发明未来交互的灵感
未来交互
思考环节
在上一章中,我们从0到1将iPod发明出来了,最终的成品与苹果公司的第一代iPod所差无几。按理来说,这本书的理论和实践都已经讲完了,应该也快结束了。但实际上,单凭一个iPod的发明案例就想证明这一套理论是正确的,还是有一些推理漏洞在的。
我通过这套理论发明出iPod,那只能证明这个理论对于发明iPod是正确的。但因为我脑子里已经知道苹果的iPod是怎么样的,我也就没有办法证明我发明iPod的过程中没有受到了苹果公司iPod的影响。
所以我在书中发明iPod的这个过程会有两种解释
1、两种解释
第一种解释是,我已经知道iPod长什么样子,我的发明过程并不完全是一个从无到有的过程,更像是一个已经知道了结果再一步一步朝着最终结果方向进行演绎的过程。
第二种解释是这套理论是真的能让一个人从无到有发明出iPod,即便这个人从来没有看见过iPod是什么样子的。
那么问题来了,怎么才能验证哪种解释是合理的呢?我想到了两种验证方法
2、两种验证方法
第一种方法:时间穿越+记忆清除
因为iPod在2001年已经发布了,如果我想赶在乔布斯发布iPod前将iPod发明出来,我就需要一台时光机,让我穿越到20年前,实际上,大家也知道现在还没有时光机。所以我没有办法回到20年前,再者即便我回到了20年,我的脑海里也已经存在关于iPod的记忆了,我还需要一台记忆清除装置,将有关iPod的记忆从我的脑海中清除掉。那这个验证方法基本上是不可能做到的。
那么有什么办法可以间接证明这套理论是正确的呢?当然是有的。
第二种方法:创造未来
为什么说创造未来可以验证第二种解释呢?上面说到我没有办法早出生20年或者做时光机回到过去,赶在苹果的iPod发布前将iPod发明出来。但转念一想,如果我真的能够早出生20年,也就是公元2000年写出这本书,那书里所发明的iPod交互也就是未来交互了,因为苹果是在2001年发布iPod的。也就是说如果上面的第二种解释是正确的,那我就能发明未来的交互。
但实际上我无法早出生20年,但我们可以换一个角度思考,如果我晚出生20年的话,那么相对地,我写出这本书的时间是公元2040年,2040年的20年前,也就是现在公元2020年。那我是不是就能发明现在还没出现的交互设计方案了?
所以,我们可以这么进行推理,假设第二种解释是正确的,那么理论上,现在的我可以发明创造一些在未来20年里的新产品才会使用的交互设计。
小结
一句话,想要验证这本书的理论是否正确有两种验证方法,我没有办法回到过去,但我可以创造未来。
创造未来
如何创造未来的交互,该从哪些方面或者产品入手?
本章虽然是叫未来交互,但实际还是讲“历史”。因为未来本质上跟过去和现在没有区别,之所以称之为未来,只是因为它是还没有发生,但它终究会随着时间流逝成为历史。而现在的我在未来20年后我的眼里是历史了。我们不妨看看过去的产品和交互,看看能不能从中找到发明未来交互的灵感。

