商汤的数字人研究,在CVPR上成了爆款
在 CVPR 大会上,看数字人技术的最新趋势。
对表情和手势进行精细建模、让数字人跳舞的算法、用 2D 图片生成 3D 模型…… 最近一段时间,AI 领域里面向元宇宙和数字人的新技术越来越多。
人工智能最重要学术会议之一——CVPR 2022 这几天正在进行过程中,今年大会获得的投稿数量超过一万,接收论文数量超过 2000 篇,是历届规模最大的一次。

在大会上,商汤科技及其联合实验室有 71 篇论文被录用,其中近四分之一为 Oral(口头报告)论文。值得关注的是,这些最新研究中有很多覆盖 3D 数字人、三维视觉等前沿领域,它们正在引领元宇宙领域的技术应用趋势。
在未来的 AR 和 VR 环境中,我们需要高质量的沉浸式内容,实现高效率、低成本的时空拓展体验,这意味着应用自动生成内容的 AI 技术几乎是唯一可行的方式。在 AI 研究者社区中,近期的一些进展让人眼前一亮。
让数字人自己学会跳舞
迄今为止,我们看到的数字人大多数时候只会站在一边发表自己的观点,但生而为「人」,自然的交流能力并不是全部,能不能让虚拟人物的动作不依赖于动作捕捉,而是完全由 AI 自动生成动作呢?
想要驱动 3D 角色跟随音乐自动跳舞,其难点在于生成的舞蹈动作不仅在空间上要保证动作的标准与美感,还需要在时间上保持与不同音乐节奏的一致性。因此这是一个极具挑战性的任务。

来自南洋理工大学、中山大学、UCLA 和商汤的研究者们在论文《Bailando: 3D Dance Generation via Actor-Critic GPT with Choreographic Memory》中提出了一种音乐到舞蹈的新框架 Bailando,分别通过「编舞记忆」和「演员 – 评论家」(Actor-Critic)GPT 解决上述「空间」与「时间」的挑战,实现高质量的 AI 编舞。
