = explainer(X)
# visualize the first prediction's explanation
shap.plots.waterfall(shap_values[0])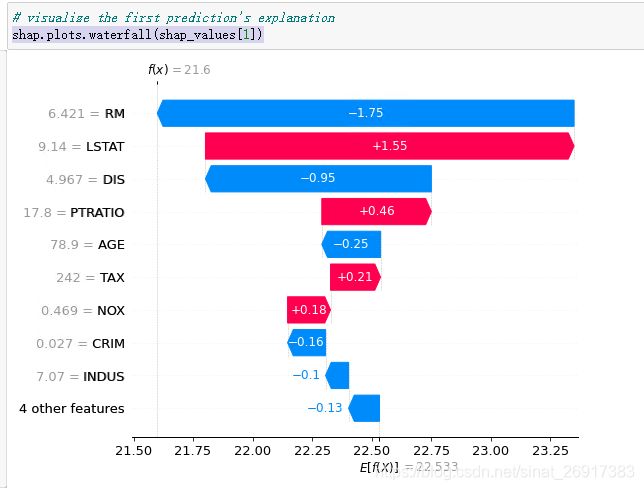
这个是第0个样本的 所有信息,其中
– base_values -> 平均,f(x) 值 所有样本一样(f(x) = 特征值 * 特征SHAP值(类似回归系数))
– values -> 这一个样本,每个特征的SHAP值 – data -> 这一个样本,样本特征值
2.2 [微观]单样本特征影响图二:force plot
整个理论的核心图:

shap.initjs()
# visualize the first prediction's explanation with a force plot
shap.plots.force(shap_values[0])shap值类似回归系数:有正负之分,大小之分
如果解读这个图:
- shap_values[0] – 第0个样本
- shap_values[0].base_values – 22.53,所有样本汇总的平均 f(x) 值,所以所有值都一样,模型在数据集上的输出均值22.53
- shap_values[0].data – 所有特征原值,本案例是数据集shape为
(506, 13),第0个样本13个特征的具体值 - shap_values[0].values – 第0个样本13个特征的shap值
所以,图中所有样本基础平均f(x)值:22.53,该样本shap值加总之后为f(x) -> 24.02
计算方式:第0个样本特征原值 第0个样本特征shap值 = shap_values[0].data * shap_values[0].values
- 红色代表:正向影响,LSTAT这个特征,正向影响,shap值,4.98,影响最大;PTRATIO也是正向
- 蓝色代表:负向影响,RM特征,负向影响,shap值,6.575,负向的
来看一下:shap_values[0]
.values =
array([-4.2850167e-01, -6.6636719e-02, 7.7860229e-02, -1.5295845e-03,
-7.2922713e-01, -2.1700280e+00, 1.9213372e-01, -4.1425934e-01,
-4.9156108e-01, -4.7296646e-01, 2.5669456e-01, -5.3907130e-02,
5.7883248e+00], dtype=float32)
.base_values =
22.532942
.data =
array([6.320e-03, 1.800e+01, 2.310e+00, 0.000e+00, 5.380e-01, 6.575e+00,