上图是乔布斯2007年iPhone发布会上的画面,上面的交互设计依次是鼠标,转盘,多点触控,这些设计所对应的产品是Mac,iPod,iPhone。这些产品交互可以说都是世界级的,它们的诞生改变了整个世界。
我们可以试着用前面章节的知识去分析这些交互,鼠标可以控制屏幕中的光标,在平面上移动,属于2维功能,信息接收(鼠标)和信息发送(屏幕)都是二维的面。iPod的转盘可以作为线功能的信息接收器,iPhone的屏幕则可以作为面功能的信息接收器。
我们再结合下面的表来思考,我们能够做什么东西出来。
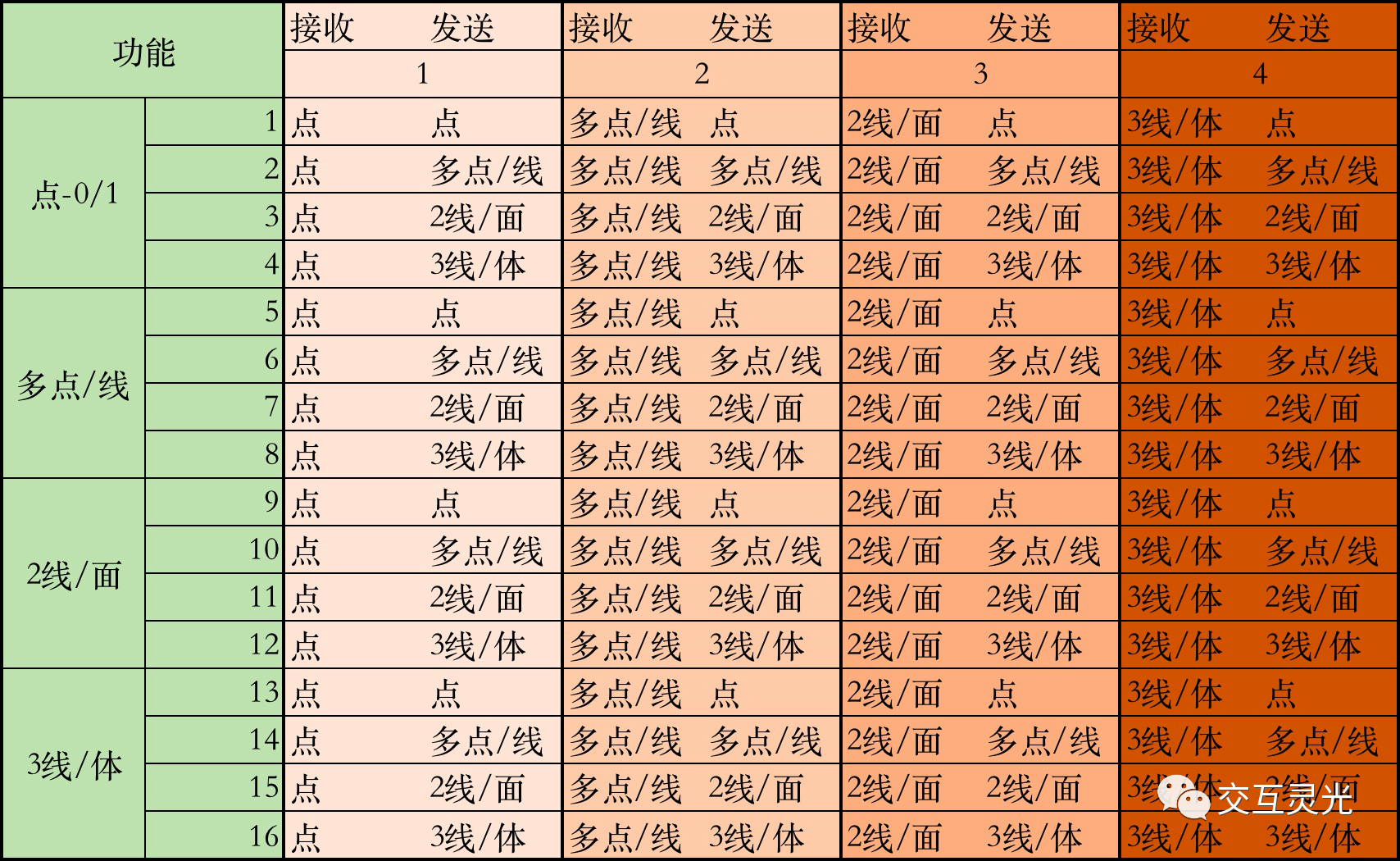
我在《术三:媒介的信息接收与发送》中展示了上面这个表格,并说到,世界上所有的交互都在这幅图里。那么未来的交互,也必定是在这幅图中。
左上角的是最简单的,功能是点,接收发送都是点,就比如开灯。与之相对,右下角是最难的,功能是体,接收发送都是体,基本上属于虚拟现实,AR,VR相关产品的范畴了。
我的答案
下面的视频,就是我根据书中知识所推理出来的未来交互。
不知道大家看完之后是什么感觉,上面发布会中列举的指尖交互手势可以使用在电视,电脑,游戏,虚拟现实这几个产品上。
其实手势控制不是什么新鲜的东西,有些产品已经搭载手势控制了,像电视用手势控制,最早的一波热潮是在2013年左右。那时候就有各种电视厂家在电视上加入手势控制功能。TCL在13年的时候出过手势识别的电视,但如果你现在去TCL的体验店问有没有哪台电视有手势,工作人员会对你说,你来晚了,你早来几年就有,现在早就没有手势控制的电视生产了。像小米电视至今也没有任何一款搭载了,康佳电视现在也只有一台机型有,华为2019年发布的电视也有搭载。
早年这么电视多争先恐后搭载手势,想要实现无遥控器电视,那么为什么直到现在都没有大规模应用起来呢?有的人可能认为是成本或者技术方面的考虑,不过我觉得不是这些原因,我认为真正限制的原因是即便这台电视搭载了手势控制,消费者用过几次之后,就会发现太难用了,电视遥控器比这些手势要好用多了,也就不会用手势控制这个功能了。既然没人用,厂家也就没必要再花而外的成本去搭载这一功能。究其原因,就像我视频所说的那样,这些手势存在一些问题,比如容易误判,响应需要等待,实现的功能很少,没有遥控器那样知道自己点没点按键的控制感
存在问题
1、容易误判
为什么容易误判,因为这些手势是真的以某个“手势”作为一种信息,比如OK手势👌、张开手掌🖐️、剪刀手✌️、握拳👊。以这些手势作为指令必然容易误判,因为我们平时就会做出类似的手势。再加上判定逻辑没有那么完善,每个人所做的手势又有所区别,这就更加难以平衡了。
2、响应需要等待
有的产品为了减少误判,就通过延长判断时间来实现,这样就造成了产品响应需要等待一下,比如华为电视就是这样。现在的很多手势,包括微软的hololens,或者其他VR,AR相关产品,都是采用时间维度来进行辅助确定。
