Next Thing:角色+模型+流程+接口调用
四月份是目前为止AI发展最快的一个月,因为HuggingGPT、AutoGPT、BabyAGI、Camel、Generative Agents、WebLLM、Alpaca 7B等LLM(大语言模型)项目相继出现在公众视野,而这些项目我们可以看到多个现象:
- HuggingGPT揭示了LLM不仅仅可以用来写总结和邮件,还可以自己调用API完成任务。
- AutoGPT、BabyAGI揭示了被赋予循环调用和具有记忆功能的LLM可以基于用户目标自我生成多个任务并一一解决。
- Camel、Generative Agents揭示了LLM可以被赋予角色设定,然后多角色的协作工作同样可以实现用户的目标。
- WebLLM、Alpaca 7B揭示了将在本地电脑运行LLM并逐步影响各个场景的可能性。
- Prompt工程不仅仅是自然语言,也可以是编程语言(搭建架构甚至系统)。
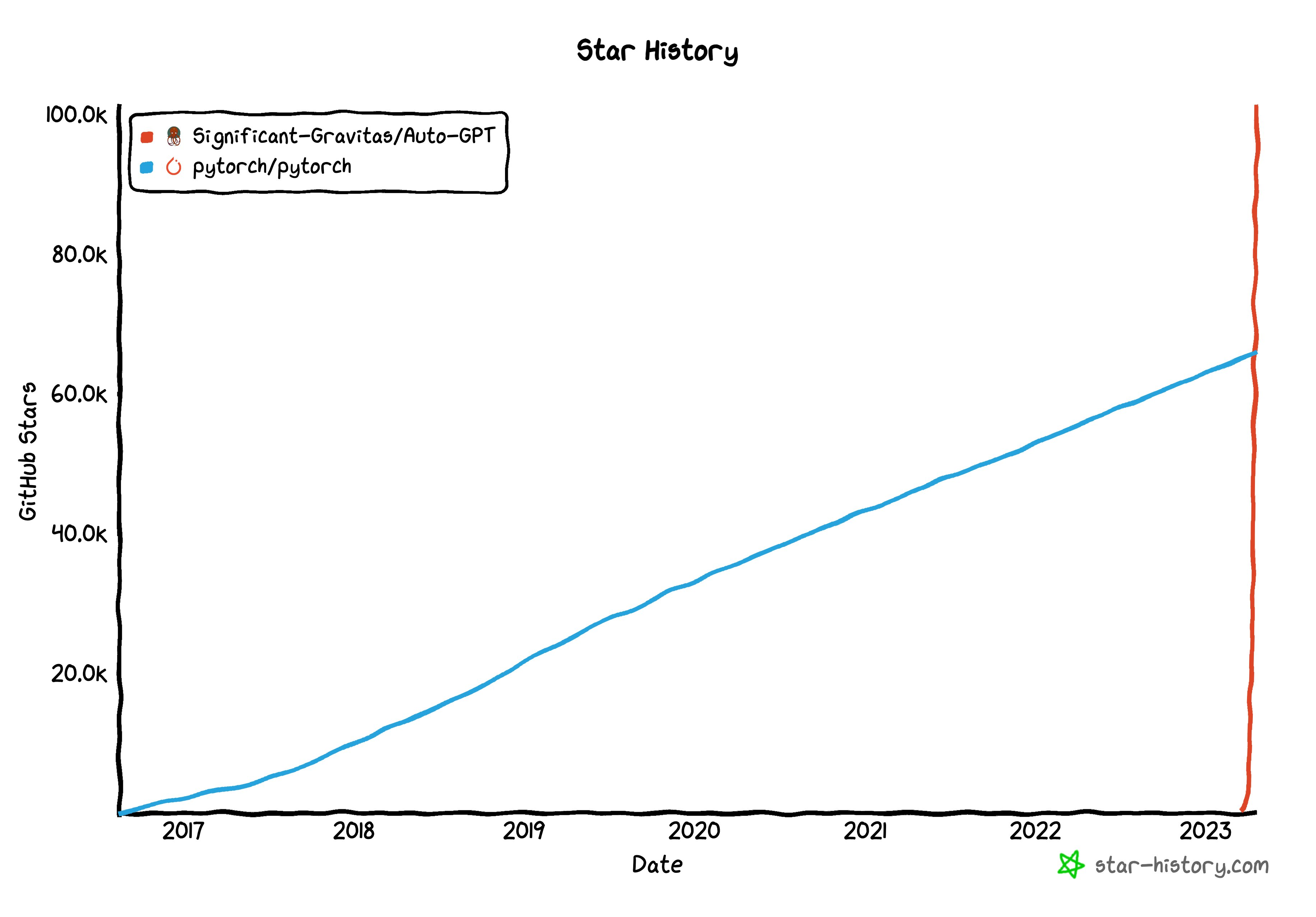