在此之前的大多数相关研究都希望通过设计一个巧妙的网络,直接将音乐映射到高维连续的人体姿态空间中实现编舞。但由于映射的目标空间既包含标准的舞姿,又包含了舞蹈动作之外的非标准姿势,此类方法在实践中通常不稳定,容易回归到非标准姿势上(比如僵住或者奇怪的抖动)。

为了将动作限制在人类舞蹈的范围内,一些研究收集了真实舞蹈片段作为舞蹈单元,并通过对这些单元进行排列组合实现编舞。然而舞蹈单元的收集不仅需要耗费大量人工,而且通过此类方法收集得到的舞蹈单元的节拍、速度都是固定的,不能复用到不同节奏的音乐。
针对上述问题,舞蹈生成框架 Bailando 中设计了两个主要组件:「编舞记忆和(Actor-Critic)GPT。
首先是「编舞记忆」模块,为了解决空间挑战,Bailando 通过对舞蹈数据进行非监督学习的方式,总结出仅标准舞姿的子空间,将映射的目标空间限定在标准舞蹈动作上。值得注意的是,新方法没有人工手动标记舞蹈单元,而是利用无监督学习的方式将 3D 关节序列编码和量化为码本,学习出舞蹈中重要且可复用的舞蹈元素。
为了进一步扩大舞蹈记忆可以表示的范围,研究人员将 3D 姿势划分为上半身和下半身的组合让 AI 分别进行学习,这样一段舞蹈可以表示为一系列成对的姿势编码。
然后,为了将这些编码的舞姿组合成一段舞蹈,作者引入了一个名为 motion GPT 的类 GPT 网络,将音乐转换为舞姿编码序列。由于 3D 姿势在【编舞记忆】中被划分为上下半身,这里还需要通过跨条件因果注意层来增强运动 GPT,以保证上下身的协调性。
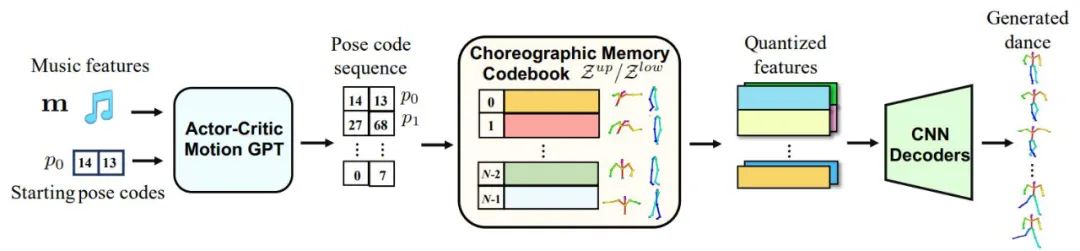
