谈谈机器学习模型的可解释性
随着AI和机器学习的发展,越来越多的决策会交给自动化的机器学习算法来做。但是当我们把一些非常重要的决定交给机器的时候,我们真的放心么?当波音飞机忽略驾驶员的指令,决定义无反顾的冲向大地;当银行系统莫名其妙否决你的贷款申请的时候;当自动化敌我识别武器系统决定向无辜平民开火的时候;人类的内心应该是一万个草泥马飞过,大声的质问,“为什么?”
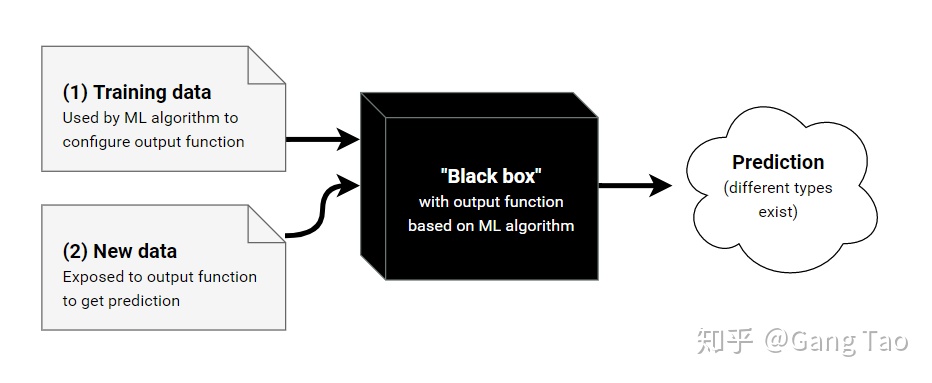
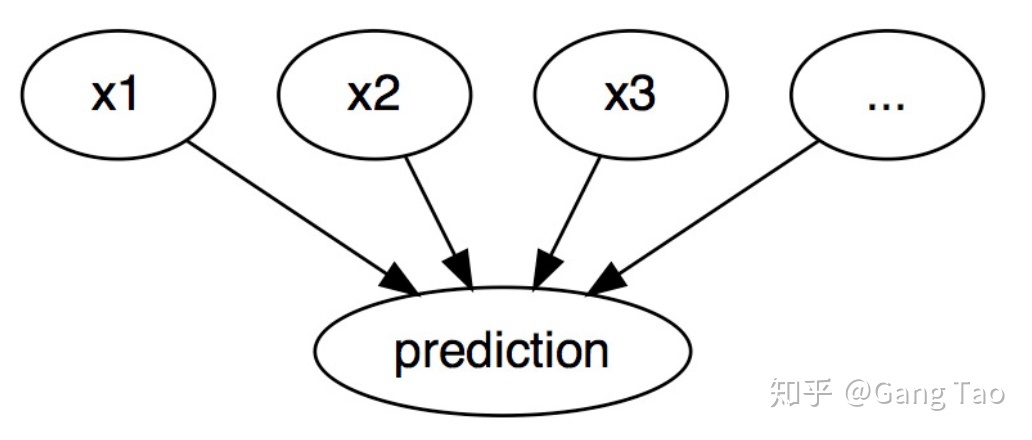
机器学习算法可以看成是如上图所示的黑盒子模型,训练数据流入黑盒子,训练出一个函数(这个函数也可以称之为模型),输入新的数据到该函数得出预测结果。关于模型的可解释性,就是要回答为什么的问题,如何解释该函数,它是如何预测的?