开源将剧烈地加快AI的发展,大家要做好心理准备自己随时受到AI冲击带来的“脑震荡”。AutoGPT在3个月不到的时间里Github的点赞数(Star)超过了100k,如果大家不能理解这个速度有多快,我们拿最出名的深度学习框架Pytorch和AutoGPT做对比:具体可以看下图两个项目的曲线。
为什么HuggingGPT、AutoGPT、BabyAGI、Camel等项目会这么火?因为它们可以理解为AGI(通用人工智能)的雏形:自治系统,也就是说我给机器一个目标,它会自动执行,如果遇到解决不了问题还会自主Google或者自己写代码解决。最近我研究了一下HuggingGPT、BabyAGI、AutoGPT和Camel在框架上的差异,接下来我简单概括一下。
HuggingGPT 的工作流程包括四个阶段。从工作流程来看,HuggingGPT非常适合意图明确或者流程简单的任务,因为它在第一步决定了后面3步是什么,但最终结果会根据不同的预测得出结论。
- 任务规划:使用 ChatGPT 分析用户的请求,了解他们的意图,并将其拆解成可解决的任务。
- 模型选择:为了解决计划的任务,ChatGPT 根据描述选择托管在 Hugging Face 上的 AI 模型。
- 任务执行:调用并执行每个选定的模型,并将结果返回给 ChatGPT。
- 生成响应:最后使用 ChatGPT 整合所有模型的预测,生成 Response。

相比HuggingGPT,AutoGPT和BabyAGI更适合完成意图不明确或者流程需要自行探索的任务,因为它们在框架上参考了人的自主决策过程:“行动→观察结果→思考→决定下一步行动”。AutoGPT和BabyAGI是如何实现该过程的?它们同时采用了LLM循环“读取记忆”、“创建新任务”和“完成任务”的方法,差异点在于前者可以联网获取信息而后者只能依赖GPT,以及前者采用了GPT作为记忆的容器而后者采用了Langchain。
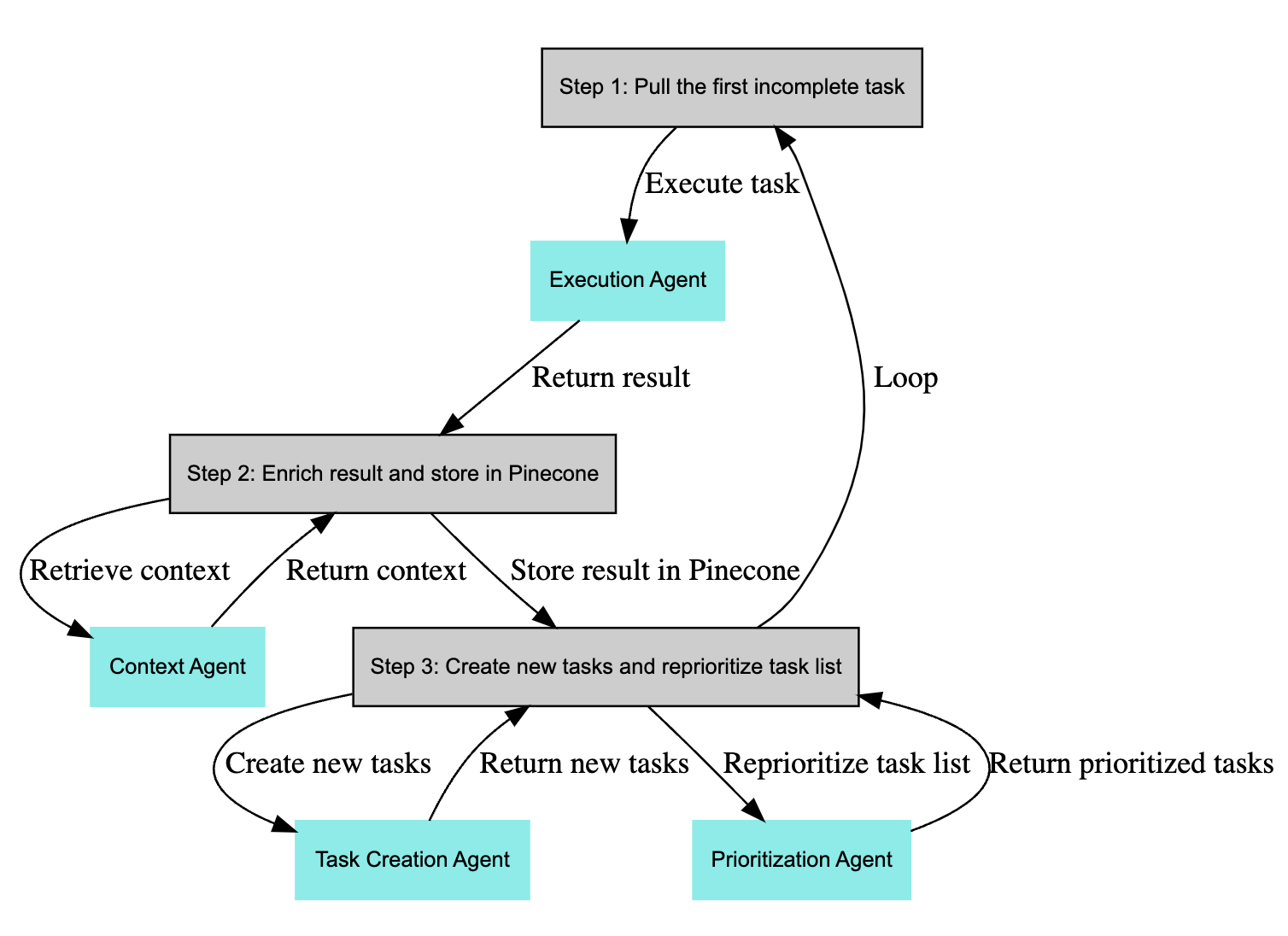
AutoGPT和BabyAGI两个项目更像是一个智能体在为你服务,两个项目的核心是通过Prompt工程构建一个智能体的自主决策系统。