Bailando 的推理过程:给定一段音乐和一个起始姿势编码对,actor-critic GPT 自回归预测未来的姿势编码序列,然后利用【编舞记忆】将编码序列转化为量化特征,最后由基于 CNN 的专用解码器解码出 3D 舞蹈动作。
会做动作的虚拟人只是成功了一半,我们还得让它们跟上节拍。研究者对 GPT 网络引入了一种基于「演员 – 评论家」(Actor-Critic)的强化学习方案,并加入了新设计的节拍对齐奖励功能,使得生成的舞蹈与音乐节拍在时间上同步对齐。
在标准数据集上进行的大量实验表明,新框架在定性和定量上都实现了最好的效果。
通过在数据集上进行的大量实验表明,研究人员提出的新框架在定性和定量上都实现了业界最佳的效果(SOTA)。
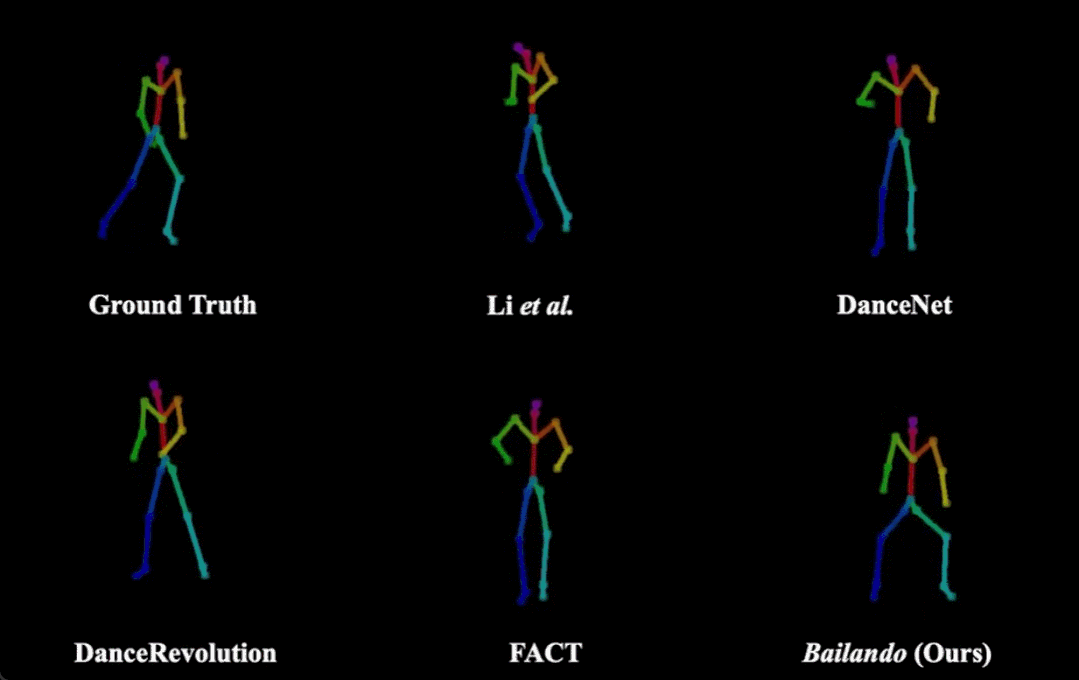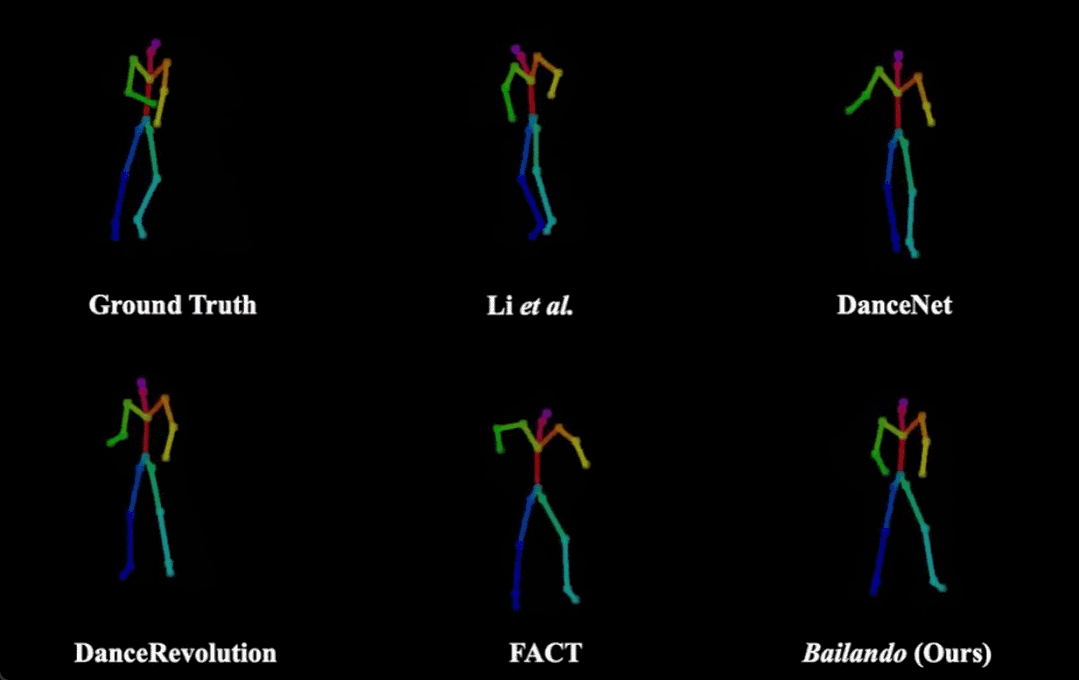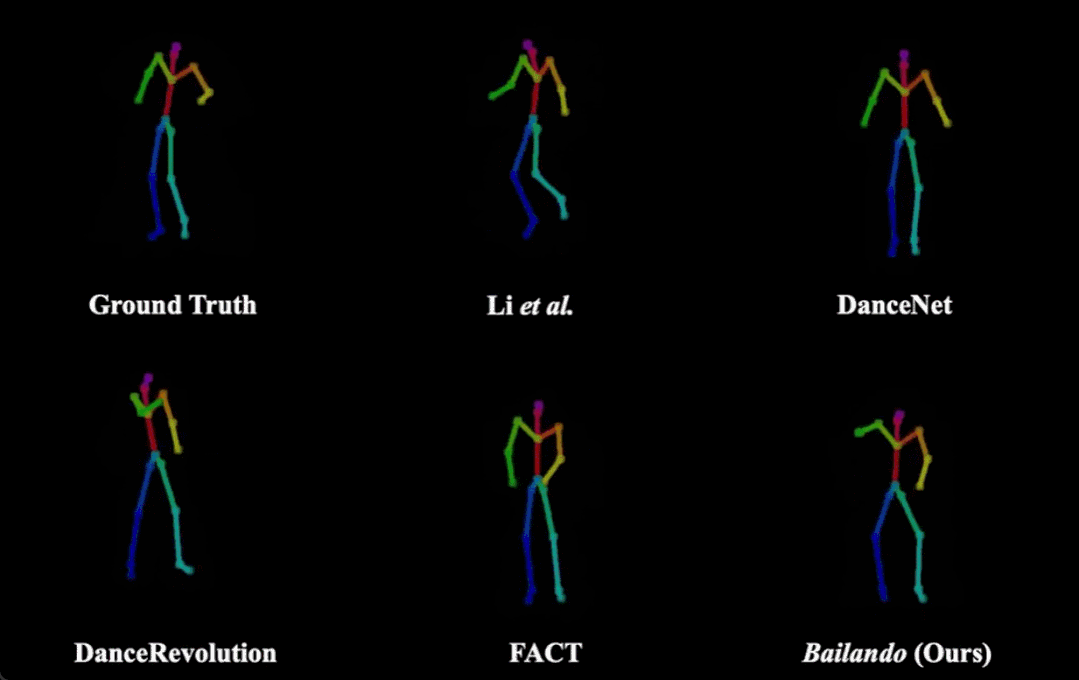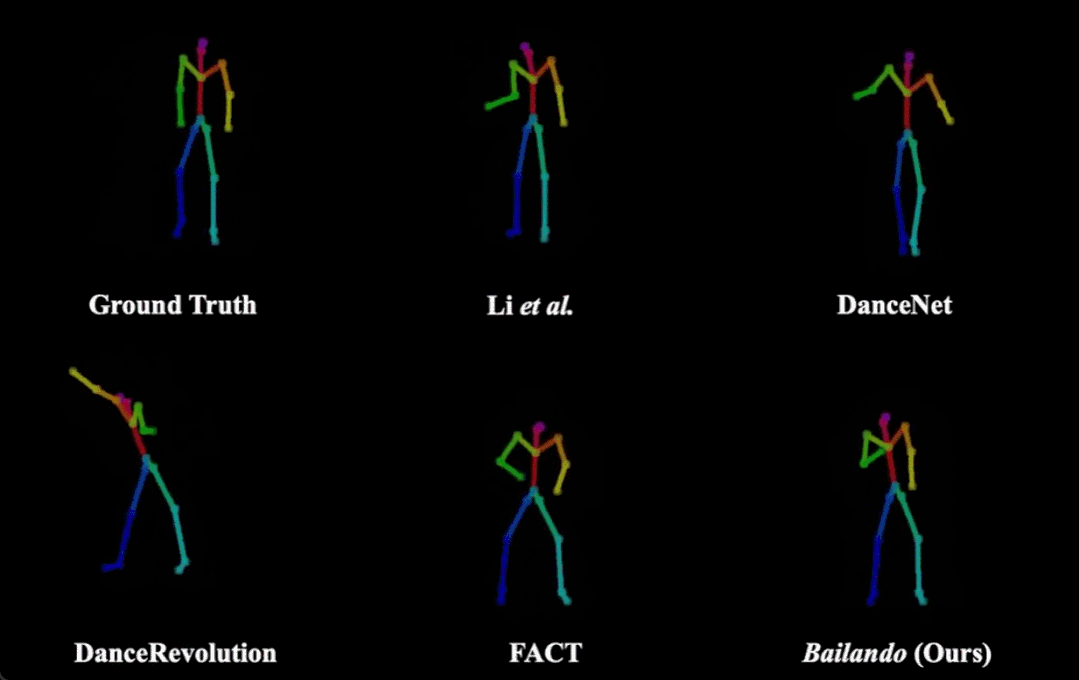
Bailando(右下)和其他方法生成舞蹈效果的对比。
Bailando 可以驱动数字人配合背景音乐跳起舞来,在未来有望成为驱动虚拟主播的底层技术。而在游戏和动漫等环境中,模型生成高质量舞蹈的能力也可以用于辅助或取代人工编舞,大大降低成本。
在元宇宙中复刻人类
除了让「NPC」活动手脚,我们还希望虚拟世界能够更准确地描述自己的形象。
在论文《Not All Tokens Are Equal: Human-centric Visual Analysis via Token Clustering Transformer》中,来自港中文、港大、悉尼大学和商汤的研究人员实现了对人物形象专门优化的视觉理解模型。
