只需3个样本一句话,AI就能定制照片级图像,谷歌在玩一种很新的扩散模型
来自谷歌和波士顿大学的研究者提出了一种「个性化」的文本到图像扩散模型 DreamBooth,能够适应用户特定的图像生成需求。
近来,文本到图像模型成为一个热门的研究方向,无论是自然景观大片,还是新奇的场景图像,都可能使用简单的文本描述自动生成的。
其中,渲染天马行空的的想象场景是一项具有挑战性的任务,需要在新的场景中合成特定主题(物体、动物等)的实例,以便它们自然无缝地融入场景。
一些大型文本到图像模型基于用自然语言编写的文本提示(prompt)实现了高质量和多样化的图像合成。这些模型的主要优点是从大量的图像 – 文本描述对中学到强大的语义先验,例如将「dog」这个词与可以在图像中以不同姿势出现的各种狗的实例关联在一起。
虽然这些模型的合成能力是前所未有的,但它们缺乏模仿给定参考主题的能力,以及在不同场景中合成主题相同、实例不同的新图像的能力。可见,已有模型的输出域的表达能力有限。
 为了解决这个问题,来自谷歌和波士顿大学的研究者提出了一种「个性化」的文本到图像扩散模型 DreamBooth,能够适应用户特定的图像生成需求。
为了解决这个问题,来自谷歌和波士顿大学的研究者提出了一种「个性化」的文本到图像扩散模型 DreamBooth,能够适应用户特定的图像生成需求。
 论文地址:https://arxiv.org/pdf/2208.12242.pdf
论文地址:https://arxiv.org/pdf/2208.12242.pdf
项目地址:https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
该研究的目标是扩展模型的语言 – 视觉字典,使其将新词汇与用户想要生成的特定主题绑定。一旦新字典嵌入到模型中,它就可以使用这些词来合成特定主题的新颖逼真的图像,同时在不同的场景中进行情境化,保留关键识别特征,效果如下图 1 所示。
 具体来说,该研究将给定主题的图像植入模型的输出域,以便可以使用唯一标识符对其进行合成。为此,该研究提出了一种用稀有 token 标识符表示给定主题的方法,并微调了一个预训练的、基于扩散的文本到图像框架,该框架分两步运行;从文本生成低分辨率图像,然后应用超分辨率(SR)扩散模型。
具体来说,该研究将给定主题的图像植入模型的输出域,以便可以使用唯一标识符对其进行合成。为此,该研究提出了一种用稀有 token 标识符表示给定主题的方法,并微调了一个预训练的、基于扩散的文本到图像框架,该框架分两步运行;从文本生成低分辨率图像,然后应用超分辨率(SR)扩散模型。