3、功能有限
设计这些手势的设计师被自己的经验所束缚,认为手势就是一只手处于某种形态才是手势,而我们所熟悉的手势就那么几种所以能实现的功能也就只有简单的点功能。当然也有部分手势是线功能,面功能,比如用你的手掌在空中移动来控制电视的光标移动。
而指尖交互手势已经是最高的体了,即便在不考虑时间维度,比如长按,双击等情况下,就单凭一只手,指尖交互手势就有78个功能维度可以控制了。要控制电视一些点功能和线功能或者面功能是绰绰有余的。所以我们可以只用一只手就能控制电视,控制电脑。至于玩游戏的话,肯定是比不上游戏手柄了,只能玩一些简单的游戏。
我们平时手的状态握拳,张开手掌,手掌自然下垂,这些状态从指尖交互手势的角度看,握拳就是5指指尖交互,张开手掌就是没有指尖交互,手掌自然下垂就是4指指尖交互。我们设计的时候尽量避免这些指尖交互。就如同视频中展示的那些手势。基本上日常的生活中会比较少出现的。也就没有了误判的问题,另外通过指尖接触也不会存在个体差异,一个人的OK手势和另外一个人的OK手势会有不同一样的情况。角度不一样,方向不一样等。但必定相同的一点是拇指和食指的指间是接触的。
指尖交互手势的应用
而想要实现指尖交互手势其实也是非常简单,现在的技术条件已经可以做到了,最简单的方法只要产品配备一个摄像头加上一些视觉算法就可以了,当然也可以用雷达来感应指尖的手势。具体怎么实现就不是交互设计师要考虑的重点了。所以电视,电脑,手机,AR眼镜等都可以应用这个手势。
1、电视遥控器
在我小时候,看电视用的遥控器,那按键多到不得了。现在的电视把这些功能都转移到屏幕上了,按键也就少了很多。但如果能够完全用你的手,就能控制电视,那该多好呀,所以视频中我展示了用手控制电视的例子。因为所需要的功能并不多,用指尖交互手势就可以很轻松地将现在电视遥控器的功能给取代。
2、电脑鼠标
鼠标的2个按键和滑动光标也是一样的道理,高纬度容纳低维度,这个就比较简单了,相信大家在视频中都看到了,视频中还有一些平时鼠标没有的功能,那是因为我直接把苹果触控板的功能给做上去了,所以使用过苹果触控板的读者就知道视频中那些对应的功能了。比如启动台,调度中心等。
3、AR眼镜
在说AR眼镜之前,我们先谈谈简单点的内容,就像第一代iPhone采用拟物化的设计方案,让我们可以更好地从已有的实物操作经验去尝试新的手机界面交互,AR眼镜一开始最好能够电脑和手机进行移植,一方面可以很好地教育使用者,让其很好地从电脑和手机的使用中过渡,同时也解决了一开始没有很多开发者给AR眼镜进行软件开发的问题。移植了电脑和手机后,只要人们带上眼镜,就能够使用对自己有用的产品,无需额外学习。
4、电脑移植
我们所看到的世界,其实是3维空间的2维投影,所以我认为很多时候我们要进行交互的界面应该是二维平面。我们平时用的电脑就属于平面。那么我们能不能将现有的电脑操作界面直接搬到3维空间去呢?
