打造人脸核身场景中的无感知体验
1. 人脸识别技术与核身业务的背景
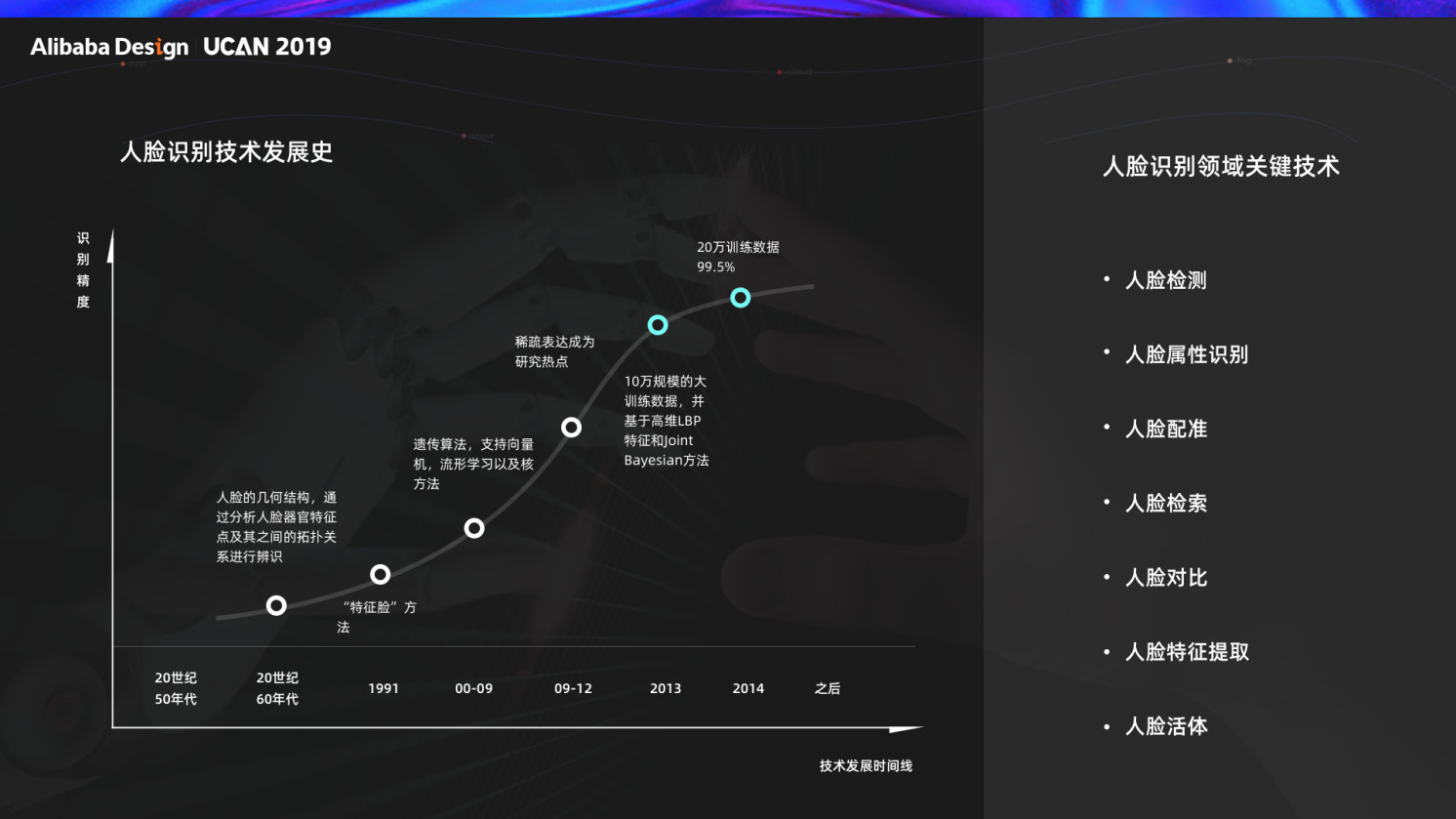
1.1 人脸识别技术发展史
人脸识别理论在上个世纪 60 年代就提出了,中间经过多年的理论和技术的进步,一直到了 12 年左右,随着人工智能的发展,深度学习技术的成熟,人脸识别技术趋于成熟成功率趋近 99.%,使得大规模人脸识别技术的使用成为可能,正式进入产品应用阶段。
人脸识别包含十大关键技术,这些技术在产品中的应用场景也越来越广,比如实时拍照美颜、通过人脸识别年龄性别、刷脸支付,快递取件等。
1.2 核身业务背景及问题
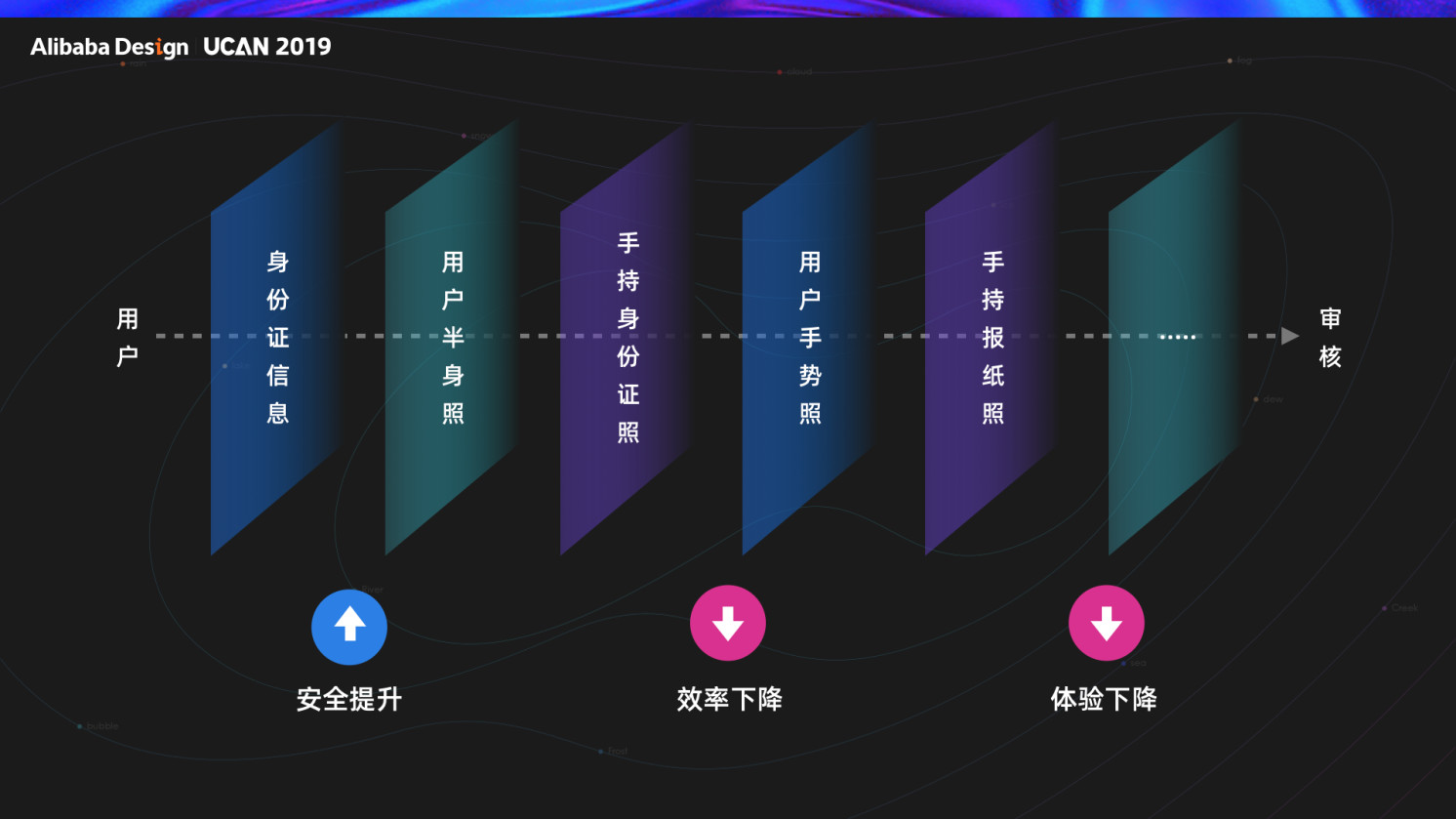
而在阿里,最早使用人脸验证技术,是在人脸核身产品中,人脸识别技术的成熟期,正好是传统核身业务的一个瓶颈期,传统的核身业务,我们通过用户上传身份证信息+半身照的形式,通过人工审核的方式来验证身份,但却滋生出了身份信息买卖,证件ps造假等黑灰产链路,迫于安全考虑,我们给用户出了一道又一道的考题(手持身份证,手势照,手势报纸照),让核身的体验变的极差。传统业务与新技术的碰撞:带来了优势:因为人脸基本不会突然发生大的变化,对于 AI 来说,人脸的识别准确率很高,速度很快,可以 7*24 小时提供服务。