6.520e+01, 4.090e+00, 1.000e+00, 2.960e+02, 1.530e+01, 3.969e+02,
4.980e+00])2.3 [宏观]特征影响图
官方给到的code:
# visualize all the training set predictions
shap.plots.force(shap_values)会一直报错:
Exception: In v0.20 force_plot now requires the base value as the first parameter! Try shap.force_plot(explainer.expected_value, shap_values) or for multi-output models try shap.force_plot(explainer.expected_value[0], shap_values[0]).所以,目前笔者测试的时候,需要按照这个公式:shap.plots.force(平均f(x)值,shap值,特征重要性) 这里是可以自由选择样本数的,样本少,密度不大,看到的东西多一些:
# 全样本
shap.plots.force(explainer.expected_value,shap_values.values,shap_values.data)
# 前100个样本
shap.plots.force(explainer.expected_value,shap_values.values[:100],shap_values.data[:100])这张图的来源:
上面的一个样本的解释图旋转90°,然后水平的堆积起所有的样本,就会出现上面的图片。这是全样本的解释图,我们可以选择不同的横纵坐标。
- X – 横轴是样本数量,
- Y – 纵轴是shap值加总(每个特征值 * 每个特征的shap值)
这里横轴的排列是非常有讲究的,因为不是按顺序排列的,该图会把受相同特征影响大的放一起,
比如观察最左边,蓝色扎堆是负向shap增益区,划过可以看到基本是0/4/5/12这几个特征对大多数样本都有负向增益; 当然同样,右边,红色扎堆,12/5/10对一些样本是正向增益的
整体来说,该图是一个宏观的了解,诸多样本不同的特征对其的影响
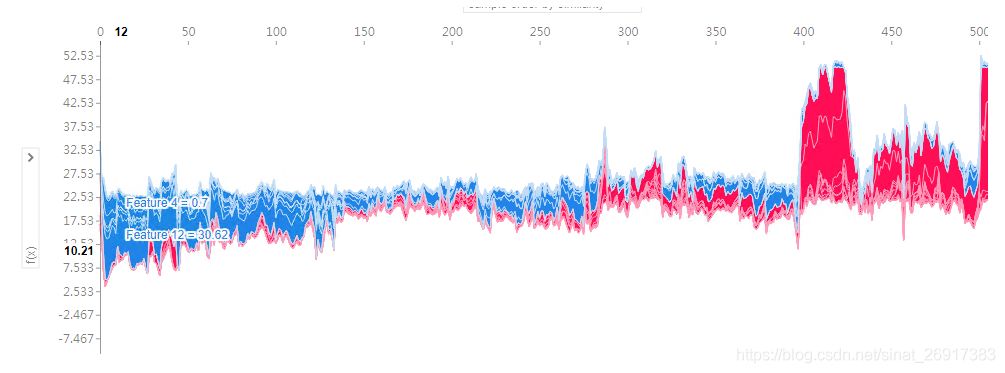
来看单点:
jupyter中点击了,会静态,看到某个样本,不同特征的f(x)值
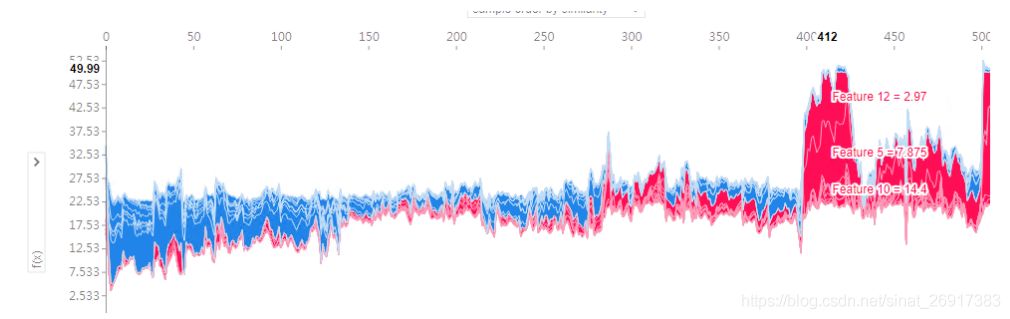
另外也可以指定一些样本:
# visualize all the training set predictions
# shap.plots.force(基础值,shap值,特征重要性)
shap.plots.force(explainer.expected_value,shap_values.values[:100],shap_values.data[:100])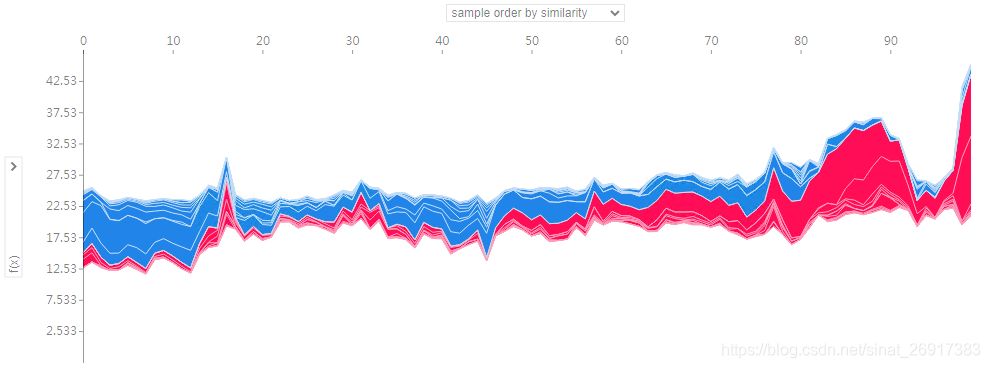