可解释的模型
在机器学习的众多算法中,有的模型很难解释,例如深度神经网络。深度神经网络可以拟合高度复杂的数据,拥有海量的参数,但是如何解释这些非常困难。但是还是有相当一部分算法是可以比较容易的解释的。
例如线性回归:
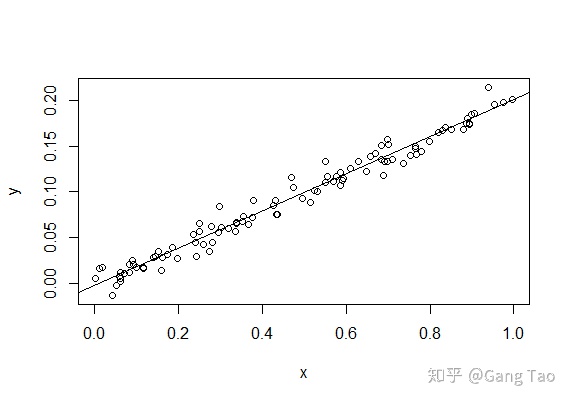
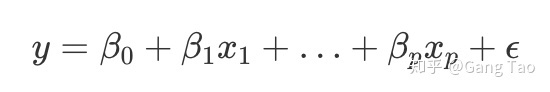
线性回归目标Y和特征X之间的关系如上图的公式所示。那么对于线性回归模型的解释就很简单,对于一个特定的特征Xi,每增加一个单位,目标Y增加βi。
线性回归简单易用,也能保证找到最优解。但是毕竟不是所有的问题都是线性的。
另外一个可解释的模型的例子是决策树。

如上图的决策树的例子所示,决策树明确给出了预测的依据。要解释决策树如何预测非常简单,从根结点开始,依照所有的特征开始分支,一直到到达叶子节点,找到最终的预测。