对于用户来说,新的技术因为安全性更高,操作流程变得更简单了。但新的挑战随之而来。AI 的引入带来交互方式的变化,需要用户适应和配合;AI 本身也存在不足和局限性,没有办法处理在人类看起来很普通的事情,需要产品来解决;还要继续对抗黑灰产的攻击,守住安全防线。而且业务从线上到线下,还要考虑如何适配不同终端场景。
所以:让黑产寸步难行,让用户无感体验。成为了我们的设计目标。
2. 如何让黑产寸步难行
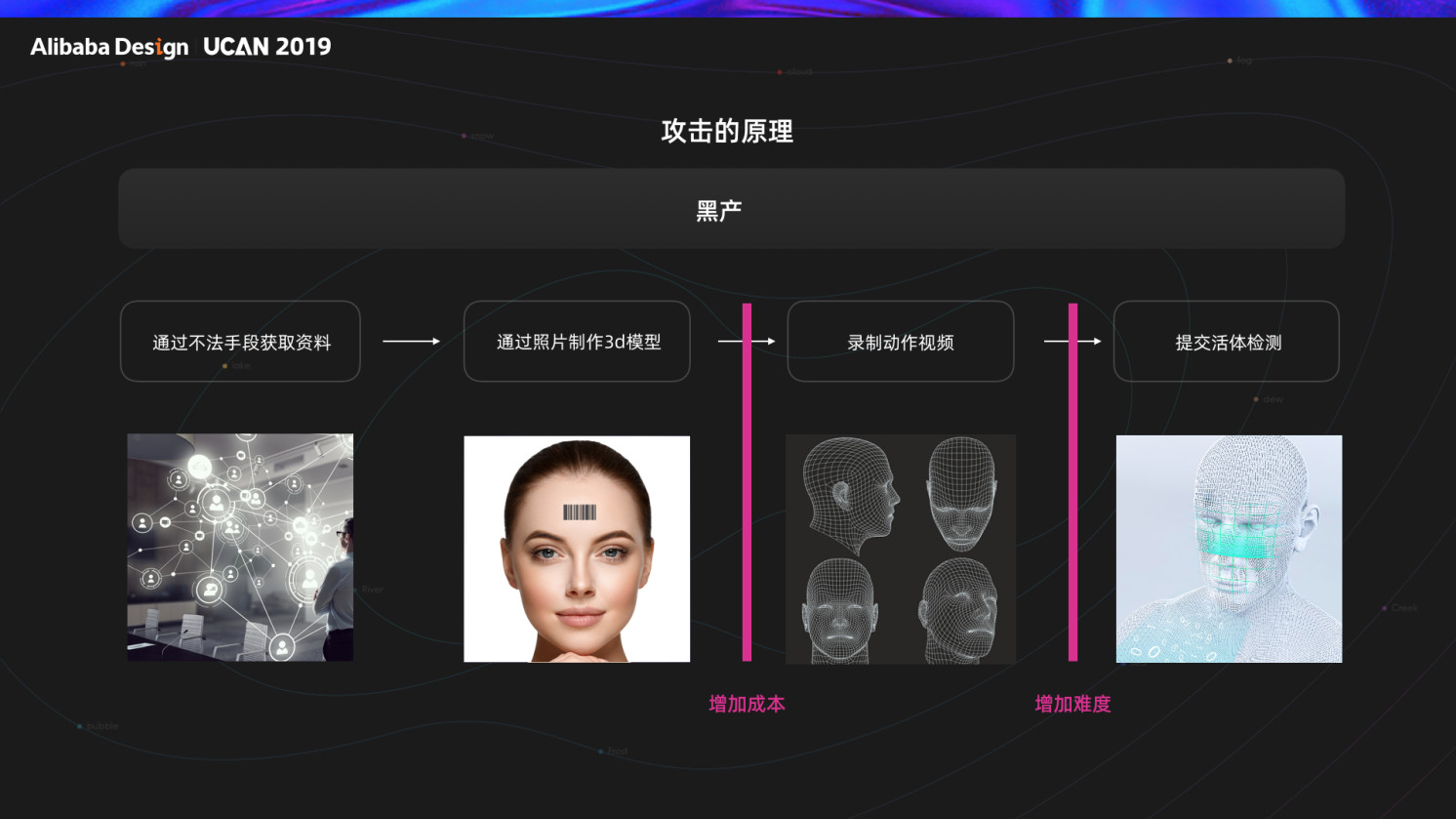
2.1 黑产攻击原理
黑灰产首先通过我们前面说的方法,获取到用户的个人照片后,将照片导入一个软件,制作出 3D 模型,然后生成好人脸识别所需要视频。在进行人脸验证时,将手机摄像头对准录制好的视频,通过播放视频来欺骗活体检测算法。
整个流程,前面的环节,是我们没有办法控制的。但在后面的环节,我们可以通过流程的设计,增加黑产制作动作视频的成本,增加黑产绕过活体检测算法的难度。
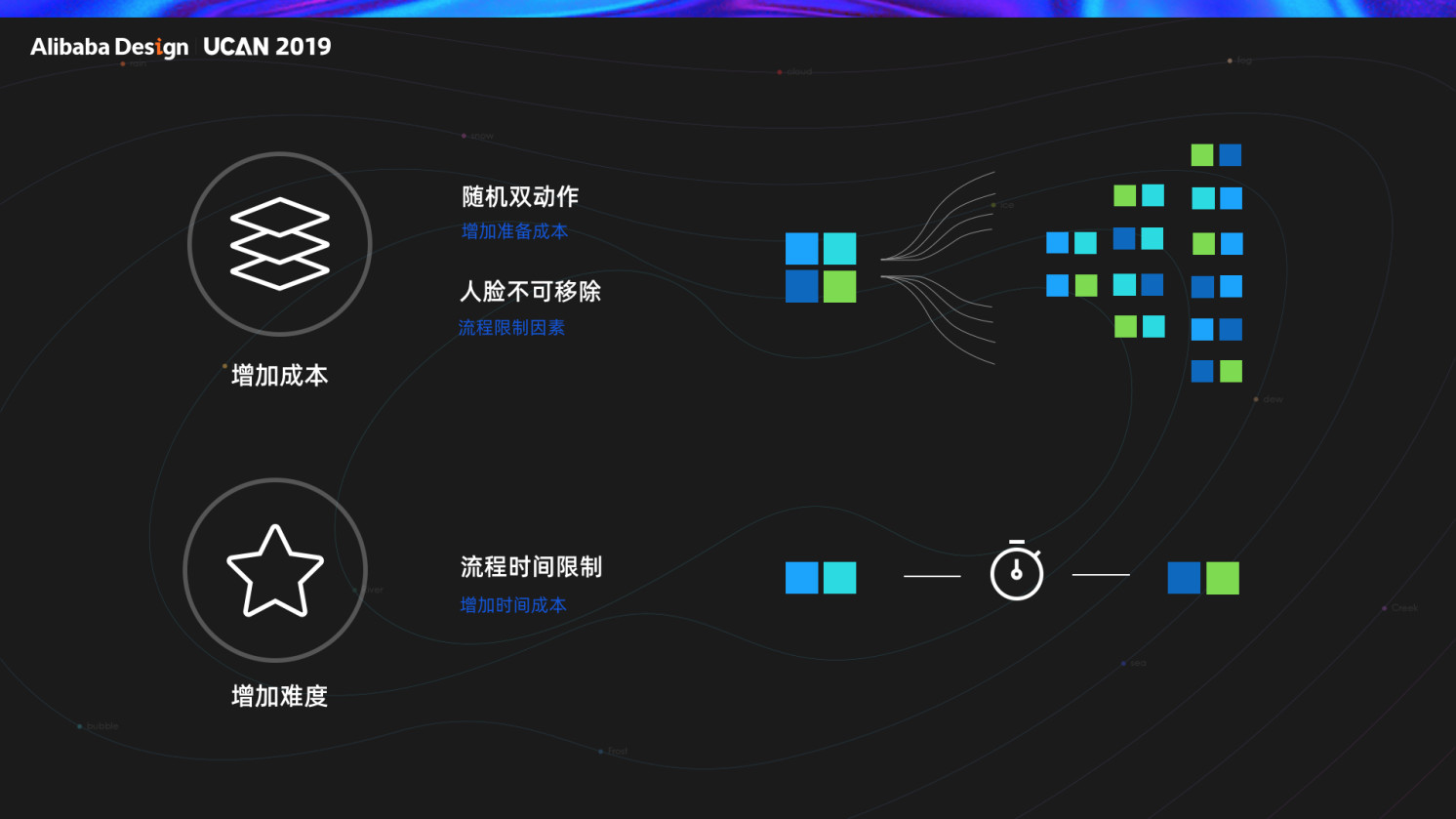
2.2 如何让黑产寸步难行
一:提高造假成本。首先设定了 4 个动作指令,分别是眨眼、摇头、点头、张嘴。接着用户和场景进行了分层,大部分情况下只需要做一个动作就可以了。在高风险场景中,会从 4 个动作里面随机选择两个让用户操作。加上动作的先后顺序不同,排列组合一共有12种组合。那么黑灰产需要事先制作 12 组动作视频,大大增加造假成本。