我们从开源代码来看,目前每个项目的核心代码都只有100多行,而且绝大部分都是Prompt,所以我在前面提到了可以利用Prompt工程实现一个交互系统,而且这是一个自主交互系统,跟我们当前的APP和操作系统完全不一样。下面是BabyAGI的实现机制:
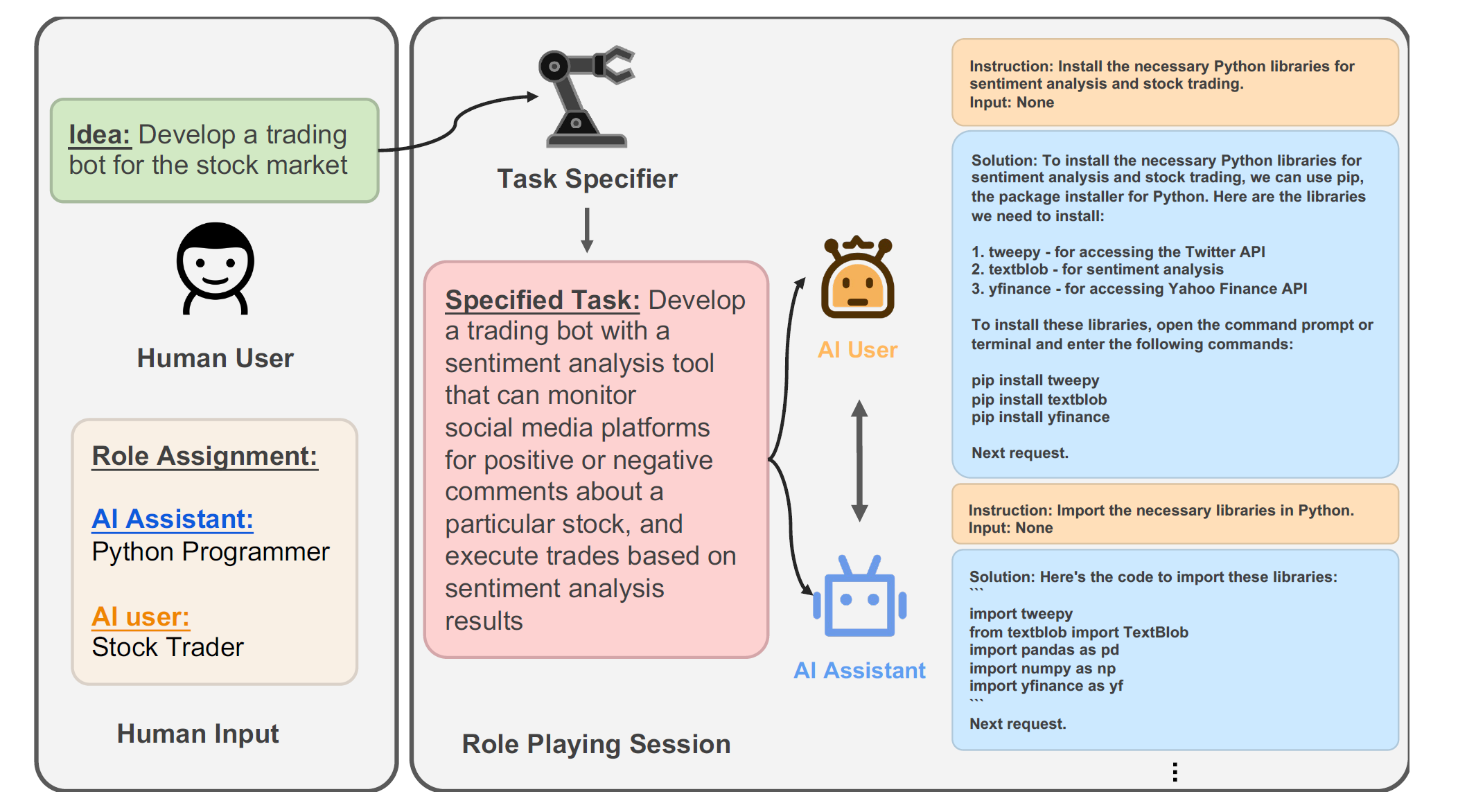
在Camel这篇论文里,我们能看到作者不是定义一个智能体的内部实现机制,而是用Prompt工程实现了多个角色来共同完成一个任务,同样都是“行动→观察结果→思考→决定下一步行动”,但它更多是通过角色之间的交流完成,你可以理解为一个角色PUA另外一个角色,甚至是两个角色相互PUA来完成任务。
在我眼里,HuggingGPT、AutoGPT、BabyAGI和Camel都有自己的优劣势,例如HuggingGPT可以调用多个GPT模型来完成同一个任务,但它的选择是有限的,而且它的选择逻辑需要提前定义好;相比之下AutoGPT可以联网,但它在记忆方面严重依赖GPT并且无法导入其他记忆;BabyAGI在任务循环上做得更好但不能联网;Camel只是定义了多个角色协作,但没有赋予每个智能体思考能力,因为它们只懂从对方接收任务。