决策树可以很好的捕捉特征之间的互动和依赖。树形结构也可以很好的可视化。但是决策树对于线性关系的处理比较困难,他不够平滑,也不稳定,一个小的特征数据变化就可能改变整个树的构建。当树的节点和层级变大的时候,要解释整个决策过程也就相应的变得困难了。
其它还有一些可解释的模型,例如逻辑回归,通用的线性模型,朴素贝叶斯,K紧邻,等。
模型无关的方法
可解释的模型的种类毕竟有限,我们希望能够找到一些方法,对任何的黑盒子机器学习模型提供解释。这里就需要和模型无关的方法了。
Partial Dependence Plot ( PDP )
PDP用于表示一个模型中一个或者两个特征对于预测结果的影响。
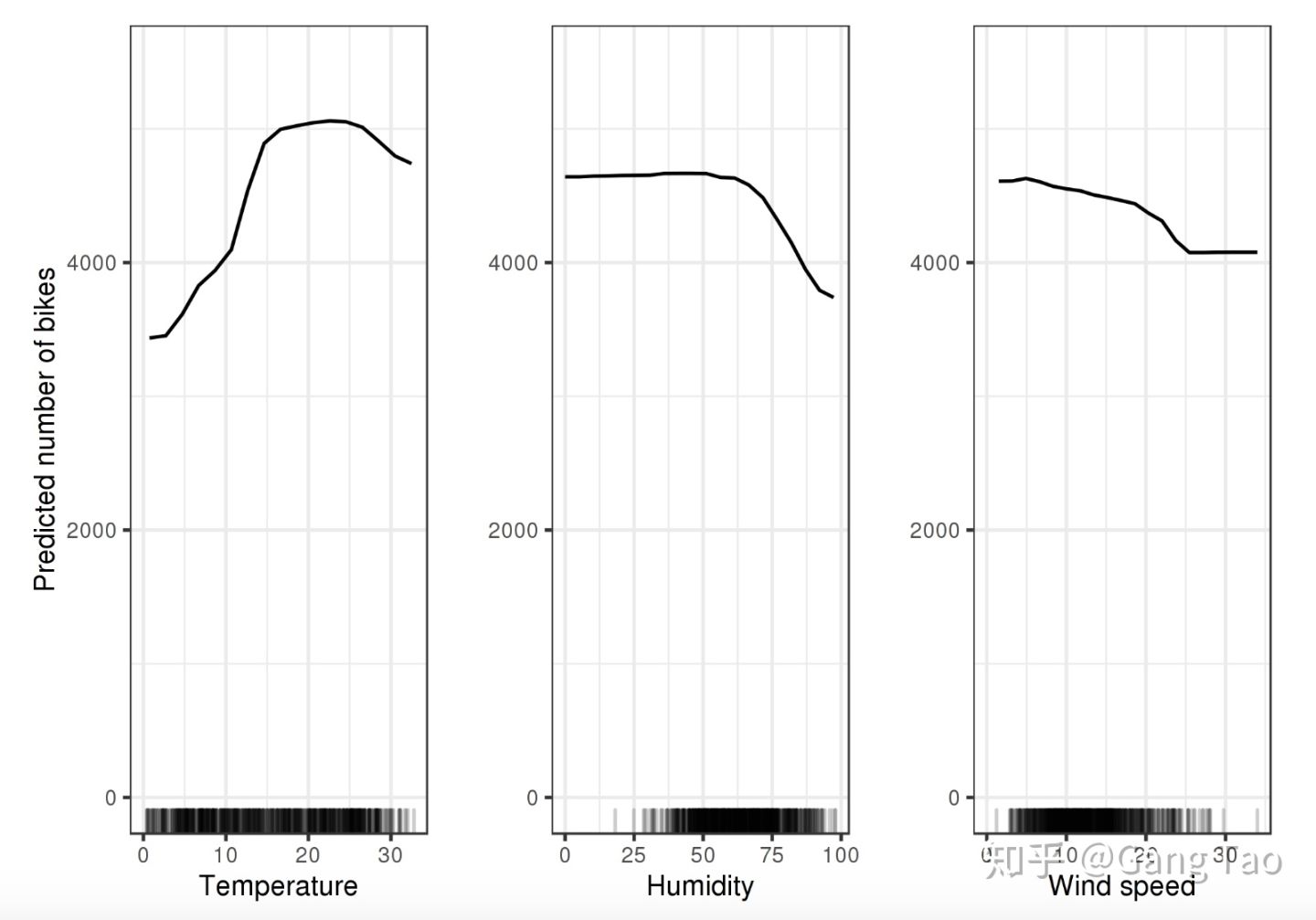
如上图的PDP图反应了三个特征温度(注意这里是3个PDP,PDP假定每一个特征都是独立的),湿度和风速对于骑车出行人数的影响。每一个图都是假定其它特征不变的情况下的趋势。