带上AR眼镜,就能直接出现windows或macos操作界面悬浮在空中,用指尖交互手势控制光标。就像我在视频中演示的那样,我们可以完全展示出一块屏幕去控制。
一块屏幕,能显示的东西很少,现实中的屏幕因为是实体的,所以会有边界,不能随便变大变小。当我们觉得一个屏幕不够用的时候,我们会多屏协作。
因为我们现实中的屏幕是有边界的,很多程序顶部都有一些功能选项,如上图所示,在现实屏幕上,可以大幅度地上移,因为光标必定会停留在屏幕顶部边缘。但在虚拟现实中,如果光标的移动是任意移动,不受虚拟桌面的边界影响,那么就需要我们比较精准地控制,才能很好地选中我们想要的功能,不然鼠标就很容易移动到虚拟桌面外面了。
那能不能完全模拟现实的屏幕,光标只在虚拟桌面的范围内移动,不能超过界限。这样做可以解决上面提到的问题,但随之而来的是另一个问题。我可以有很多个虚拟桌面。当我想要控制其他虚拟桌面的时候怎么办?
怎么从一个软件窗口,移动到另一个软件窗口,就是我们要思考的问题了。用上图那种现有的多屏控制系统当然是可以的。但没有那么随心所欲,想怎么放置就怎么方式。我们可以面前的空间当成是一个大的桌面。每个程序都有自己的一个区域,不可避免地会有重叠的地方。但我有希望每个程序都有一个虚拟边界,来实现更好地掌控。这个时候该怎么去选择另外一个程序呢?
我的答案是:从空间的另外一个维度入手,我们可以将光标从二维屏幕中拖拽出来,再移到另一个软件窗口中。这时候的光标就像一个水滴一样,从一个程序的屏幕上脱离出来。
5、手机移植
上面我提到,单纯用指尖交互手势,只能玩一些简单的游戏,虽然我在视频中展示了用指尖交互手势玩守望先锋中的麦克雷角色,其实是比较不方便的,两只手最多可以同时控制4个功能,这种控制力度在游戏过程中往往是不够的。现在很多人都玩手机游戏,像王者荣耀,和平精英等。这些就很难通过指尖交互手势来玩了。
那么,未来手机会是怎么样的?我在这里进行一些思考,大家看看即可,不必较真。
我们在一些科幻片中看过完全透明的手机,但基于我所了解的知识来判断,一款完全透明的手机是基本不可能的。除非什么时候电池,摄像头,喇叭等所有材料都可以透明。如果只是显示屏透明,周围一圈不透明,其实还是可以的,而且很早就有厂家实现了,只是无法量产,效果也不太理想,而最近发布的小米透明电视,是可以量产的,我去到现场体验了一下,效果也还是不错的。

但如果是一块透明玻璃跟ar眼镜相碰撞,会擦出什么样的火花呢?我个人认为这两种结合,基本上就能实现一款完全透明的手机了。唯一需要解决的问题就是怎么获取到手指和屏幕接触的信息线,这个解决了的话,基本上就没有问题了。当然这块玻璃手机因为就只是一块玻璃,不会震动,不能自拍,不能播放音乐。

如果不在乎透明,想要更加实用。那我们可以加上摄像头,震动,按键,触摸,电池,麦克风,喇叭,不过AR眼镜可能已经有麦克风和喇叭了,或者你戴个AirPods也行。屏幕的话就不需要了,我们可以通过AR眼镜来贴上一块屏幕。那基本上就像一款无刘海的iPhone了。
那这款没有屏幕的“手机”用起来完全跟现在的手机一摸一样。你可以在上面做任何现在手机能做的事情。只是旁人看起来,你就是拿着一块东西一通乱按。现在手机最头疼的前置摄像头,后置摄像头随便你怎么放都行,即使整台手机两面有都几个摄像头,加入你自拍,你看到的依旧是全屏显示你的自拍画面。
我们再深入想想,如果前后两个摄像头同时拍摄,远程传输数据,再加上AR眼镜就可以身临其境了。当然最好还是控制一下显示范围,方圆几米还是现实环境,避免不小心撞到其他东西的。这个时候可以看成是VR的场景了。
如果只是做到上面的目的,我们现在的360环绕看,其实只是平面,就好比现在你拿手机屏幕看街景一样,没有立体感。我们想要拍摄立体感的图片或者视频,就需要两个摄像头相距眼睛的距离,同时拍摄,那样就可以得到立体的画面。