整体会变得稀疏一些,看起来友好
2.4 [宏观]特征依赖图——dependence scatter plot
代表两个变量交互效应,这里借鉴文章酒店排名模型中的商业价值度量
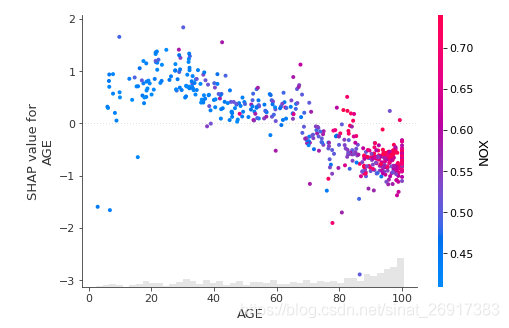
# create a dependence scatter plot to show the effect of a single feature across the whole dataset
shap.plots.scatter(shap_values[:,"AGE"], color=shap_values[:,"DIS"])解读一下这个三维散点图,主要解释的是:NOX -> AGE特征的影响
- X轴为AGE特征的特征值范围,
- Y轴为AGE特征的shap值,对于模型的输出会带来的变化量
其中我们可以发现对于同一个x 值,也就是特征取值相同的样本,它们的shap value不同。其原因是,该特征和其他特征有着交互相应
右边是对比的特征NOX,这里红色代表NOX-高分部分;蓝色代表-NOX低分部分
从图中可知: 最右边,一堆红色点,NOX-高分部分 对于 高年龄来说,shap值一般小于0,所以是负面影响 左上角,稀稀拉拉的蓝色点,代表,NOX-低分部分 对于 低年龄来说,shap值一般大于0,所以是正面影响
有个问题,貌似不能指定,与AGE对比的变量?
参考: shap.plots.scatter(shap_values[:,"AGE"], color=shap_values[:,"DIS"]) 可以指定对比:AGE 与DIS之间的关系
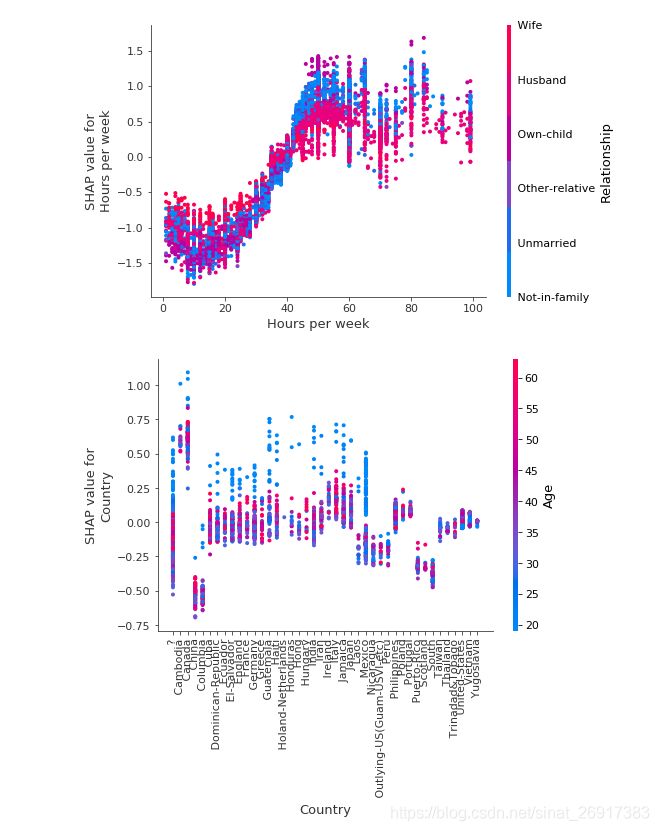
另外两个特征的影响,如果某个特征为分类特征,则会呈现序列装,如下图 notebooks/tree_explainer:
如果是分类变量,笔者还没遇见过,只是看到文章可解释机器学习-shap value的使用提及之前旧函数的一些注意事项:
能够正常显示分类变量的结果。也就是说,如果希望后面正常使用shap 的全部功能的话,最好就是在刚开始的时候,我们先把分类变量转成数字形式,也就是OrdinalEncoder 编码。
2.5 [宏观]特征密度散点图:beeswarm
# summarize the effects of all the features
shap.plots.beeswarm(shap_values)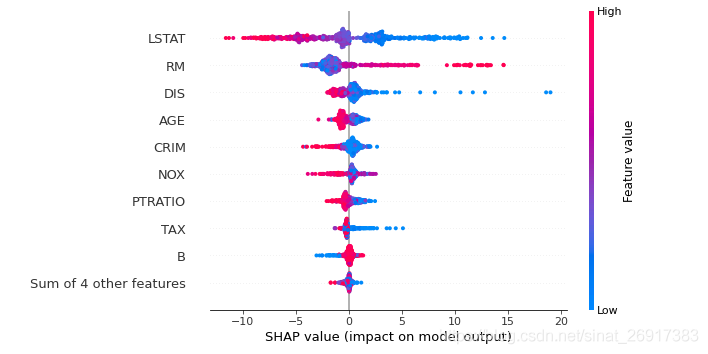
下图中每一行代表一个特征,横坐标为Shap值。特征的排序是按照shap 的平均绝对值,对模型来说的最重要特征。宽的地方表示有大量的样本聚集。
一个点代表一个样本,颜色越红说明特征本身数值越大,颜色越蓝说明特征本身数值越小。
可以看做一种特征重要性的排列图,