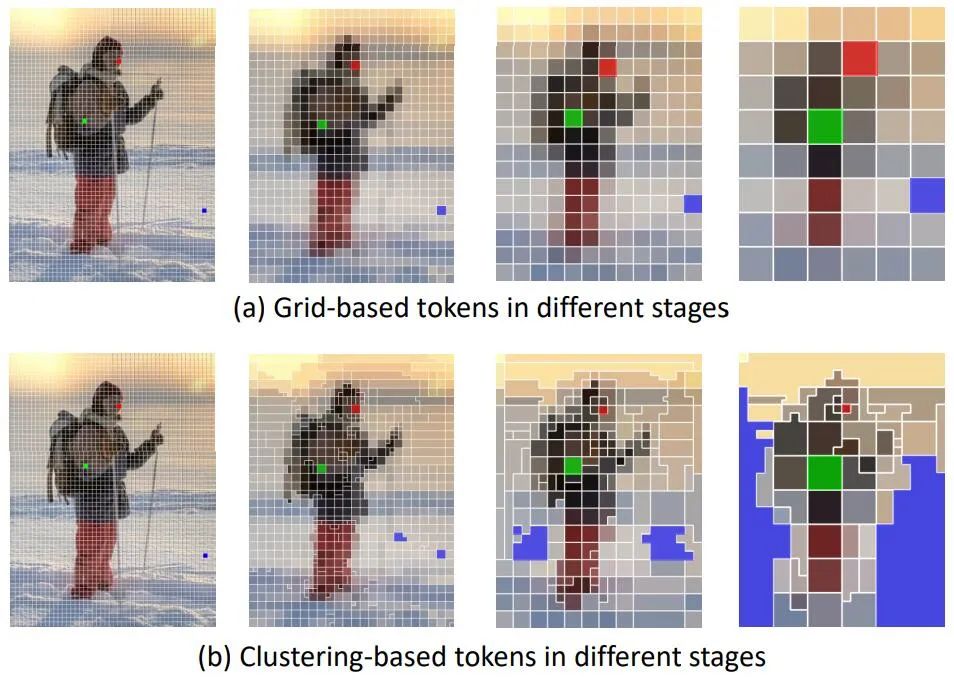
标准网格(a)和 TCFormer 生成的视觉标记(b)之间的比较。
最近一段时间,原本用于自然语言处理领域的 transformer 框架在计算机视觉人脸对齐、姿态估计、3D 人体网格重建等任务中展现了强大的能力。
大多数计算机视觉领域的 transformer 网络直接将图片划分为大小、形状相同的网格区域,并将每一块网格区域用一个 token 表示。这种分割方式忽视了人体与背景、人体不同部位之间的区别,限制了网络在如手势、表情等人体细节上的重建精度。
新研究针对以人为中心的视觉理解任务提出了一种新 transformer 网络结构 TCFormer,其使用一种基于特征聚类的 token 划分方式,能够根据图片的语义信息动态调整 token 的大小、形状和位置,聚焦于重要的图片细节。
TCFormer 在基于图像的人体全身关键点估计、人脸关键点估计和人体三维网格重建任务上都获得了最先进的效果,在人体细节的重建精度上取得了明显的性能提升。
具体来说,为解决细节丢失问题,研究人员提出了一个多阶段 token 聚合方法(MTA),可以有效的方式保留所有阶段的图像细节。MTA 头从上一阶段的 token 开始,逐步对 token 进行上采样并聚合上一阶段特征,直到聚合所有阶段的的特征。聚合后的标记与特征图中的像素一一对应,并被重新整形为特征图供后续处理。
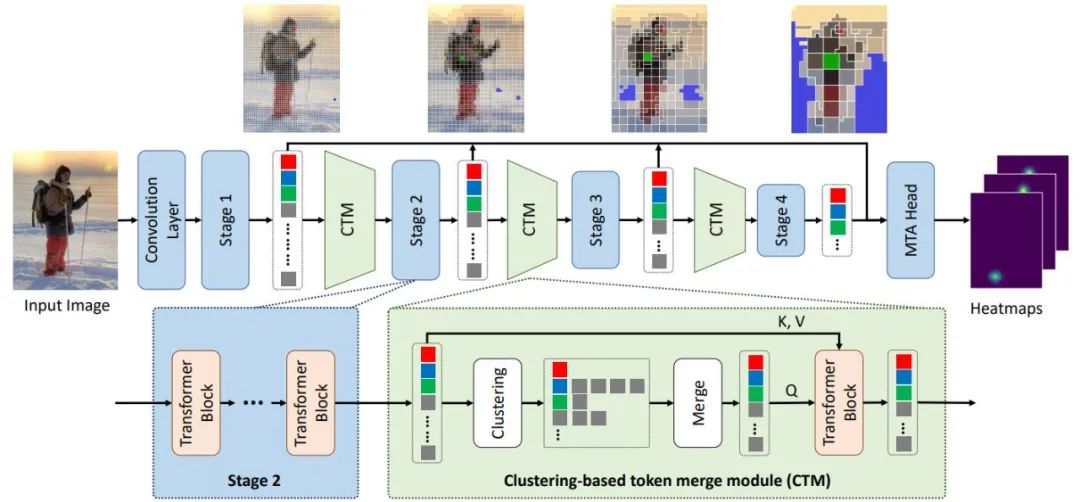
TCFormer 使用多阶段架构,由 4 个分层阶段和一个多阶段 token 聚合 (MTA) 头组成。每个阶段都包含几个堆叠的 transformer 块。在两个相邻阶段之间,插入基于聚类的 token 合并(CTM)块以合并 token,并为下一阶段生成 token。MTA head 聚合来自所有阶段的 token 特征并输出最终的热图。