二:产品流程上增加限制因素。比如要求在操作过程中人脸不能在屏幕上消失然后再出现,这样就可以阻止通过切换视频方式来进行认证。而这个限制对普通用户是无感的,因为普通用户在短短几秒种之内,不太会出现这种的情况。
三:提高时间成本。在人脸识别过程中,对一次人脸识别过程的操作时长进行限制,这样即可以防止黑灰产有充分的时间进行视频剪辑。也可以防止黑灰产在一次人脸识别过程中进行多次攻击,如果到了限定时间没有通过,就会退出流程。黑产若要再次攻击就要重新开始,增加时间成本。
3.如何让用户无感体验
3.1人脸识别在设计上的趋势变化
在发展初期的时候大家很热衷于把扫脸设计的如同科幻片里呈现的一样酷炫,可以说是强感知设计,因为初期探索阶段使用场景稀少,用户与系统发生的是长期单触点的接触,需要利用炫酷的视效激发好奇,吸引用户尝试。但当到了未来成熟期时,人脸核身的应用场景会渗透进每个人每一天的各个环节中,比如智能家居的的应用权限,公共场所门禁,线下支付,甚至回家开锁,用户与系统发生的是短期多触点的接触,而核身的产品特性决定了我们只是用户去完成这些任务的中间条件而不是最终目的,那么对于正常用户来说,降低这些中间条件所带来的感知才是最佳体验。
无感知体验的目标是让用户只需凭借下意识直觉就能完成操作,那设计就必须扫清用户在链路中遇到的所有阻碍。