PDP图非常直观和容易理解,也很容易计算生成。但是PDP图最多只能反应两个特征,因为超过三维的图无法用当前的技术来表示。同时独立性假设是PDP的最大问题。
Individual Conditional Expectation (ICE)
ICE显示了对于每一个样本实例,当改变某一个特征的值得时候,预测结果是如何改变的。
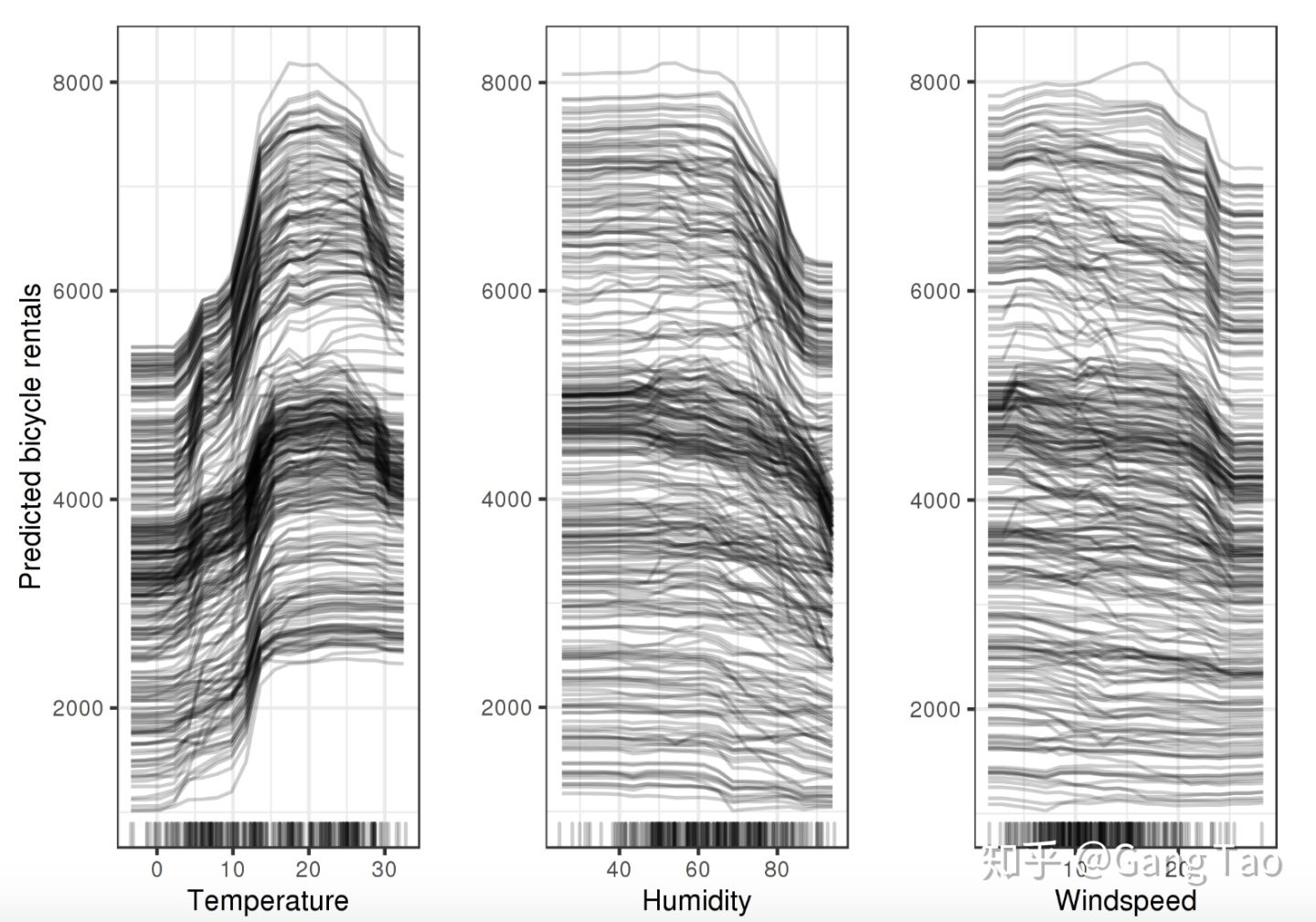
如上图所示,这个和PDP的图反映了一致的趋势,但是包含了所有的样本。
和PDP类似,ICE的独立性假设和不能表征超过两个特征都是他的限制。同时随着样本数量的增大,图会变得相当的拥挤。
特征交互 (feature interaction)
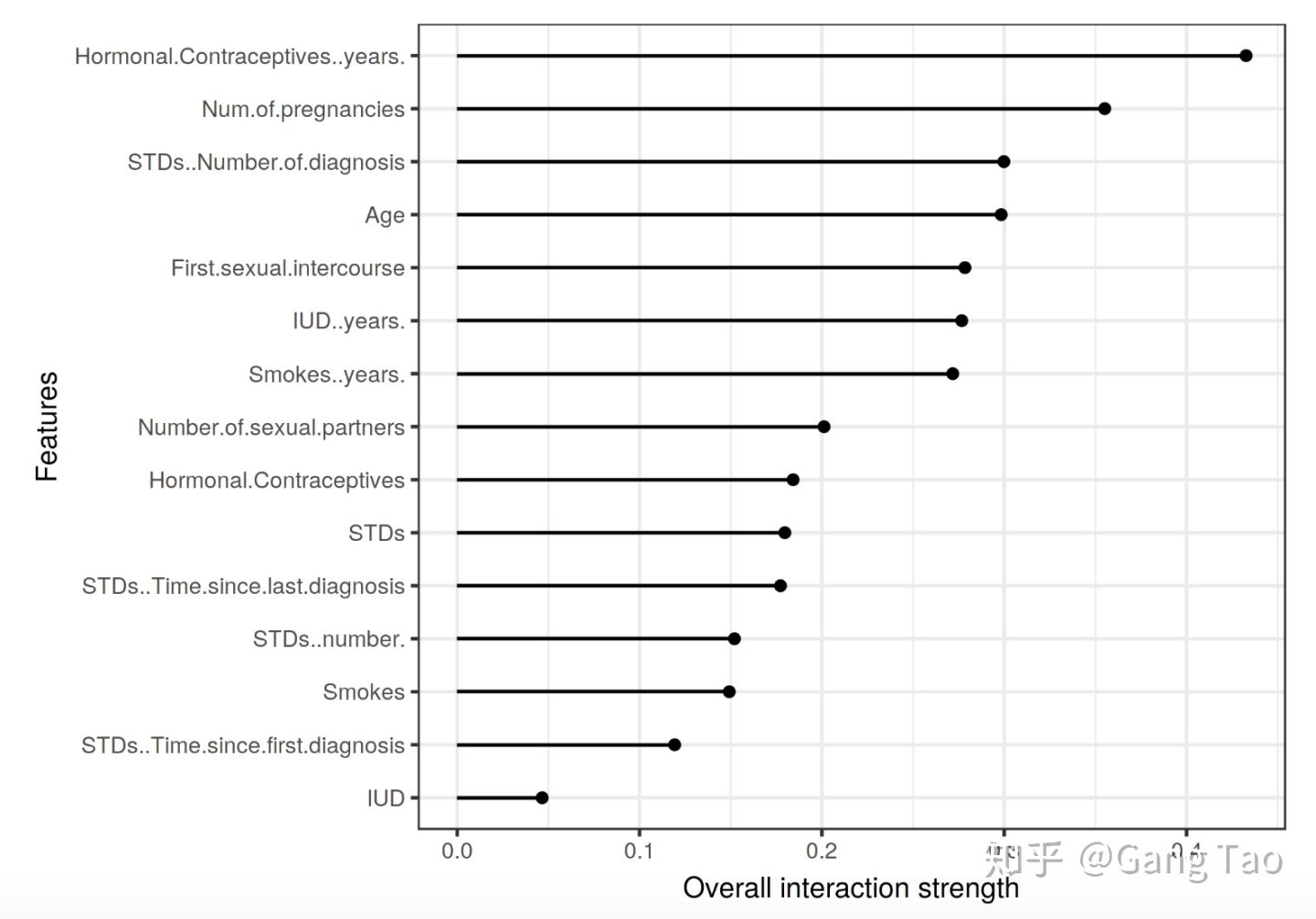
如上图所示的特征交互图反映了,例如一个模型有两个特征,那么模型可以是一个常量 + 只包含第一个特征的项 + 只包含第二个特征的项 + 两个特征的交互项。利用Friedman’s H-statistic的理论,我们可以计算特征交互。