LSTAT对模型非常重要,而且LSTAT高分红点值的人,shap值小于0,负向影响; 特征值越小,shap大于0,正向影响
横向来看,LSTAT这个特征,样本分布较为分散,那么代表该特征影响越大
另外,比如特征 B ,大多数的点弥漫在SHAP = 0,所以对大部分人都没啥影响,只对小部分人有影响。
2.6 [宏观]特征重要性SHAP值
每个特征的shap值排序,与上述的一致
shap.plots.bar(shap_values)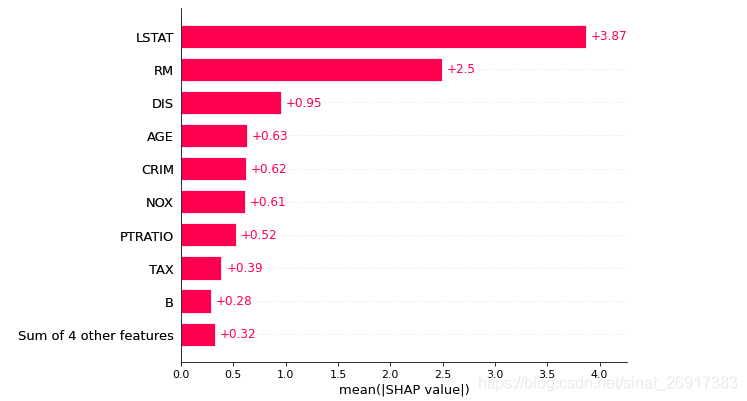
3 优质解读案例
3.1 酒店排名模型中的商业价值度量
截取文章:酒店排名模型中的商业价值度量
对模型的单个结果进行研究是有趣的,但是聚合视图可以让我们很好地查看模型给出的趋势。下面的摘要图按重要性降序列出了几个最重要的特征。每个点都是一个结果,它在x轴上的位置代表特征的SHAP值,颜色代表特征的相对大小,红色代表高,蓝色代表低。
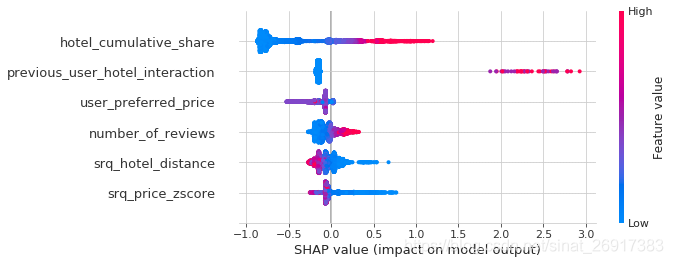
我们可以看到,最重要的特征是hotel_cumulative_share,在右侧有一个红色的大条,表示分享的多的酒店是好的。接下来是previous_user_hotel_interaction,这是一个标记,表示用户以前是否曾经浏览过该酒店。虽然这个标志通常设置为0表示没有交互,但是当它不是0时,它的影响是巨大的。与股票或评论计数不同,较低的相对价格几乎总是被认为是更好的。一般来说,具有良好历史业绩的酒店,离用户申报的目的地较近的酒店(如果有的话),以及相对便宜的酒店,都在模型中排名较高。
我想扩展最后一点,因为之前我说过,一个好的机器学习模型应该能够为不同的用户找到一个合适的价格区间。虽然该模型认为相对便宜的酒店更好,但它强调,这是不正确的,有时根本不符合用户显示出对高端酒店的偏好。
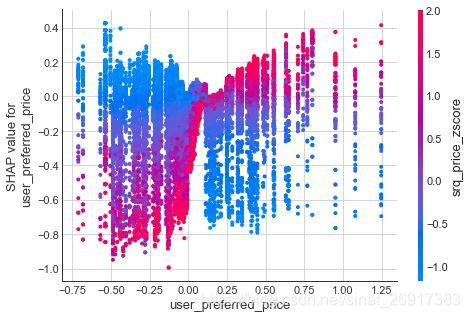
上面是一个部分依赖图,显示了x轴user_preferred_price上用户的价格水平和酒店的价格srq_price_zscore之间的交互。 一条长长的红色线条大致沿着y-x线,这说明昂贵的酒店对于低端用户具有负 SHAP值,与低端用户的相关性较小,对于高端用户具有正 SHAP值,与高端用户的相关性更大。 相反,垂直的蓝色条纹表明,该模型能够调整其对低端用户的期望。在不需要任何人工输入的情况下,该模型能够根据用户指定的价格水平将其与酒店进行匹配。
4 一致的个性化特征归因方法
对于可解释来说,一致性非常重要,稳定的归因方式才有稳定的解决。
一致性:每当我们更改模型以使其更依赖于某个特征时,该特征的归因重要性不应该降低。
如果一致性不成立,意味着当一个模型被更改为某个特征对模型输出的影响更大时,反而会降低该特征的重要性,那么我们不能比较任意两个模型之间的归因重要性,因为具有较高分配归因的特征并不意味着模型实际上更依赖该特征。