后面我发现,如果将它们整合一起,它们各自优势可以弥补对方的劣势,以下是我整理的一个架构图,它分为AGI内部以及角色内部。
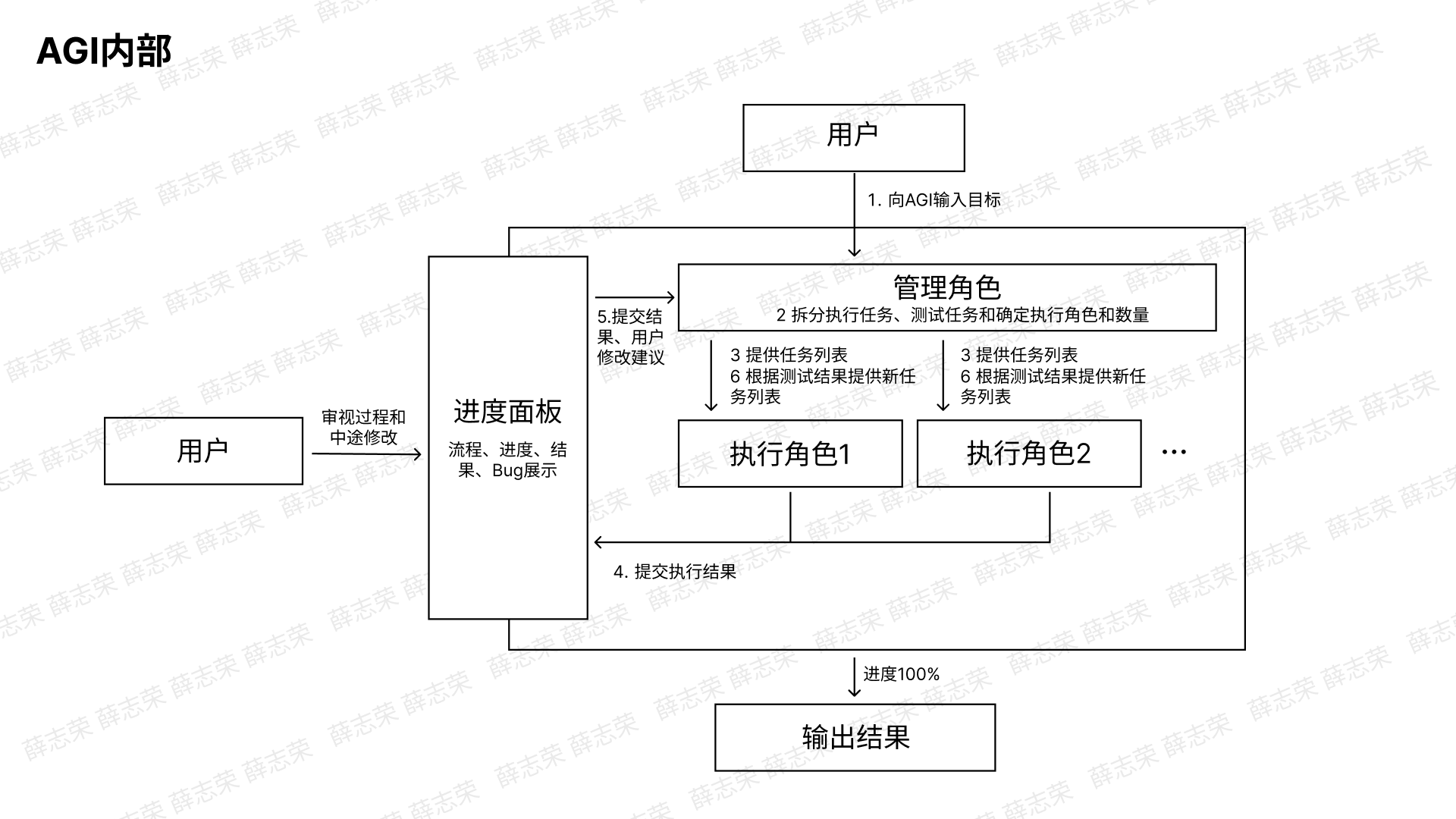
在AGI中我们会有多个角色在驱动任务的建立、执行和测试。为什么我们需要多个角色?我们可以理解为这是一条流水线,而流水线上的每一个员工都是单独个体,也就是各自处理数据相互不污染上下文,而且我们通过测试验证的方式决定了当前任务是否完成,例如这个任务有没有bug,如果有要自己重新修改(这个是不是有点像产品经理→程序员→测试员的流水线?)。为什么上文提及“相互不污染上下文”,我们这么理解:如果这个人自己新建任务以及自己执行任务,它是不是可以偷懒?所以用户是老板,用户把自己的目标传递给管理者,管理者指定计划并让下面的员工执行,最后管理者为结果负责。在这里我增加了“进度面板”这个新概念,这方便用户随时修改、优化和终止任务,甚至是在中途帮助AGI解决一些它们自己解决不了的问题。
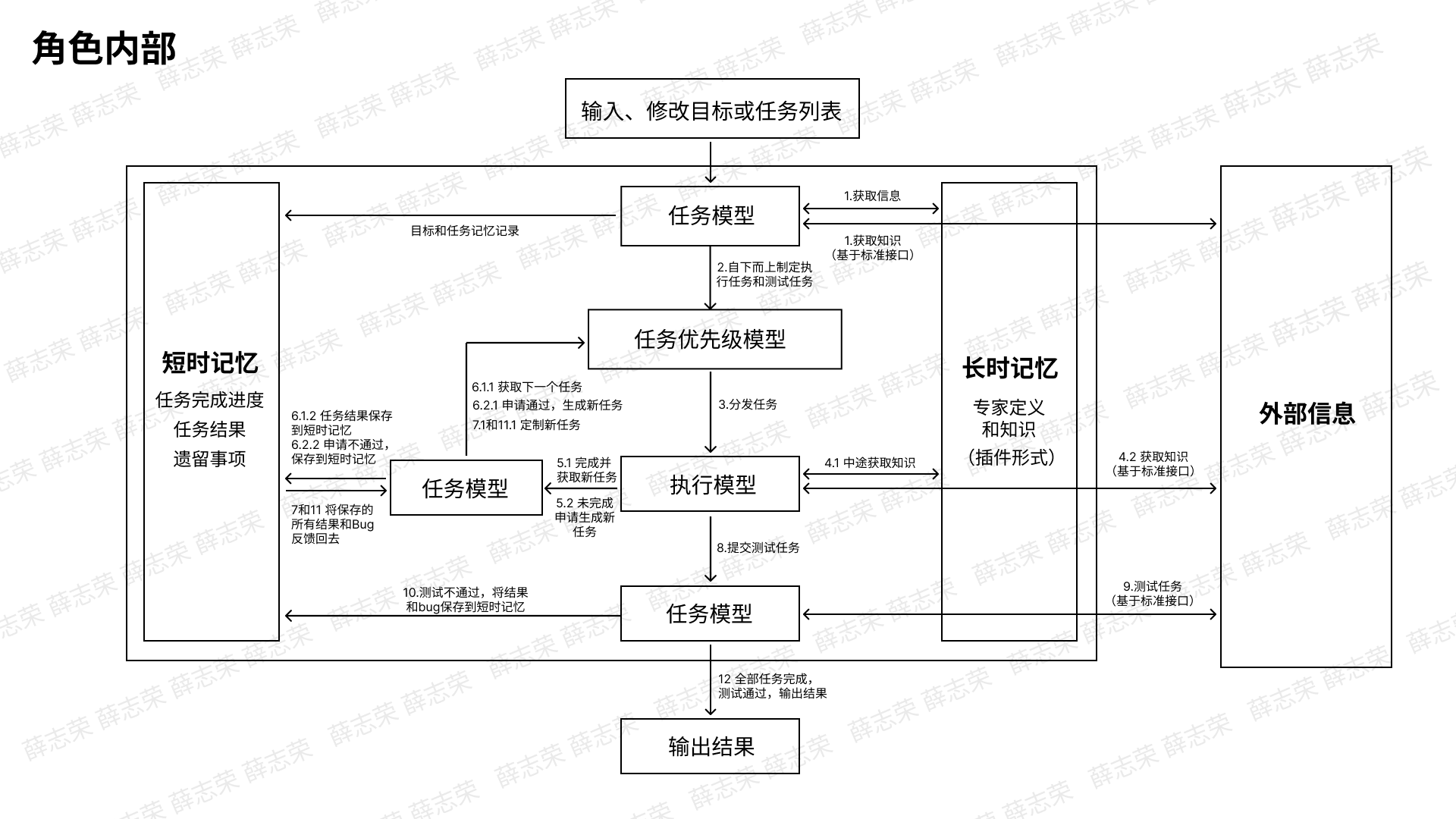