3.2人脸核身的体验全链路
参与人脸核身体验链路的对象有 4 个,分别是用户/终端的摄像头/终端上的界面,以及 AI。整体流程如下,可以看到若要提升整体链路的体验,设计的发力点有四个分别是 AI 智能度,环境设计,界面体验以及人机工程。
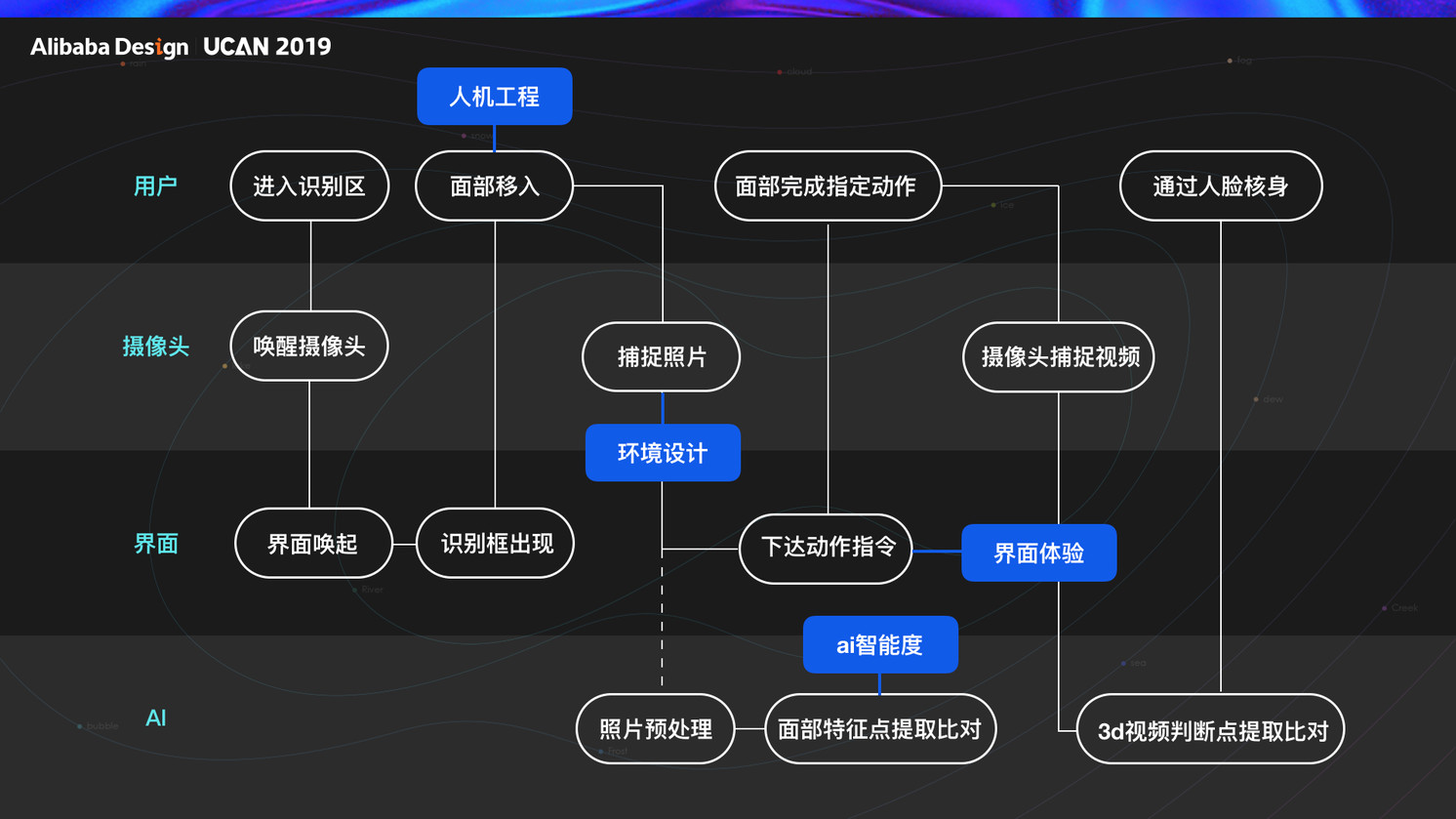
设计师通过两个路径去达成无感知体验,路径一通过提升 AI 智能度,核身环境设计帮助机器提升识别成功率,路径二通过界面设计/人机工程设计帮助用户缩短体验链路时间,最终两条路径的结合达成无感知设计。
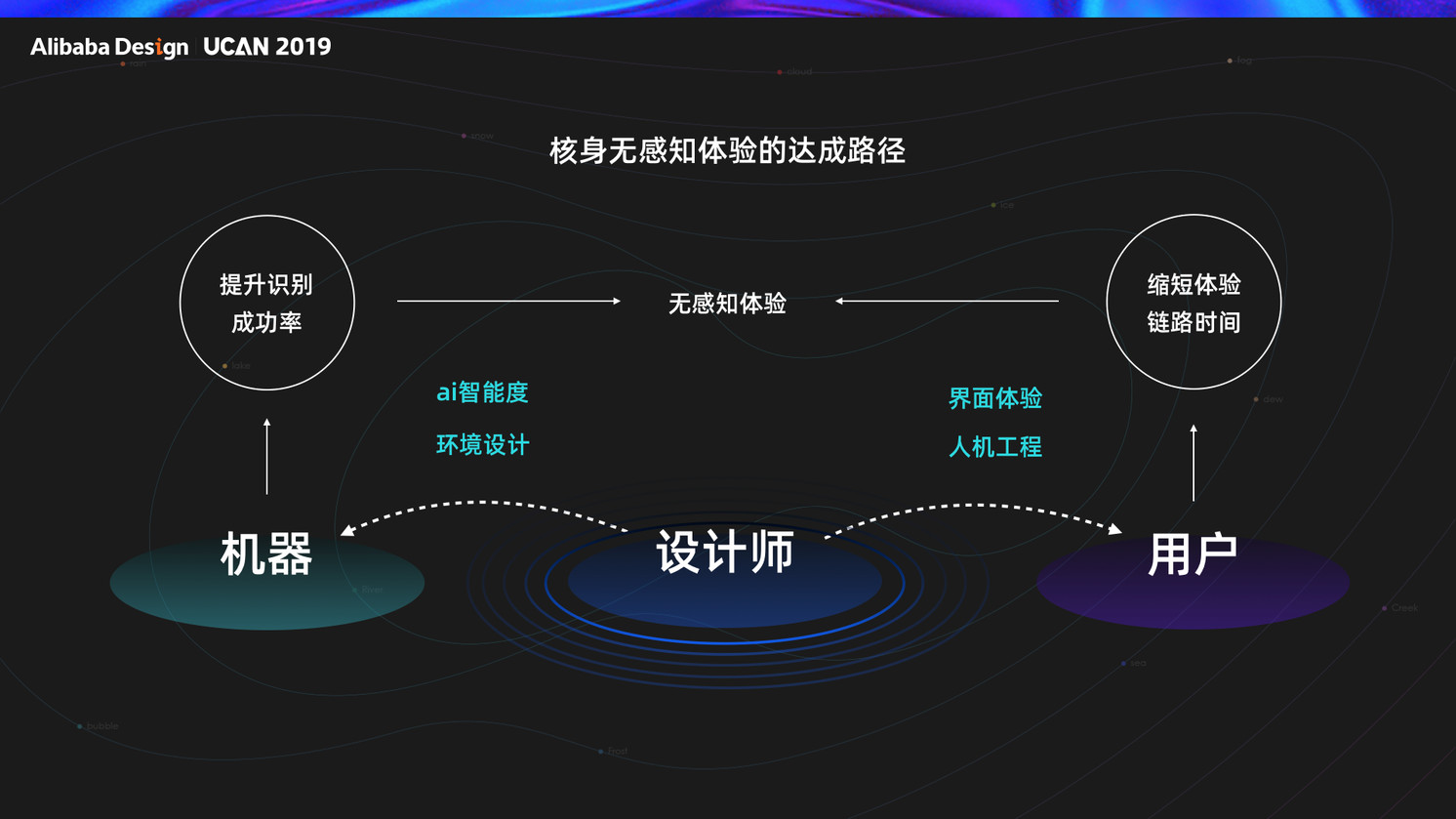
3.3 核身无感体验的四大元素
3.3.1 AI 智能度提升
比对等都依赖于关键点定位,而关键点定位对于捕捉到的图像的依赖是非常高的,这就产生了两个痛点,第一用户带着眼镜帽子时,关键点定位会出现偏差,第二,很有可能初始捕捉到的图像存在模糊,人脸不完整的问题导致无法进行定位。因为 AI 只认数据,他并不知道这个用户是带了饰品或者恰好没取到合适的图,他统一会判定比对失败。
针对第一个问题设计的解法就是提供大量抽象后的眼镜形状数据和实际镜片反光数据让机器进行学习,当机器再次识别到此类图像时,可通过形状及反光判断判定眼镜的存在,在进行关键点定位时抹去干扰物的影响。