商汤的研究人员表示,TCFormer 的工作主要关注人体相关的任务,可应用在和人体姿势估计相关的应用中,如 SenseMARS Avatar 、 SenseMARS Agent 等业务都涉及对人体姿势的估计。通过 TCFormer,我们能够更好地捕获细节信息,进而在应用中提供更加精细的姿势估计结果,从而实现更加细致复杂的效果。
在论文中,研究人员在 wholebody 数据集的测试上取得了不小的提升,该任务要求算法同时估计人体、人手、人脸的关键点。TCFormer 的全身姿态估计精度(57.2% AP 和 67.8% AR)高于业内最佳方法,特别是在手部关键点检测上,新方法性能出色,这证明了 TCFormer 在捕获小尺寸关键图像细节方面的能力。
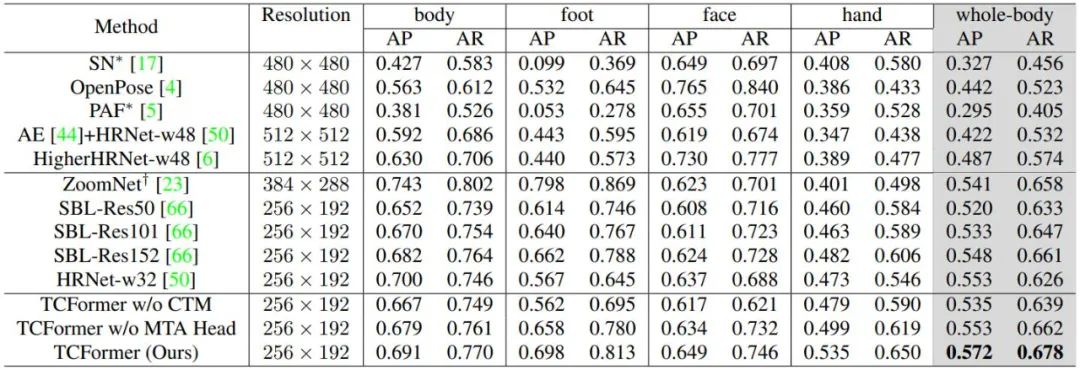
TCFormer 可以同时记录人的动作、表情和手势,进而让虚拟现实和元宇宙应用中的虚拟形象更加生动灵活,人们也可以更加精细地控制各类虚拟角色,进而获得更深的沉浸感。
比如在 VRChat 这类游戏中,若能够凭借图像就生动地重建出用户的动作、表情和手势,游戏的体验就能获得大幅提升。
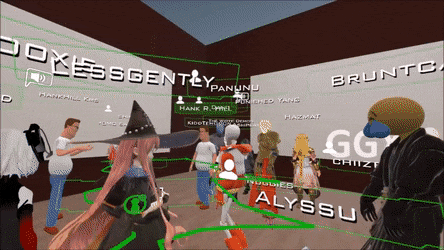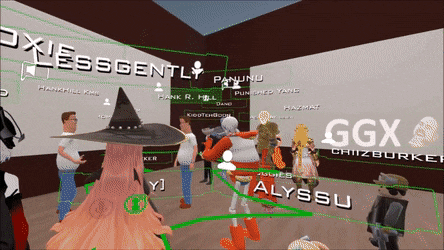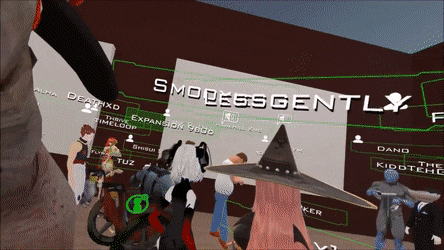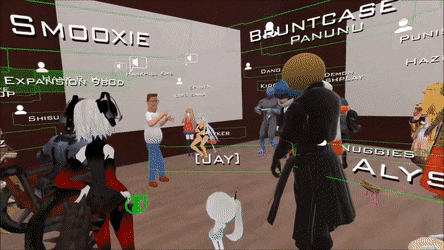
现在的 VRChat 是这个样子,人物的动作并不灵活。