首先该研究使用包含唯一标识符(带有主题类名,例如「A [V] dog」)的输入图像和文本提示微调低分辨率文本到图像模型。为了防止模型将类名与特定实例过拟合和语义漂移,该研究提出了一种自生的、特定于类的先验保存(preservation)损失,它利用嵌入模型中类的先验语义,鼓励模型生成给定主题下同一类中的不同实例。
第二步,该研究使用输入图像的低分辨率和高分辨率版本对超分辨率组件进行微调。这允许模型对场景主题中小而重要细节保持高保真度。
我们来看一下该研究提出的具体方法。
方法介绍
给定 3-5 张捕获的图像,这些图像没有文字描述,本文旨在生成具有高细节保真度和由文本提示引导变化的新图像。该研究不对输入图像施加任何限制,并且主题图像可以具有不同的上下文。方法如图 3 所示。输出图像可对原始图像进行修改,如主题的位置,更改主题的属性如颜色、形状,并可以修改主体的姿势、表情、材质以及其他语义修改。
更具体的说,本文方法将一个主题(例如,一只特定的狗)和相应类名(例如,狗类别)的一些图像(通常 3 – 5 张图)作为输入,并返回一个经过微调 / 个性化的文本到图像模型,该模型编码了一个引用主题的唯一标识符。然后,在推理时,可以在不同的句子中植入唯一标识符来合成不同语境中的主题。
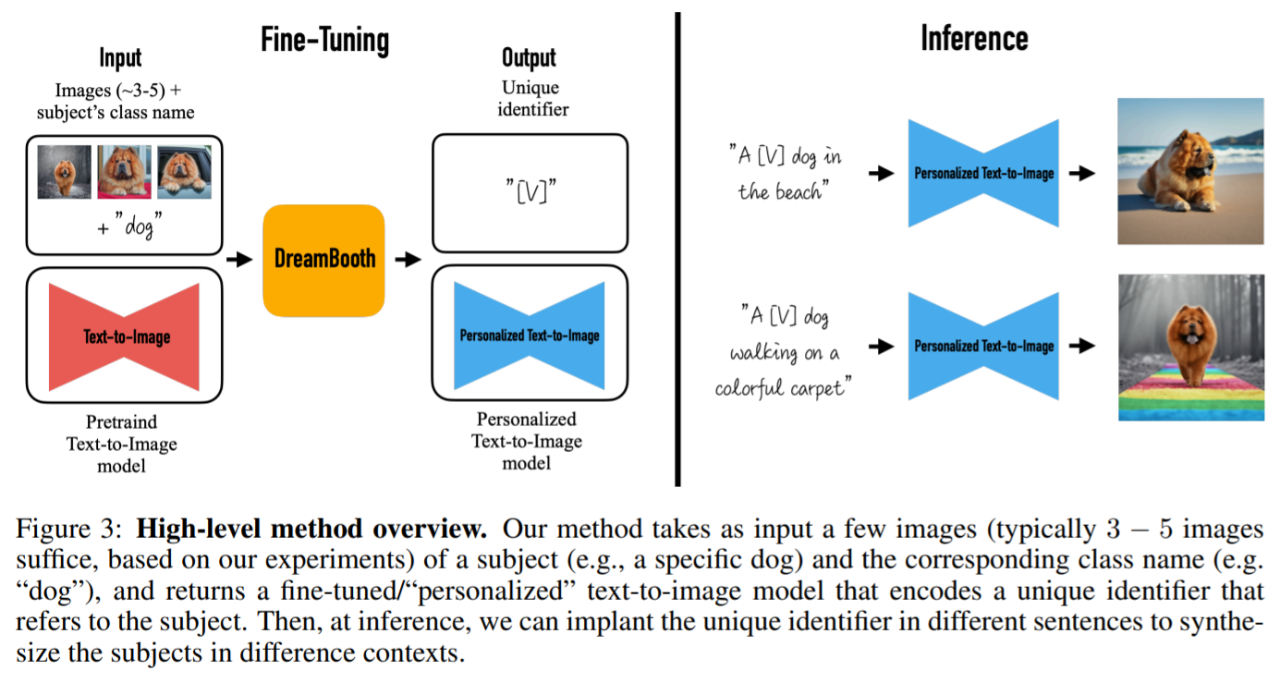 该研究的第一个任务是将主题实例植入到模型的输出域,并将主题与唯一标识符绑定。该研究提出了设计标识符的方法,此外还设计了一种监督模型微调过程的新方法。
该研究的第一个任务是将主题实例植入到模型的输出域,并将主题与唯一标识符绑定。该研究提出了设计标识符的方法,此外还设计了一种监督模型微调过程的新方法。
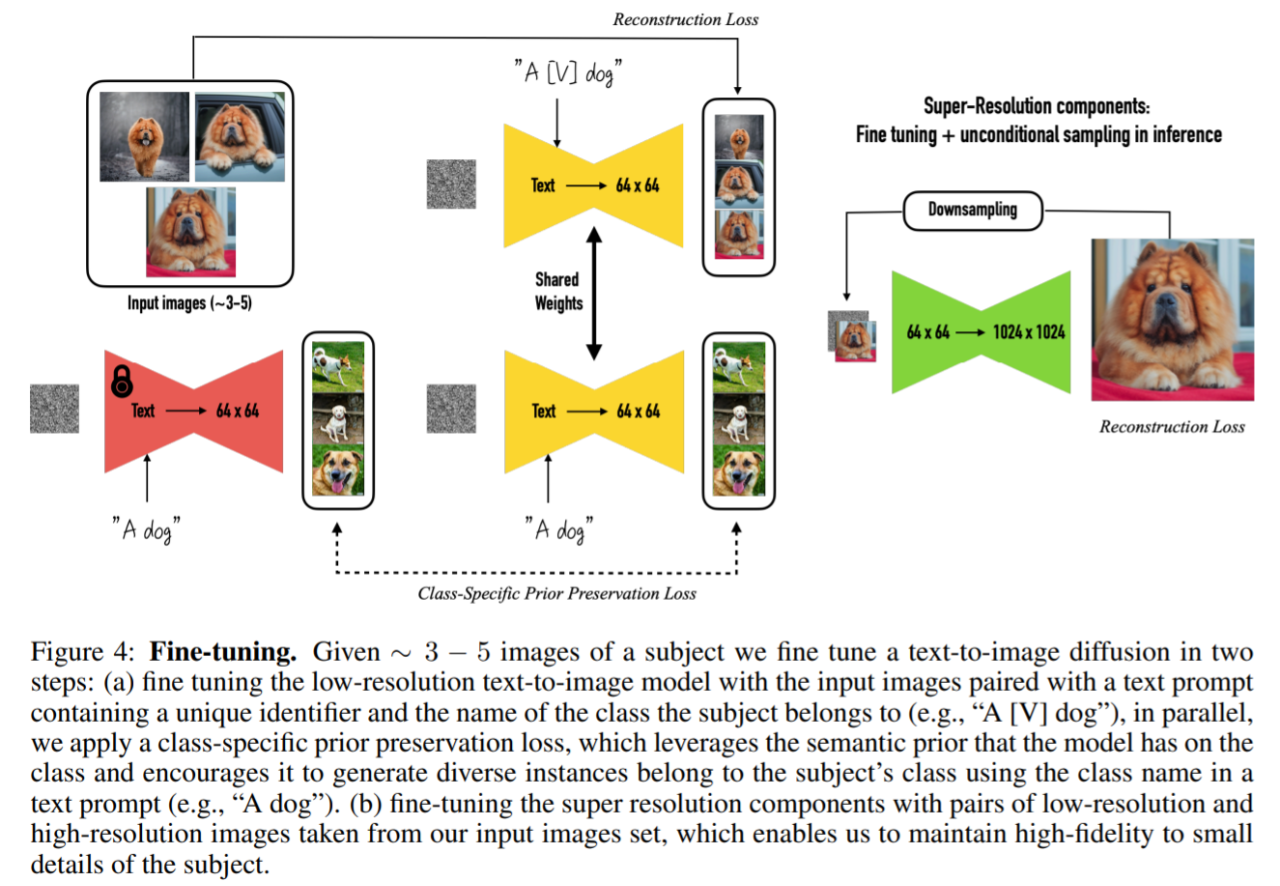
为了解决图像过拟合以及语言漂移问题,该研究还提出了一种损失( Prior-Preservation Loss ),通过鼓励扩散模型不断生成与主题相同的类的不同实例,从而减轻模型过拟合、语言漂移等问题。
为了保留图像细节,该研究发现应该对模型的超分辨率(SR)组件进行微调,本文在经过预训练的 Imagen 模型的基础上来完成。具体过程如图 4 所示,给定同一主题的 3-5 张图像,之后通过两个步骤微调文本到图像的扩散模型:
 稀有 token 标识符表示主题
稀有 token 标识符表示主题
该研究将主题的所有输入图像标记为「a [identifier] [class noun]」,其中 [identifier] 是链接到主题的唯一标识符,而 [class noun] 是主题的粗略类别描述符 (例如猫、狗、手表等)。该研究在句子中特别使用了类描述符,以便将类的先验与主题联系起来。
效果展示
下面是 Dreambooth 一个稳定扩散的实现(参考项目链接)。定性结果:训练图像来自「Textual Inversion」库:

训练完成后,在「photo of a sks container」提示下,模型生成的集装箱照片如下:

在提示中加个位置「photo of a sks container on the beach」,集装箱出现在沙滩上;

绿色的集装箱颜色太单一了,想加点红色,输入提示「photo of a red sks container」就能搞定:

输入提示「a dog on top of sks container」就能让小狗坐在箱子里:

下面是论文中展示的一些结果。生成不同画家风格的关于狗狗的艺术图:
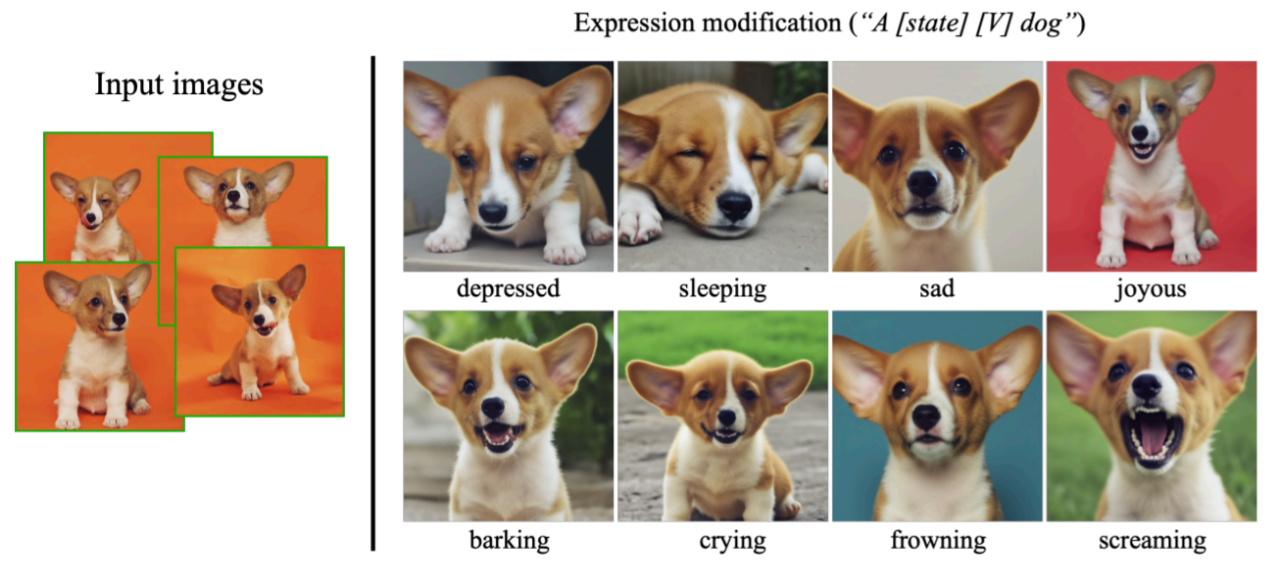
 该研究还可以合成输入图像中没有出现的各种表情,展示了模型的外推能力:
该研究还可以合成输入图像中没有出现的各种表情,展示了模型的外推能力:
想要了解更多细节,请参考原论文。
原文:https://mp.weixin.qq.com/s/tHd5pdJPEfdVpHlzbAantw
等更到小红书🍠~🎸