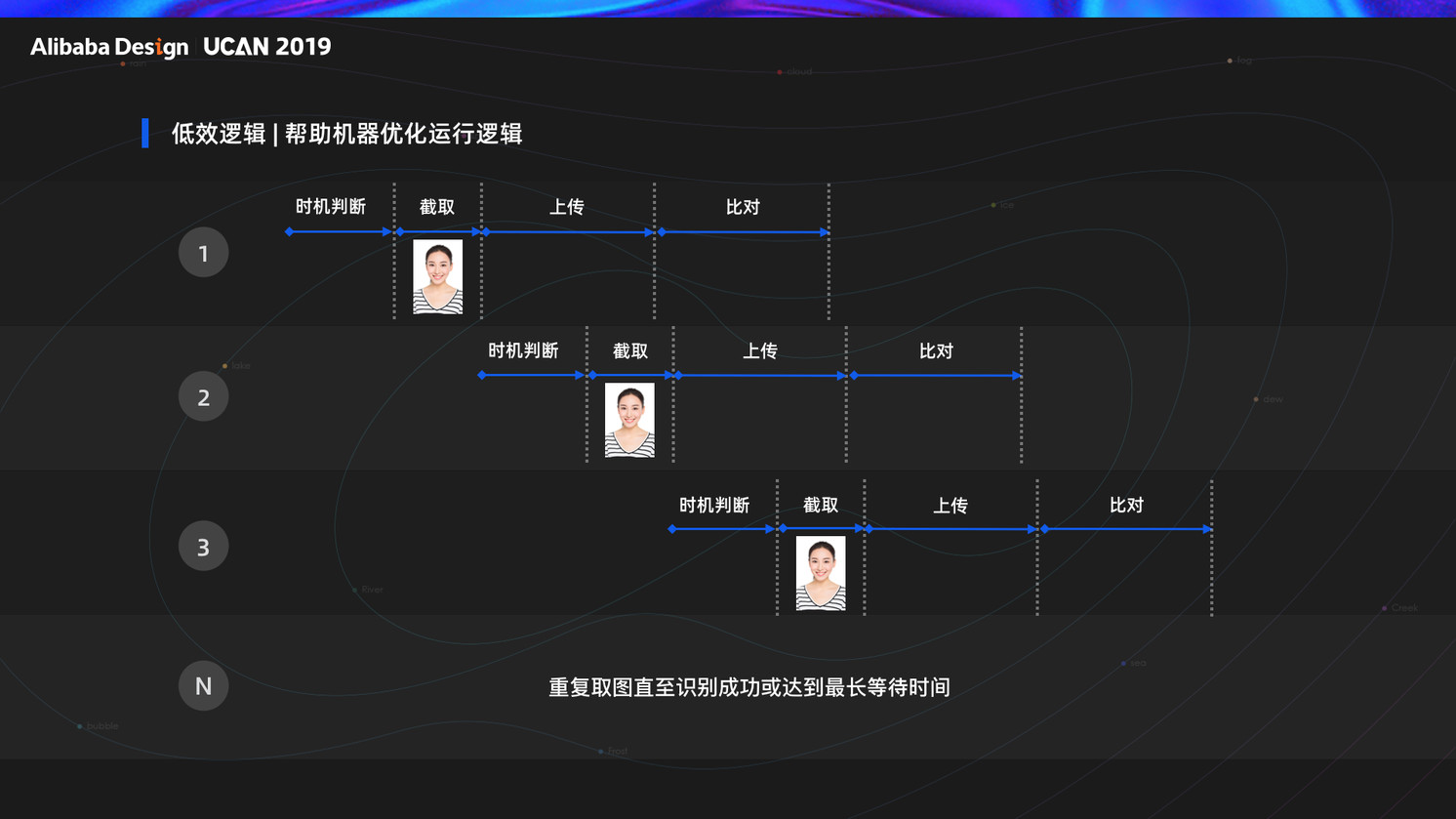
针对第二个问题,帮助机器制定取图逻辑,在用户进入取景框开始,我们会让 AI 通过时机判断,持续取图比对,由于时间是重合的不会增加流程时间,用户端也不会有感知,当其中任意一张比对成功,或达到我们设定的最长时间点时取图结束,大大提高了取图有效性。
通过提供数据学习和制定机器运行逻辑我们提升了 AI 的智能度。
3.3.2 环境设计
这里的环境设计一般是指环境光线的设计,因为摄像头捕捉人脸必须有充足的光线。在核身场景中,由于存在不同终端的,用户的使用环境和光线是不确定的,一般分为三类,第一类终端安置于室内环境,比如公司内的闸机,出入境大厅,飞猪未来酒店,这类可控性强,布光条件好的区域,一般采用传统的三点布光即可,大部分区域在灯光设计时一般都满足。
第二类终端安置于室外环境,可控性就降低了,夜间场景下光线就会不足,所以这类室外终端就需要在设备上自主加上光源,例如在菜鸟的人脸自提柜上,通过设计一条45度角的光源带为面部提供柔和自然的光线。
而第三类移动端的环境就更不可控了,用户可能在任意时间任意场合操作,甚至是无光环境,我们也没办法给手机上按光源啊,所以光源必须从设备本身去找。已知的物理层面无法提供帮助, 只能从界面层寻求突破,我们将屏幕的大部分区域设计成了白色,只留下一个符合面部形状的圆形作为取景框,通过检测用户的当前环境,调节屏幕亮度来为面部补光,通过这个设计,现在即使用户在完全黑暗的环境下也可以完成操作了。