利用H-statistic计算是很耗资源的,结果也不是很稳定。
特征重要性 Feature Importance
特征重要性的定义是当改变一个特征的值的时候,对于预测误差带来的变化。怎么理解呢?当我们改变一个特征,预测误差发生了很大的变化,说明该特征又很大的影响力,而相反的,如果改变另一个特征的值,对于预测结果的误差没有什么影响,那说明这个特征无关紧要。
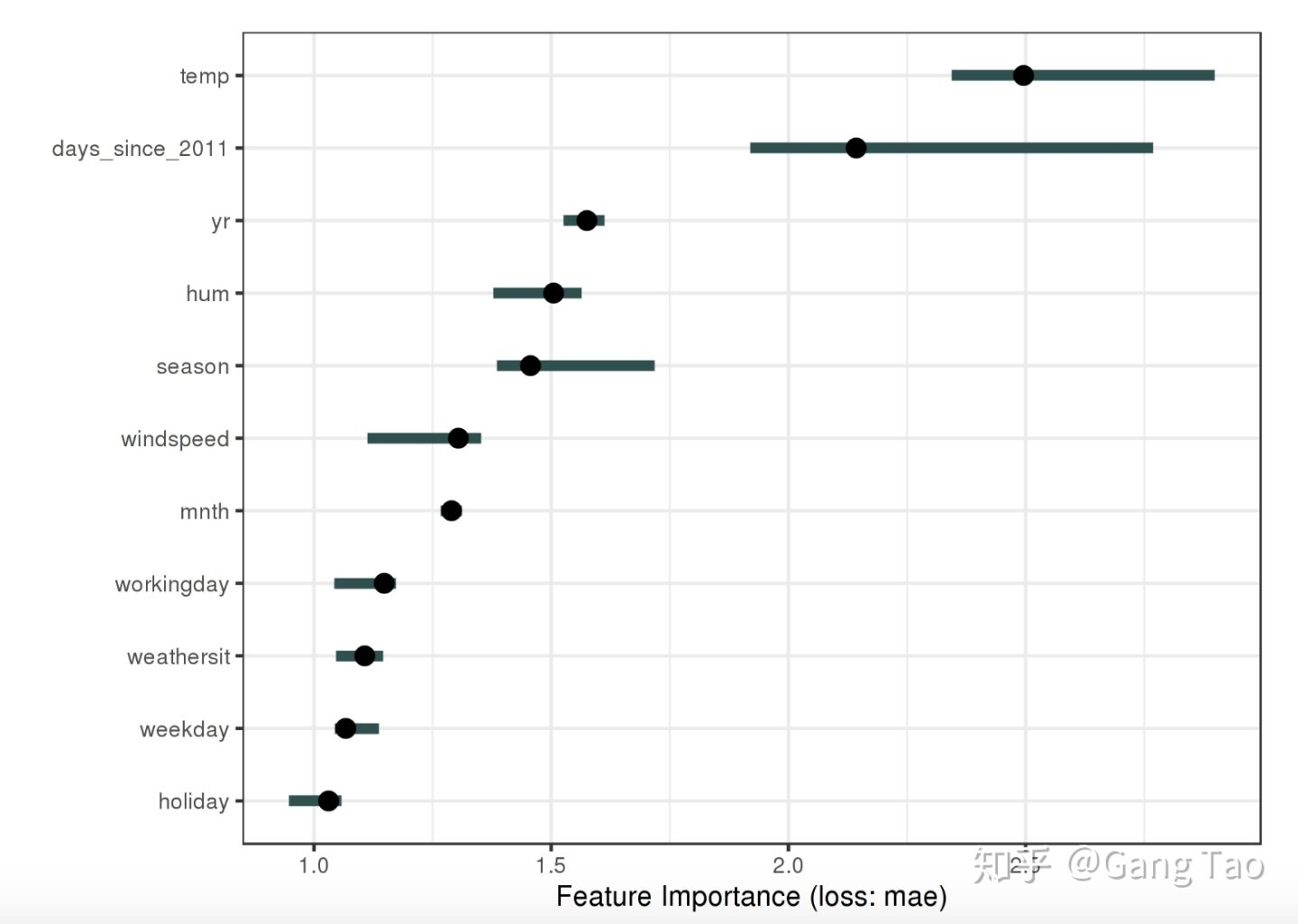
上图是一个特征重要性的图示。
特征重要性提供了一个高度概括的对模型的洞察,它包含了所有特征的交互,计算特征重要性不需要重新训练模型。计算这个值需要数据包含真实结果。
Shapley Values
Shapley值是一个很有趣的工具,他假定每一个特征就好像游戏中的一个玩家,每个玩家对于预测的结果都有一定的贡献。对于每一个预测结果,Shapley值给出每一个特征对于这个预测结果的贡献度。