特征归因方法可以分全局和个性化(针对个体),其中全局特征重要度是为整个数据集计算的,该类特征归因方法通常都用特征重要度表示,主要有三种方式:
- 增益(Gain)。给定特征的所有分裂所贡献的损失或不纯度的总减少量,增益在特征选择方向上被广泛应用。
- 分裂数(Split Count)。在所有树中一个特征被用做分裂节点的次数。
- 置换。随机置换测试集中一个特征的值,然后观察模型误差的变化,如果一个特征的值很重要,那么遍历它会导致模型的错误大量增加。
上面三种都是基于整个数据集去计算特征重要度的,但对于树来说,计算单个预测的特征重要值的个性化方法却较少,虽然与模型无关的个性化解释方法(比如LIME)可以应用于树,但它们明显比树特定的方法慢,并且具有抽样变异性,
目前我们所知的树特有的个性化解释方法只有Sabbas,该方法与经典的全局的增益方法类似,但它不是测量损失的减少,而是测量模型预期输出的变化,通过比较模型在树根处输出的期望值与子树在子节点处输出的期望值,以及当前输入的决策路径,然后将这些期望之间的差异归因于在根节点上分离的特性,通过递归地重复这个过程,最后在决策路径上的特征之间分配预期模型输出和当前输出之间的差异。
下面举两个模型的例子对归因方法的一致性进行比较,假设模型的输出是基于人的症状的风险评分,对于二元特征发烧(Fever)和咳嗽(Cough),模型A只是一个简单的”和”函数,模型B是相同的函数,但是当为咳嗽时预测值会增加(加10分),使得模型更依赖于咳嗽,这时因咳嗽更重要,导致在模型B中咳嗽先分裂。
比较A、B模型在下面六种归因方法上的差别:
- Tree SHAP,本文提出的一种新的个性化方法。(个性化特征归因方法,为单个预测计算)
- Saabas,个性化的启发式特征归因方法。(个性化特征归因方法,为单个预测计算)
- mean(|Tree SHAP |),基于个性化Tree SHAP归因的平均幅度的全局归因方法(全局特征归因方法,为整个数据集计算,实际为所有样本的Tree SHAP值按照特征计算均值)
- 增益(全局特征归因方法,为整个数据集计算)
- 分裂数(全局特征归因方法,为整个数据集计算)
- 置换(全局特征归因方法,为整个数据集计算)
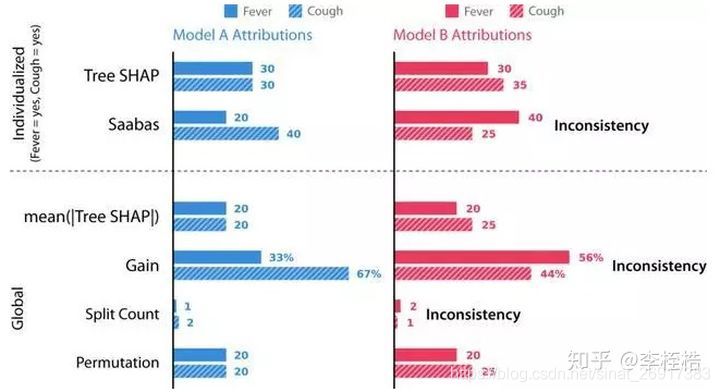
个性化特征归因方法:Tree SHAP、Sabbas,只有SHAP值能够保证反映特征的重要性,而Saabas值可能会给出错误的结果,比如模型B中认为更大的原因是发烧,而不是咳嗽,这是不一致的表现。
全局特征归因方法:mean(|Tree SHAP |)、增益、分裂数和特征置换,只有mean(|Tree SHAP |)和置换认为模型B咳嗽比发烧更重要,这意味着在一致性上增益和分裂数不是全局特性重要性的可靠度量。
