ChatGPT要把数据标注行业干掉了?比人便宜20倍,而且还更准
而且用的还是旧版本,GPT-4 都还没出手。
没想到,AI 进化之后淘汰掉的第一批人,就是帮 AI 训练的人。
很多 NLP 应用程序需要为各种任务手动进行大量数据注释,特别是训练分类器或评估无监督模型的性能。根据规模和复杂程度,这些任务可能由众包工作者在 MTurk 等平台上以及训练有素的标注人(如研究助理)执行。
我们知道,语言大模型(LLM)在规模到达一定程度之后可以「涌现」—— 即获得此前无法预料的新能力。作为推动 AI 新一轮爆发的大模型,ChatGPT 在很多任务上的能力也超出了人们的预期,其中就包括给数据集做标注这种自己训练自己的工作。
近日,来自苏黎世大学的研究者证明了 ChatGPT 在多项注释任务(包括相关性、立场、主题和框架检测)上优于众包工作平台和人类工作助理。
此外,研究人员还做了计算:ChatGPT 的每条注释成本不到 0.003 美元 —— 大约比 MTurk 便宜 20 倍。这些结果显示了大型语言模型在大幅提高文本分类效率方面的潜力。

论文链接:https://arxiv.org/abs/2303.15056
研究细节
许多 NLP 应用程序需要高质量的标注数据,特别是用于训练分类器或评估无监督模型的性能。例如,研究人员有时需要过滤嘈杂的社交媒体数据以获得相关性,将文本分配给不同的主题或概念类别,或者衡量他们的情绪立场。无论用于这些任务的具体方法是什么(监督、半监督或无监督学习),都需要准确地标注数据来构建训练集,或用其作为评估性能的黄金标准。
对此,人们通常的处理方式是招募研究助理,或者使用 MTurk 这样的众包平台。OpenAI 在打造 ChatGPT 时,也将负面内容问题分包给了肯尼亚的数据标注机构,进行了大量标注训练才敢正式上线。
由瑞士苏黎世大学提交的这篇报告探讨了大语言模型(LLM)在文本标注任务中的潜力,并重点关注了 2022 年 11 月发布的 ChatGPT。它证明了零样本(即没有任何额外训练)ChatGPT 在分类任务上优于 MTurk 标注 ,而成本仅需人工的几十分之一。
研究人员使用了之前的研究收集的 2382 条推文样本。这些推文由训练有素的注释者(研究助理)标记为五种不同的任务:相关性、立场、主题和两种框架检测。实验中,研究者将任务作为零样本分类提交给 ChatGPT,并同时给 MTurk 上的众包工作者,然后根据两个基准评估了 ChatGPT 的性能:相对于众包平台上人类工作者的准确性,以及相对于研究助理注释者的准确性。
结果发现,在五分之四的任务上,ChatGPT 的零样本准确率高于 MTurk。对于所有任务,ChatGPT 的编码器协议都超过了 MTurk 和训练有素的注释者。此外在成本上,ChatGPT 比 MTurk 便宜得多:五个分类任务在 ChatGPT(25264 个注释)上的成本约为 68 美元,在 MTurk(12632 个注释)上的成本约为 657 美元。
这么一算,ChatGPT 的每条注释成本约为 0.003 美元,即三分之一美分 —— 比 MTurk 便宜约 20 倍,而且质量更高。鉴于此,我们现在已有可能对更多样本进行注释,或者为监督学习创建大型训练集。根据现有的测试,10 万个注释的成本约为 300 美元。
研究人员表示,虽然需要进一步研究以更好地了解 ChatGPT 和其他 LLM 如何在更广泛的环境中发挥作用,但这些结果表明它们有可能改变研究人员进行数据注释的方式,并破坏 MTurk 等平台的部分业务模型。
实验过程
研究人员使用了包含 2382 条推文的数据集,这些推文是之前针对内容审核相关任务的研究手动注释的。具体来说,训练有素的注释者(研究助理)为五个具有不同类别数量的概念类别构建了黄金标准:推文与内容审核问题的相关性(相关 / 不相关);关于第 230 条(美国 1996 年《通信规范法》的一部分)的立场,这是美国互联网立法的一个关键部分;主题识别(六类);第一组框架(内容审核作为问题、解决方案或中性);以及第二组框架(十四类)。