下图是一个Shapley Value的例子。
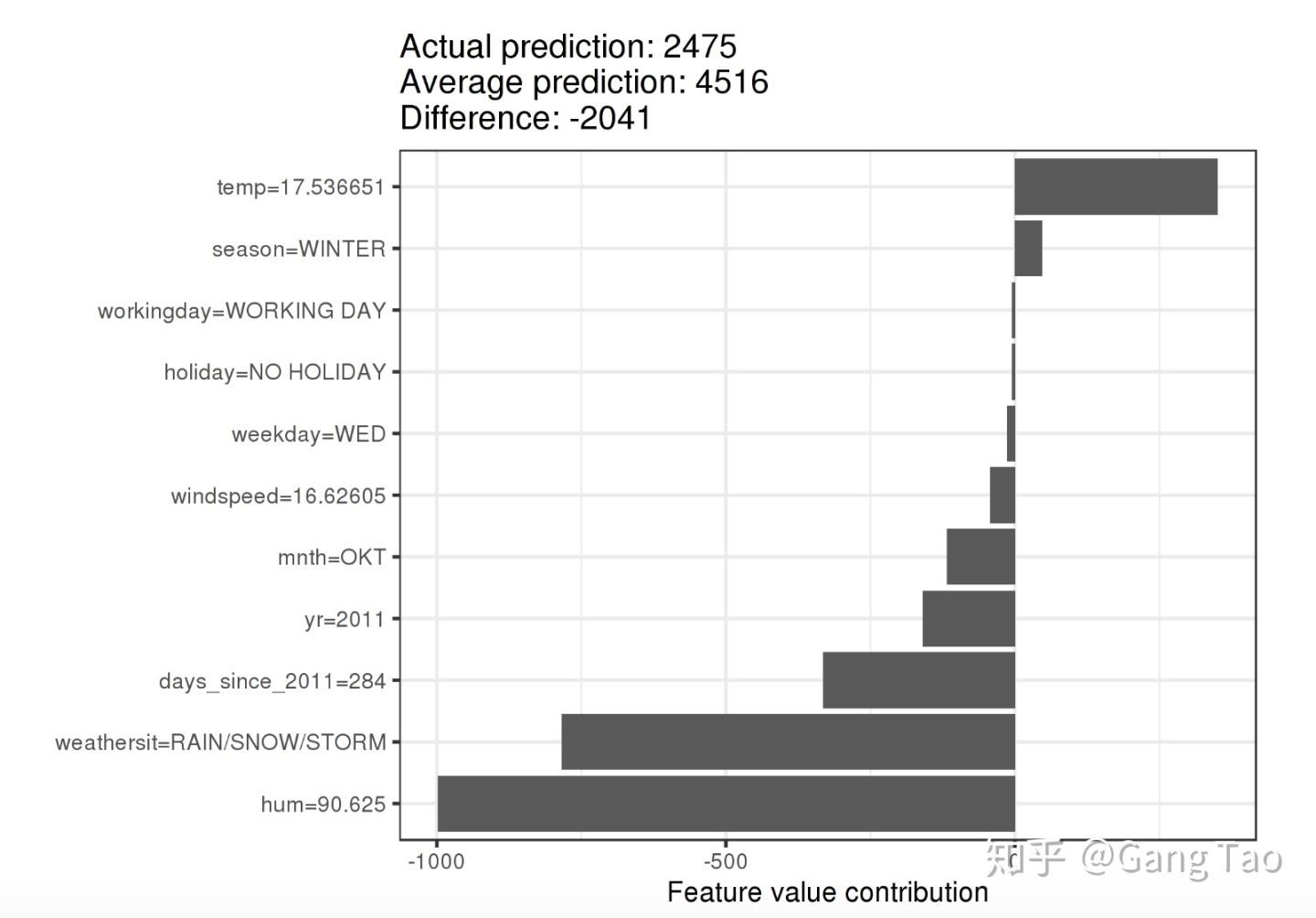
Shapley提供了对于每一个特征的完整的解释。但是同样很耗计算资源,而且要求使用所有的特征。
替代模型(Surrogate Model)
替代模型就是用一个可解释的更简单的模型,对于黑盒模型的输入和预测训练出一个替代品,用这个模型来解释复杂的黑盒模型。
替代模型的训练过程如下:
- 选择一个数据集X(可以和训练集相同或者不同,无所谓)
- 用训练好的黑盒模型预测出Y
- 选择一个可解释的模型,如线性回归或者决策树
- 用之前的数据集X和预测Y训练这个可解释模型
- 验证可解释模型和黑盒模型的差异
替代模型很灵活,很直观也很容易实现。但是替代模型是对黑盒模型的解释,而不是对于数据的解释。
基于样本的解释
反事实解释 (Counterfactual)