所以gain、split count和Saabas方法中的特征重要度都不一致(使B模型更加依赖咳嗽时,却认为发烧更重要),这意味着模型改变为更多地依赖于给定的特性时,分配给该特征的重要性却降低了。通常我们期望树根附近的特征比在叶子附近分裂的特征更重要(因为树是贪婪地构造的),然而增益方法偏向于更重视较低的分裂,这种偏差会导致不一致,当咳嗽变得更加重要时(因此在根部分裂),其归因重要性实际上下降。个性化的Saabas方法在我们下降树时计算预测的差异,因此它也会受到与树中较低分割相同的偏差,随着树木越来越深,这种偏差只会增长。 相比之下,Tree SHAP方法在数学上等效于平均所有可能的特征排序的预测差异,而不仅仅是它们在树中的位置指定的排序。
所以在我们考虑的方法中,只有SHAP值和置换的方法是具有一致性的,而其中又只有SHAP值是个性化的,所以SHAP值是唯一一致的个性化特征归因方法。
5 详解base_values 和 单样本shap值的计算过程
import xgboost
import shap
shap.initjs()
# train an XGBoost model
X, y = shap.datasets.boston()
model = xgboost.XGBRegressor().fit(X, y)
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap.Explainer(model)
shap_values = explainer(X)
# visualize the first prediction's explanation
shap.plots.waterfall(shap_values[0])
# 第0个样本
# 样本 x 的所有特征的贡献之和等于预测值减去平均预测值
shap_values[0].base_values
shap_values[0].values
shap_values[0].data
predict = model.predict(pd.DataFrame(X.iloc[0,:]).T)
# base_values -> 平均,f(x) 值 所有样本一样
# values -> 这一个样本,每个特征的SHAP值
# data -> 这一个样本,样本特征值
# 每个样本特征shap值 与模型预测值的差异
sum(shap_values[0].values) = predict - shap_values[0].base_values
# 平均base_values的计算来源
model.predict(X).mean()
shap_values[0].base_values
每个样本特征shap值之和 = 该样本模型预测值 – 所有样本预测值的平均值 = predict – shap_values[0].base_values
base_values = 模型预测值平均值 = `model.predict(X).mean()`
就是计算每一个特征的shapley值之和,就是 整体 偏离平均预测值的贡献
原文:https://zhuanlan.zhihu.com/p/364919024
既然来了,说些什么?