角色内部可以理解我定义了一个通用的框架,它可以基于短时记忆、目标和任务列表不断循环执行任务、测试任务、新建任务。在这里我参考了人的认知模型增加了“长时记忆”插件新概念,我们可以把它理解为专家的角色定义和经验的输入,也就是说当我们需要管理角色,我们将一个管理专家的卡片插进系统里,他会将用户的目标自下而上地分解成若干个任务和测试方法,同时他会决策自己需要多少个员工为自己服务。执行角色就是员工,不同员工会插入不同的专家卡片,他们会自己拆解、执行、测试和新建每一个任务。本质上,管理角色和执行角色分别在自上而下和自下而上实现用户的目标。
在图的右侧我标注了“标准接口”,我们可以理解为AGI也是一种模态,它可以跟当前的互联网、XR、我们真实空间里的信息、接口进行交互和调用,它除了可以是模拟点击、意图识别还能是什么?我认为基于图像识别的绝大部分技术都会纳入到下一时代的交互接口和事件定义里。
前阵子我一直在想一个问题,如果AGI真的到来,人机交互还能做什么?回归到人工智能和人机交互的发展史,我们可以看到人工智能和人机交互是相辅相成以及螺旋发展的,如果人工智能发生急剧地进步,那么人机交互必定也会跟随急剧进步,而不是倒退甚至没了(否则不符合几十年来的发展规律)。最近我有一个不成熟的思考,仅供各位思考:人机交互在以往更多考虑人如何使用工具,现在我们更多需要思考人和未成熟自治系统的协作,如果大家不太理解,我们可以把未成熟自治系统理解为小孩,重心是包容和协作,而不是命令和使用。也就是说在未来,我们应该把自治系统看成有能力差异的员工或者同事,而不是工具。
标题是《Next Thing:角色+模型+流程+接口调用》,Next Thing很明显是自治系统,构建它的前提是我们基于严谨的逻辑实现角色内部机制,包括构建可以被实现的模型、流程和接口,接着基于社会关系实现角色之间的配合。在不久的将来(可能是一个月后),我们将有好多的员工为我们服务,这意味着你将成为老板并解放自己的劳动力(前提是你得找到好的员工并且付钱给员工,因为调用各种API和GPT以及购买一台高性能的电脑需要花钱)。
原文:https://mp.weixin.qq.com/s/RGcGGsjOF3li_56Cy4myIQ
既然来了,说些什么?