如果想要360度的环绕立体,那就至少需要4个摄像头才能做到,当然更多最好,但4个是最低要求了。
这种时候才真正叫做身临其境,而不是单纯的360环绕图片。那这么多摄像头,还能叫手机吗?这只是ar眼镜的一个应用场景而已,你甚至可以随便拿一块硬一点的纸板,直接当成iPad使用,因为通过眼镜,你看到的就是一台iPad,不过这样就没有震动,摄像等其他功能了。
AR眼镜应用层拓展
乔布斯在发布iPhone的时候,提到的电脑鼠标,iPod上的转盘,iPhone的多点触控,这些都属于媒介的信息接收方式。指尖交互手势在我看来,也属于一种信息接收方式,而不是具体的某一种交互。
举个例子,我们在手机上的操作都是基于多点触控这一信息接收方式,双指捏合缩小照片,双指旋转照片也旋转。或是下拉刷新的操作。这些具体的交互都建立在多点触控的基础上。再比如我们的电脑鼠标,不但可以控制光标,也能在射击游戏里控制准星。
我在视频中展示的是部分的功能操作和一些手势对应的功能。至于不同的手势对应什么功能,其实完全可以自己去想象,我在视频中的举例只是自己想到的,给大家一个参考。
除了这些举例之外,我没有说到具体的软件界面和指尖交互手势的联动。因为这个东西,其实已经到了大家自由创作的阶段了。
上面的手机和电脑是将已有产品移植到AR眼镜系统上。就像当年iPhone将iPod作为一个app进行移植类似。
那么iPhone应用商店里那层出不穷的各种app就属于应用层的拓展了。
到了软件层面,下拉刷新,双击点赞,看视频时,屏幕左边上下滑动调整亮度,屏幕右边上下滑动调整音量,水平滑动调整播放进度。这些交互都是建立在屏幕上的。
而在虚拟现实中,基于指尖交互手势能够衍生出哪些具体的交互出来呢?展示的内容是平面的时候怎么样交互,三维立体的内容又是怎么样的交互,开始菜单的展示又是怎么样的。多任务是怎么样的。这些各位读者都可以基于之间交互手势去进行想象,也许你想到的交互,就是未来我们会使用的。
不足之处
虽然说指尖交互手势有很多优点,但也是存在局限性的,就像手机屏幕大到一定程度就不好单手操作一样。
1、打字
如果在空中显示虚拟键盘来打字的话,这个时候用指尖交互手势就不太合适了,直接手指放在相应的位置就行。但这也不像实体键盘那样有触觉反馈,即便将虚拟键盘投射到桌面上,有点击的触觉反馈,但没有按键间隙的触觉反馈,你的视觉焦点还必须在虚拟键盘和虚拟屏幕间切换。这种交互就违背了书中所说的理念了。所以在打字方面,未来也只会通过实体键盘或者通过语音来实现打字。
顺便说一下未来电脑,有的设计折叠电脑,键盘是屏幕,绝对不是好的交互,我为什么这么说,因为这种交互跟我书中所说的交互设计理念相违背。除非能够实现触觉反馈,跟现实的键盘一样,而不是敲一块钢板。按下去的触觉可以模拟,比如现在mac上的触控板就可以。但每个按键间的间隙触摸的感觉也需要能够模拟出来才行。
要么就是有一款手套,戴上之后,即便是在空中,也能有触觉反馈。那这种手套倒是一个不错的选择。至于如何实现?四周有磁力控制装置和手套上的磁力能够对应起来再加上震动应该就可以了,甚至可以让你真实地握住空气中的物体。如果你全身穿上这种装置,有可能实现坐在空气中,原理大致像现在的悬浮地球仪一样。当然我对这块不太了解,也不知道会不会违背某些物理学原理,所以大家看看就好。
2、选择物品
因为我们看到的是二维图像,大多数时候可以使用射线来移动光标,选中物体。会比真正控制光标在3维空间中移动要来的快些,
未来的其他可能
未来的交互必然不止有指尖交互,还有其他的一些产品交互,比如,通过眼睛,宁静技术,拟态,语音,脑机连接等的发展,我在这里也写一些自己的一些见解。概括来说,未来的交互设计有一条规律:利用还没被利用上的信息线,无论是接收的信息线或是发出的信息线。
1、眼睛交互
眼睛让我们可以看到东西,接收视觉信息线。除了接受信息,我们是不是也可以通过眼睛发送信息呢?