3.3.3 界面设计
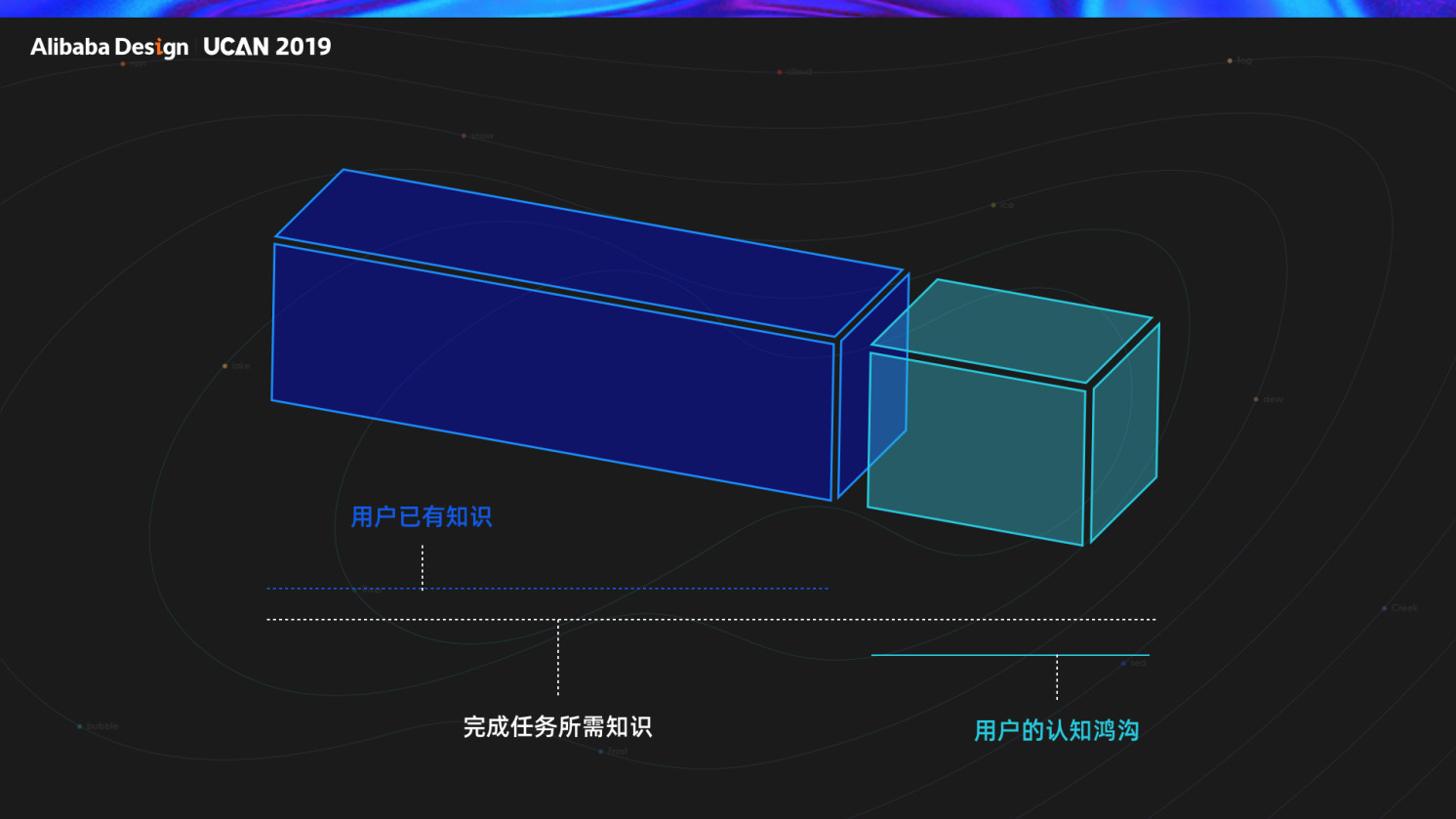
界面设计其实只涉及到两个元素,识别框和动作指令的设计。用户只要把脸放进去,然后摇头点头即可。但用户却给出了五花八门的行为反馈。为什么会出现这样的情形,我们可以看下上图的模型。左侧蓝色是用户拥有的知识,而这完整的一段才是完成一件任务实际所需的实际知识,左侧这块我们就把它称之为认知鸿沟,鸿沟的存就会导致一件看似简单的任务失败。
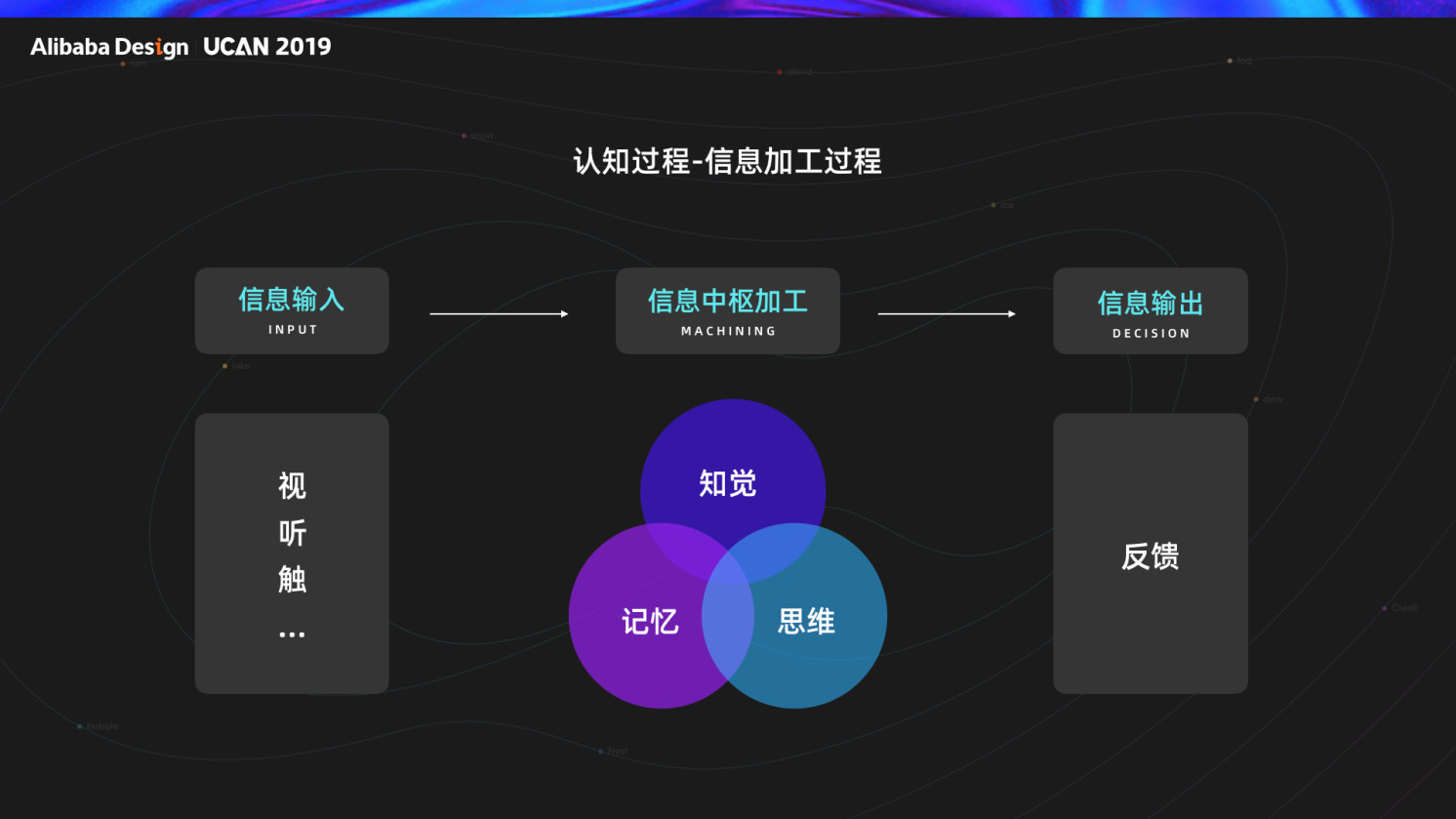
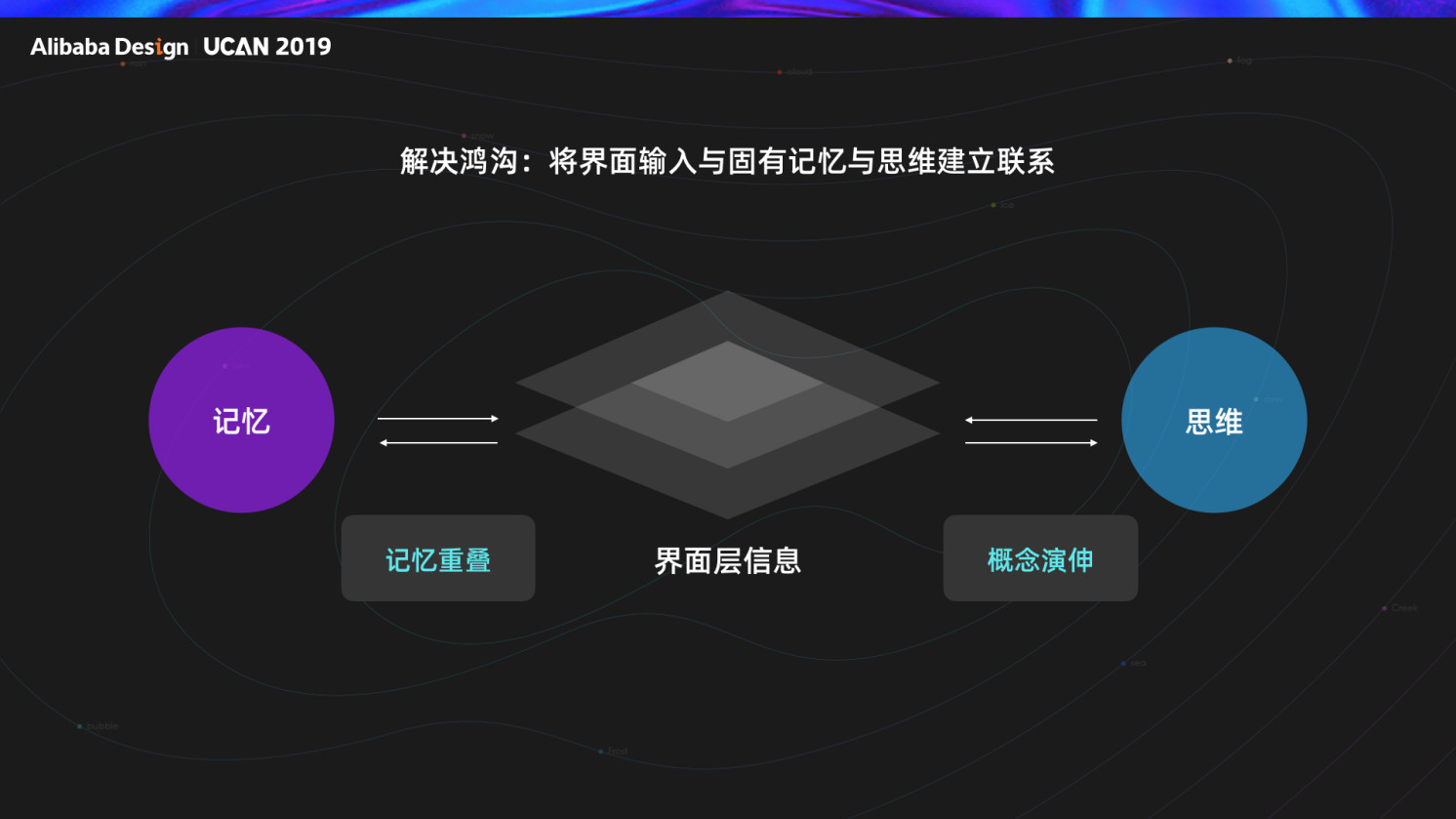
想要解决认知鸿沟需要我们首先要理解认知产生的过程,它其实是一个信息加工的过程,用户通过五感接受信息,在信息中枢通过知觉记忆思维三者相互联系相互制约进行加工,而后输出反馈,鸿沟的产生就是由于加工过程中未从固有记忆和思维中找到对应的内容,导致错误反馈的产生,所以我们要将界面输入与固有记忆与思维建立联系,归纳了两种方法,记忆重叠/概念延伸。
3.3.4 人机工程
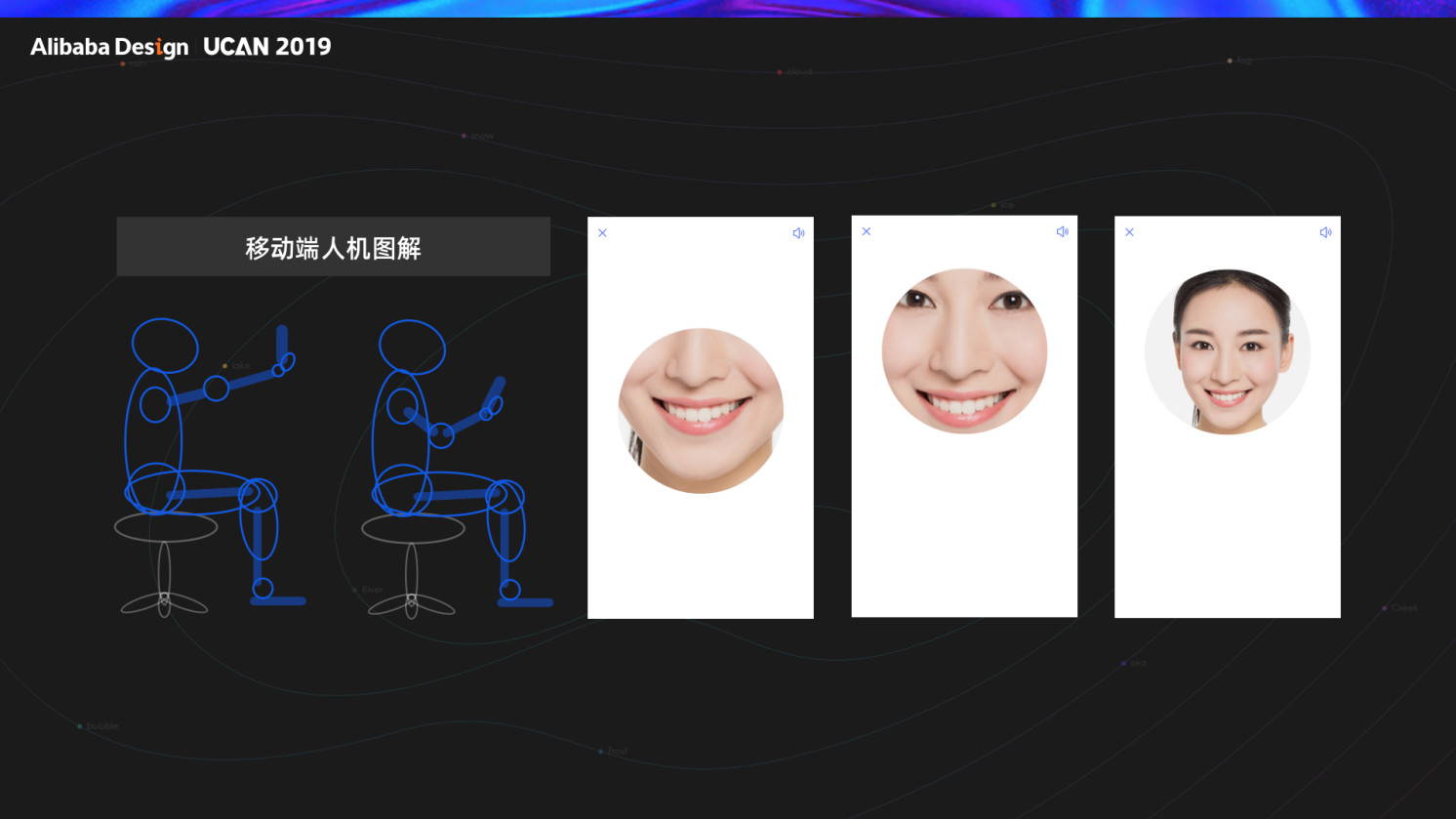