然后,研究人员使用 ChatGPT 和在 MTurk 上招募的众包工作者进行了这些完全相同的分类。对于 ChatGPT 进行了四组标注。为了探索控制输出随机程度的 ChatGPT 温度参数的影响,这里使用默认值 1 和 0.2 进行注释,这意味着随机性较小。对于每个温度值,研究人员进行了两组注释来计算 ChatGPT 的编码器协议。
对于专家,该研究找到了两名政治学研究生,对所有五项任务对推文进行注释。对于每项任务,编码员都获得了相同指令集,其被要求逐个任务独立地注释推文。为了计算 ChatGPT 和 MTurk 的准确性,对比只考虑了两个训练有素的注释者都同意的推文。
对于 MTurk,研究的目标是选择最好的工作者群体,特别是通过筛选被亚马逊归类为「MTurk 大师」、好评超过 90% 且在美国的工作者。
该研究使用「gpt-3.5-turbo」版本的 ChatGPT API 对推文进行分类。注释于 2023 年 3 月 9 日至 3 月 20 日之间进行。对于每个注释任务,研究人员有意避免添加任何特定于 ChatGPT 的提示(prompt),例如「让我们逐步思考」,以确保 ChatGPT 和 MTurk 众包工作者之间的可比性。
在测试了几种变体之后,人们决定使用这样的提示将推文一条一条地提供给 ChatGPT:「这是我选择的推文,请将其标记为 [任务特定说明(例如,说明中的主题之一)]。此外,该研究中每条推文收集了四个 ChatGPT 响应,也为每条推文创建一个新的聊天会话,以确保 ChatGPT 结果不受注释历史记录的影响。
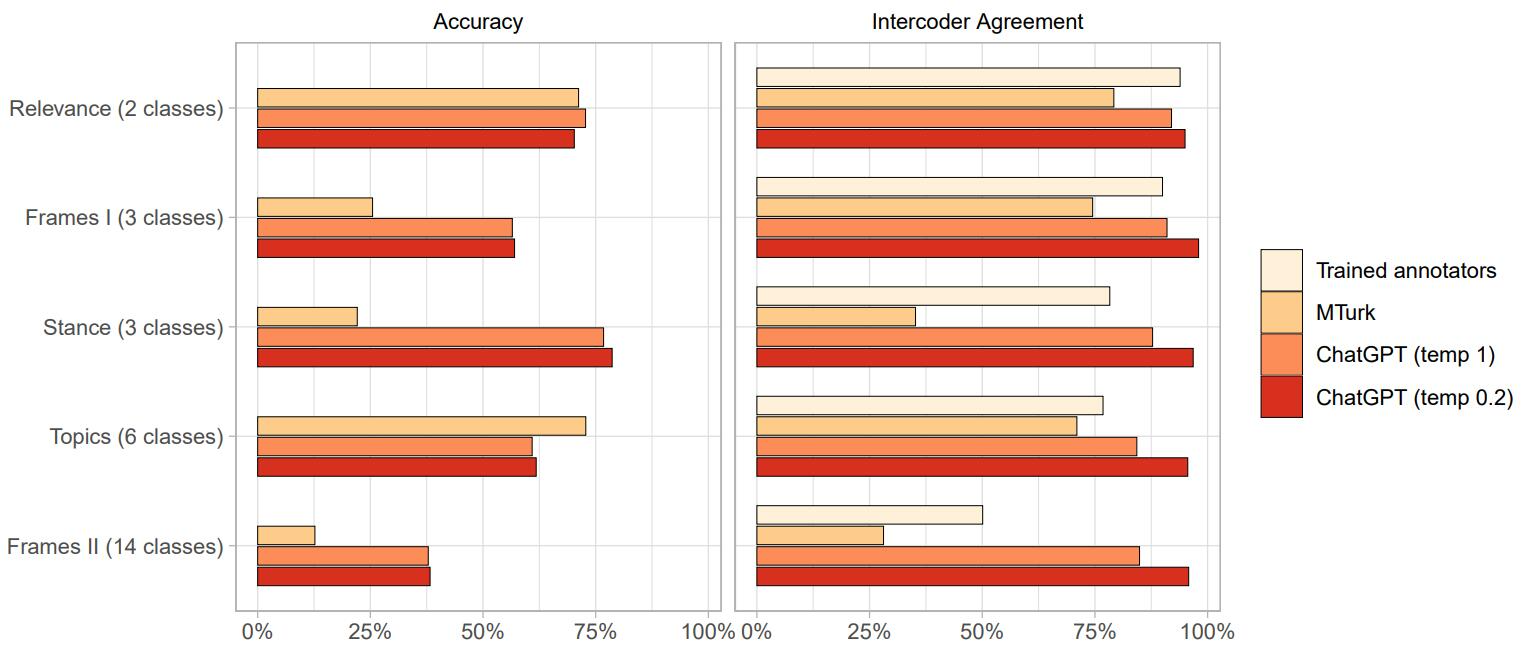
图 1. 与 MTurk 上高分标注人相比,ChatGPT zero-shot 的文本标注能力。ChatGPT 在五项任务中的四项中的准确性优于 MTurk。
在上图中 ChatGPT 有优势的四项任务中,在一种情况下(相关性)ChatGPT 略有优势,但其性能与 MTurk 非常相似。其他三种情况下(frams I、frams II 和 Stance),ChatGPT 的性能比 MTurk 高 2.2 到 3.4 倍。此外,考虑到任务的难度、类的数量以及注释是零样本的事实,ChatGPT 的准确度总体来说绰绰有余。
对于相关性,有两个类别(相关 / 不相关),ChatGPT 的准确率为 72.8%,而对于立场,有三个类别(正面 / 负面 / 中性)的准确率为 78.7%。随着类别数量的增加,准确性会降低,尽管任务的内在难度也有影响。关于编码器协议,图 1 显示 ChatGPT 的性能非常高,当温度参数设置为 0.2 时,所有任务的性能都超过 95%。这些值高于任何人类,包括训练有素的注释者。即使使用默认温度值 1(这意味着更多的随机性),编码器间一致性始终超过 84%。编码器间一致性和准确性之间的关系是正的,但很弱(皮尔逊相关系数:0.17)。尽管相关性仅基于五个数据点,但它表明较低的温度值可能更适合注释任务,因为它似乎可以提高结果的一致性而不会大幅降低准确性。
必须强调的是,对 ChatGPT 进行测试非常困难。内容审核是一个复杂的主题,需要大量资源。除了立场之外,研究人员还为特定研究目的开发了概念类别。此外,一些任务涉及大量类别,然而 ChatGPT 仍然达到了很高的准确率。
使用模型来注释数据并不是什么新鲜事,在使用大规模数据集的计算机科学研究中,人们经常会标注少量样本然后用机器学习进行扩增。不过在表现超过人类之后,未来我们或许可以更加信任来自 ChatGPT 的判断了。
原文:https://mp.weixin.qq.com/s/Z3cKnGMfN5nD6bZ2PQI2_g
既然来了,说些什么?