我们先从使用者信息发送的角度,看看我们可以控制眼睛做什么东西,眨眼,眼珠转动,睁大眼睛,眯起眼睛,瞳孔大小
1.1、眨眼
眨眼就跟打摩斯密码一样,只要给你足够的时间,多复杂的功能你都能控制。但眨眼是我们生理必须要做的事情,我们可以主动控制是否眨眼,但我们会不自觉地眨眼,所以用眨眼来输出信息是欠妥的。当然我们还可以单独控制一只眼睛眨眼才触发相应操作之类的,但太费劲了。基于这个考虑,眨眼来输出信息是不可取的
1.2、眼珠转动
眼珠转动其实是一个面输出,我们已经在应用这个信息了,就是我们的眼动仪,视觉跟踪等。你也可以用来玩游戏之类的,但如果你需要接受视觉信息的同时,用眼睛去控制,那就不太好了。假如你用眼睛玩赛车游戏,你控制车向左转的时候,眼珠向左偏移,视线也在屏幕左边,那样你就看不清屏幕中间的内容了。另一方面,眼珠的转动受环境影响很大,外面的闪电或者巨大的声响,我们都会不自觉地将注意力转移,想要看看发生了什么。我们就算盯着某个地方,眼睛的焦点也是在不停抖动的。只是人自己觉得自己眼球没有转动罢了。
如果是通过其他感官的信息线接受,用眼珠转动控制,那还是可以的。比如控制音量,或者你所坐的椅子向左转向右转,升高或者降低
微软的hololens在浏览网页,看到下面的时候,页面会自动上移,这种交互恰似减少了人的主动交互,但实际上让人没有控制感。且容易受到影响,滚动速度也无法准确控制。
1.3、睁大眼睛,眯起眼睛,眉毛
睁大眼睛,眯起眼睛,可以看成是控制眼皮的张合,可以看作线信息发送器,这两种方式我们可以主动控制,但我们不可能经常做这些行为的,环境亮度会影响,眯起眼睛也会影响到视觉信息的接受。控制眉毛的上下移动的方案倒是稍微好一些,但不是每个人都能随心所欲地控制眉毛的
1.4、瞳孔大小
这个不是我们所能够主动控制的,主要是周围光源,或者是生理反应,比如受到惊吓之类的。
小结
使用眼睛相关的交互,只能在非常局限的场景下才比其他交互好用一些,所以未来我并不看好这种交互方式。
2、宁静技术(calm technology)
什么是宁静技术,我个人也是最近才了解的,所以可以跟大家简单说一下这个事情。下面是国外对这一技术的相关描述
维基百科上对宁静技术的一些介绍
- 用户对产品的注意力需要保持在边缘区域,这意味着该技术可以让人在注意的中心和外围之间轻松地切换,或者说宁静技术更多出现在注意边缘而不是注意中心
- 宁静技术增加了人们对边缘注意的利用程度,不会给用户增加信息负担,从而造就了良好的用户体验
- 宁静技术给人们熟悉的感觉,并让用户了解以往的,现在和将来的环境。
a good tool is an invisible tool.By invisible, we mean that the tool dose not intrude on your consciousness; you focus on the task, not the tool
一个好的工具是看不见的,这里的看不见指的是这个工具本身不会占据我们的注意,你只会集中在怎么完成任务上而不是这个工具上
Mark Weiser–1993
下面我举几个例子解释一下

上面的左边的手环就是宁静技术的体现,只有一个按钮和一个彩色的状态指示灯,小米手环就是宁静技术的反面,使用电子屏幕了。宁静技术把电子屏幕看作是宁静技术的对立面,把电子屏幕看作是会吸引用户注意力的东西,在我看来,这是不对的。屏幕是现实的延伸,是一种可变的现实。长得机械手表的电子屏手表和机械手表的差异在哪里?这是宁静技术不能合理解释的事情。我们看到屏幕,就知道这是一个屏幕,可以显示内容,是否支持触摸,就需要我们试一下才知道。但这算是我们的注意被电子屏幕吸引走了吗?