TCFormer 也可以用于帮助虚拟偶像演出,如果人物的形象更加生动,就能产生更好的演出效果。
在体感游戏中,更精细的形象理解也能让用户的操作更加细致,提升沉浸感。在未来通过算法,我们或许不再需要复杂的动作捕捉设备,只需要一个摄像头就能玩元宇宙游戏了。
发展 AI 技术,引领数字人产业
人工智能顶会 CVPR 在 Google Scholar 学术期刊、会议排名上目前位列总榜第四,次于 Nature、新英格兰医学杂志和 Science,超过 Cell 和 JAMA。每年,CVPR 的研究都在预示着计算机视觉技术的方向。
元宇宙是科技领域最近的重要话题,值得注意的是,早在 2020 年 8 月,商汤就提出了自身的混合现实创新平台 SenseMARS。

这是一个用于构建元宇宙的「造物者」平台,包含用于创作元宇宙虚拟化身的 SenseMARS Avatar、支持数字人等元宇宙「原住民」开发的 SenseMARS Agent、用于物理世界数字重建的 SenseMARS Reconstruction 等工具。
目前,SenseMARS 平台已集成了超过 3500 个人工智能模型,支持感知智能及混合与增强现实系统(MARS),创造了全新的元宇宙体验。在 SenseMARS 的加持下,元宇宙中的虚拟人物可以拥有智慧的行为和动作,从而让人与 AI 自然地互动起来。
用 SenseMARS 创造的数字人不仅可以「听懂」人话,还能够通过语言、表情、肢体等动作我们交流。同时,经过不同领域知识数据的训练学习,数字人可以成为我们在各个领域的智能助手。
而 SenseMARS Reconstruction 借助多算法融合,可以让消费级电子设备(如手机、运动相机和无人机)高效重建出物理世界的三维模型,从小物体到购物商场、交通枢纽乃至城市都可以实现厘米级的高精度复刻。