与前三个元素 AI 智能度,环境,界面设计不同是,前三者的缺失可能都会导致流程的断裂,但人机工程这一块的建设主要的目标就是让用户不改变当前的行为状态就可以完成任务,让一切的发生更自然无阻。同样我们会分终端来讲,对于室内外的非可移动终端,例如我们的扫脸入园设备,我们的目标就是要摄像头能捕捉到各身高人群的面部,那就需要我们设计摄像头高度的设定范围。首先明确人与终端的合理使用距离为单臂长度的 75%,正好是一个手触屏的舒适距离,将身高区间定在我国民众的平均最低和最高的区间内大致在 1.45-1.92 之间,然后我们就得到了一张人机关系图,在这张图中我们引入摄像头的可视范围,摄像头的可视范围会随着镜头焦段的增大,可视范围变的更远,相应的角度会更小,在我们的距离下选用 2.5mm 及以下的镜头是最合适的,在 1.5m 内角度能够大于 110 度。然后通过最高和最低身高的被覆盖极限就能得这一段摄像头最佳安装高度了。

那到了移动端上,思路上又会有一些变化,摄像头位于手机上,与人的人机关系会随着用户摆放位置产生改变,大多数人脸厂商把取景框放在界面中间,导致的问题就是用户去登陆下淘宝,或者改个密码,都得把手这样举起来,为了满足脸全部在识别框出现,还得维持一段距离,不说干扰性太强了,就说这要是在公众场合毫无私密性可言,所以我们的切入点应该是用户使用手机的最舒适自然的姿势,也就是右图的姿势,它导致的两个问题:
- 摄像头位置下沉取景框里只能出现面部下端;
- 距离变小人的脸在取景框内无法完全展示。
面对这两个问题我们在界面端做了这样两件事:一是将取景框上移,二是将人脸在识别框的展示缩小了 30%。.终于可以让用户自然而私密的进行核身了。
以上四点就是我们为了让用户达到无感知体验去做的四个维度的体验设计,通过以上的分享大家可以看出,做人脸识别这类的智能设计,并不是一蹴而就的事,我们也在这个环境下不断的摸索碰撞。而我们提出了无感知设计也是会随着这四类设计不断做到极致而无限靠近的一个概念。人脸核身的目标是让用户无感体验让黑产寸步难行,这其中一定会存在矛盾,做安全就要设置更多的警戒,做体验一定是更畅通,但做设计永远都是在做平衡,对于商业产品平衡商业和体验,智能核身产品上天平的两端只不过变成了安全与体验,追求任意一端的极致,都会导致产品的覆灭,设计要做的是在保障安全下的极致体验。
未来,人脸核身的应用范围会越来越大,例如一些社会痛点问题例如安防领域,智慧安心城市的大规模建设,商业领域步入金融级应用并作为基础设施,以及在智能家居领域都是未来发展的重点方向。对于设计师来说会带来更大的机遇和挑战。

原文:https://mp.weixin.qq.com/s/jCBjaIxXCLM0RvX3WcDx4w
既然来了,说些什么?