如果是黑色桌面上嵌上一块的屏幕呢,那一样完全没有占据注意力。
宁静技术倾向用非屏幕展示信息,比如下方苹果电脑的电源状态。如果有读者没见过的话,先不要往后看,先猜一下这3幅图都代表着什么意思。这比较重要,猜好了再接着看。

插入电源后,苹果电脑是否在充电,我们看电脑屏幕可以看到充电状态,宁静技术则认为接口上的那盏灯可以起到同样的效果。灯没亮说明还没连接上,灯是黄色,说明在充电,灯是绿色说明电量是满的。不知道大家有没有猜对,可能大部分人都猜对了,有极少部分读者猜错了。
宁静技术的应用只能是一些简单的功能提示才可以完全嵌入到平常的产品中。因为这些东西是要用户去推理,这个灯亮起来了是接上了电源,这个灯是黄色的说明电脑在充电。这些都是要用户学习这种对应关系。因为用户一开始是不知道绿色的灯和黄色的灯代表着什么含义。
但这种设计又稍微违背了宁静技术的理念。因为按照宁静技术的观念看,没有内容的黑色屏幕会占据我们的注意力,那上面没有亮的指示灯一样会占据我们的注意力。所以如果按照宁静技术的理念去设计,运用到极致的情况,应该就是苹果键盘的指示灯,如下图所示。

没有开启时,你根本就看不到有灯在那里,而灯亮了之后,你才会注意到有一盏灯。所以说宁静技术认为“对于手机、电脑等智能产品的界面而言,未来硬生生的UI界面越来越少,反而界面会融入到我们的生活当中”。
对这种观点我是不太认同的,我们从交互环的角度看看运用到极致的宁静技术会出现什么问题。第一步媒介发送信息线到使用者。我知道这个东西有什么用吗?如果是屏幕,我知道可以点击,这个就是我们熟悉的,学会了的。
屏幕是可变的显示,你不可能不使用到的。而如果非得将屏幕嵌入到你家的墙上,你家的桌面上。平时不用的时候,看起来就是普通的墙或者桌面。用的时候才显示屏幕,这显然是不行的。如果真的有一天,到处都是用了宁静技术的屏幕,谁知道这堵墙有没有显示屏呢?这种不确定感给人的带来困扰倒是真的。
宁静技术的运用可以让我们不会受到信息轰炸,但前提是我至少得知道你这个产品在哪里吧,而不是“消失不见“,我至少得直接知道这个是什么功能,而不是让我从结果中推导对应的功能进行学习。若没有做到上面两点,那这款产品根本就没有发送有效信息线给我,那这种设计又有什么用呢?