商汤数字人落地的应用已经进入了我们的生活。今年 2 月,宁波银行上海分行入职了 001 号数字人员工「小宁」,为银行客户提供各类业务咨询和办理服务。其背后是商汤基于「AI 数字人服务中台」为银行专属打造的全链条服务支持。

据介绍,数字人小宁可以回答超过 550 个常见业务问题,以及由此衍生的超过 3000 个相关业务问题,通过运营管理平台的持续运营优化,每天还可以新增超过 50 个业务相关衍生问题。
在人们的印象里,商汤科技一直以技术领先著称。自 2014 年成立以来,这家公司一直鼓励研究团队将研究与产业落地相结合,在智慧城市、自动驾驶、智慧文旅等领域建立了技术壁垒,推动着行业发展,取得了令人瞩目的成绩。
这样的探索正在延伸到元宇宙中。去年底上市的招股书中,商汤明确指出将在元宇宙平台上重点投入:公司计划将 60% 资金用于增强研发能力,与元宇宙相关投入占比达 40%。其中 20% 用于增强其他人工智能研发能力,包括 SenseMARS 和 SenseAuto。
在人工智能基础设施 AI 大装置启用时,商汤科技联合创始人、首席执行官徐立曾表示,要通过 AI 大装置对海量数据进行拆解和碰撞,深入挖掘潜在价值,从而打破认知和应用的边界。突破边界,就是实现虚拟与现实世界的连接,商汤正在基于自身 AI 技术推动物理世界的全面数字化转型。
构建虚拟世界浪潮将带来新的机会。而在这其中,AI 技术将扮演至关重要的角色。
参考内容:
Bailando 论文:https://arxiv.org/abs/2203.13055
TCFormer 论文:https://arxiv.org/abs/2204.08680
原文:https://mp.weixin.qq.com/s/oVIHA94fR0nrOwVrflQHYw
既然来了,说些什么?