反事实解释就像是说“如果X没有发生,Y也就不会发生”
反事实的解释在特征和预测结果中建立一个因果关系。如上图所示。
我们通过改变一个样本的一个特征,然后观察预测结果的变化。google的what if 工具,可以帮助我们做这样的分析。
另外推荐这本书:The Book of Why : The New Science of Cause and Effect

对抗样本 (Adversarial)
对抗样本是指当对一个样本的某一个特征值作出一个微小的变化而使得整个模型作出一个错误的预测。对抗样本的目标是欺骗模型,黑客攻击机器学习模型的手段往往就是找到这些对抗样本。

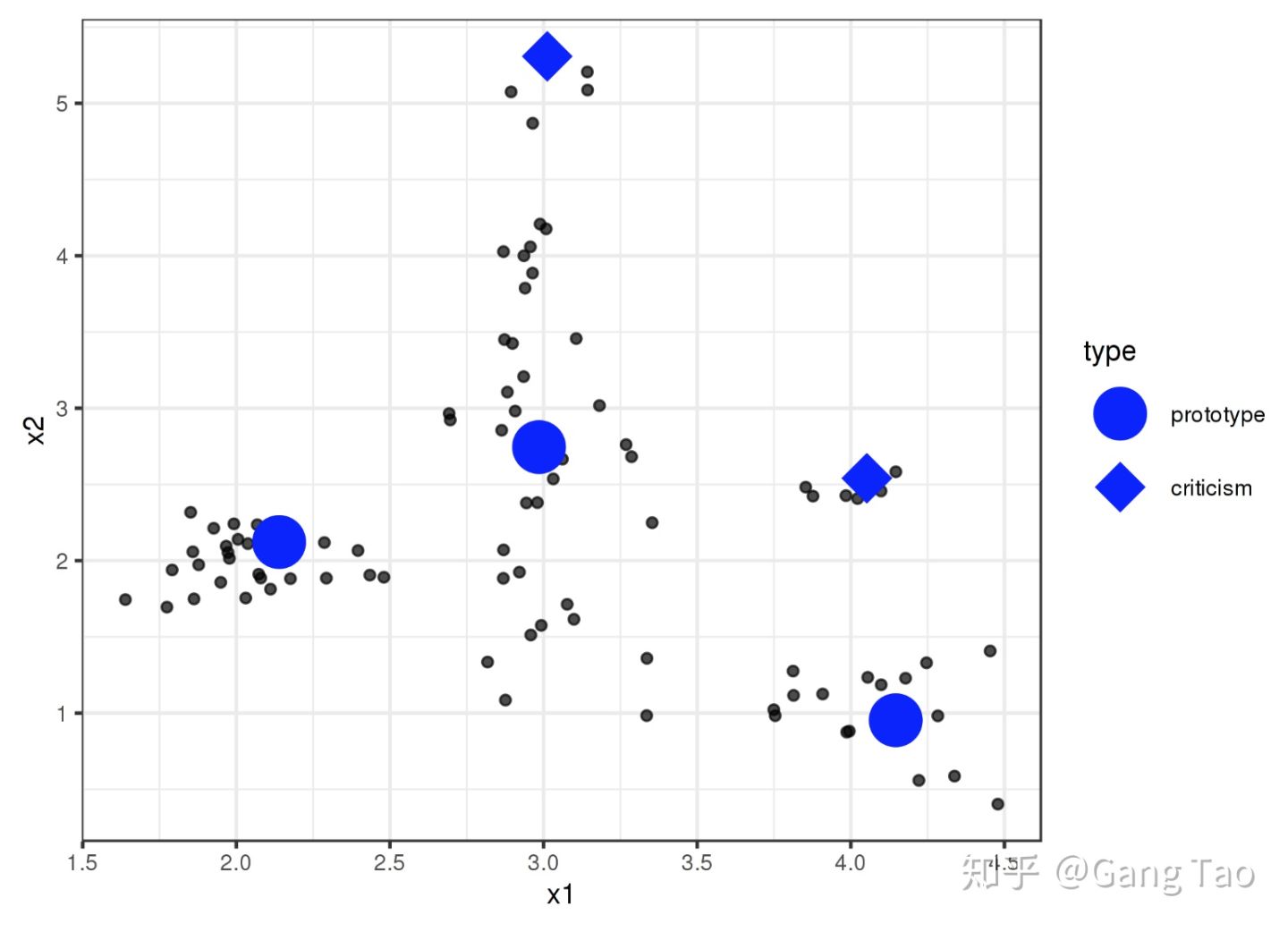
原型和批评 (Prototypes and Criticisms)
原型是一个数据点,它可以代表所有的其它点。而一个批评点是指不能被一组原型有效代表的数据点。
有影响力的实例(Influential Instances)
机器学习的模型是训练数据的产出,删除任何一个训练数据都往往会影响训练结果。如果删除某一个训练数据对模型产生饿巨大的影响,那么我们称这个点为有影响力的点。对有影响力的点的分析也往往可以帮助我们解释模型。
总结
本文介绍了可解释机器学习的基本概念和方法,希望对小伙伴们有所帮助。
参考
- Interpretable Machine Learning :A Guide for Making Black Box Models Explainable
- Machine Learning Explainability :Extract human understandable insights from any Machine Learning model
- https://ai.yanxishe.com/page/Te
原文:https://zhuanlan.zhihu.com/p/71803324
既然来了,说些什么?