3、多模态交互
什么是多模态交互,其实就是多种感官的交互,就好比你可以用键盘打字,也能够通过语音打字。多模态交互其实跟我在术三中提到的优化策略:多样性,是一样的。
有电话打进来时,手机震动,播放铃声,屏幕亮起来,这些是必要的的多模态,因为根据stump分析,你有可能将放兜里逛街,周围环境嘈杂,这个时候就需要震动的信息线给到使用者。当手机放其他地方,距离你比较远,就需要声音信息线。有时候你将手机静音了,又放得比较远。屏幕亮起来,闪光灯闪烁也可以将信息线传递给你。
但并不是说多模态交互就一定是好的,把握住提高体验和造成骚扰间的度是很重要的,你不可能说每个app的每个按键都加上震动反馈,或者页面切换加入震动反馈,那样的多模态体验就很差了。
4、语音交互
上面说到用手势打字,无论是用指尖交互手势,或者是直接指尖接触打字,都不是很方便。这个时候语音打字就更加方便了。当然这也是有适用场景的,如果你在安静的图书馆,那么最好还是别用语音打字了。
语音发送的是点信息,加上时间维度则是线信息,语音交互这条路走到尽头,大概就是AI智能基本能够像人一样进行交流。
如果再进一步,就到脑机连接,即媒介读懂一般人无法读懂的信息。
5、脑机连接
前面的道和术已经将整个交互的框架及设计的要点都讲透了。以后的交互如果想要跳出这个框架,基本上就只有脑机连接技术应用了。那样人就不用通过信息发送器发出信息线,而是直接通过黑箱子发出信息线让媒介的信息接收器直接获取,媒介直接就能理解你想要的是什么。
意念控制物品,这在某些方面确实很好,比如因为高位截瘫,无法控制身体的人。但意念控制同样有无法避免但缺陷,我们没有办法完全控制脑子想什么,想象你在骑自行车,能想着一直骑,不翻车吗?这个我个人是比较难做到的。当你看到大象两个字,你现在能做到不想象大象的样子吗?大象的耳朵,大象的鼻子。我相信很多人做不到,这就是我所说的,我们没有办法完全控制脑子想什么。
哪怕最简单的用意念隔空移物,其实也你需要借助你的眼睛去控制物体,而不是闭上眼睛。
为了减少中途出错,假设这些都可以先模拟出来,再自动执行,你必须有一个确定的指令,来让产品执行你的指令。不然周围环境因素变化会夺取你的注意力。最容易被影响的是你的思维。
这是脑机连接关于信息发送的设想。目前的脑机连接可以让人通过大脑去控制物体,这是一个信息发送的过程。至于接收方面,如果我们没有借助任何光学产品,就能够在眼前看到文字,那就是到了这本书范围之外的交互了。凭空造物,制作你的各种感觉,就如同电影黑客帝国里的那般,那时候的交互会是怎么样的,就留给各位读者自己想象了。
结语
上面所说到的未来交互,有的是现有技术就能做到,有的则还需要等待技术发展才能实现。不知道有没有读者记得我在术篇的开篇中说过:交互设计师理应突破现有的技术水平限制,对未来交互进行想象。现在是时候回收这个伏笔了,我已经将指尖交互手势发明了出来,视频里的内容就是我所构思的未来交互形式。至于未来的交互是不是真的就是如此,只能等待时间证明了。
我是如何从0到1将指尖交互手势思考出来的,我想就没必要再画蛇添足多说一遍了,各位读者只要多看一两遍iPod的案例就能够懂的,我在iPod篇章中说的很详细了,如果读者认真阅读了,吸收了书里的知识,那么稍加推理就能够知道我是怎么想出来的。如果没有认真去读,那么我即便将指尖交互手势的思考过程写出来,对你的作用也不大,大概率也就看完之后就忘记了,所以我还是建议各位读者自己尝试去创造一些东西出来。或者试着将iPod或者指尖交互手势推理出来。
如果未来的交互真的如我所设想的那样,那就证明这套理论是正确的。即这套理论是真的能让我从无到有发明出iPod,即便我从来没有见过iPod,也能让我发明未来的交互。
未来是不确定的,我也不是预言家,也没有时光机穿越到未来,看看未来的交互是怎么样的,再写进这本书里。但我相信交互设计也是有一个演化的过程,而通过这个过程,我们可以稍微窥探一下未来。我也没有办法保证绝对像我所想的那样。我只是把我的想法写出来,10年后,20年后,回头再看。当书中的交互被实际应用时,我将会是什么样的感觉呢。
如果大家是从头看到现在,应该会发现迄今为止的一切交互都有迹可循,至于交互的终点是什么,甚至有没有终点,就留给大家去思考吧。我将这本书命名为交互灵光,是希望这本书能够像爱迪生的灯,在漫漫长夜里照亮一处地方。希望这本书能够像夜晚的灯塔一样,让各位交互设计师在交互设计的茫茫大海中寻找到前进方向。我自认为不是一个非常聪明的人,如果我也能够将想出一些交互创新,那么各位读者,请相信你自己,创造未来没有那么难,你也可以发明iPod,发明鼠标,发明指尖交互手势。
写到这,这本书也快要结束了,我想模仿哥尔.D.罗杰,对各位读者说一句话:
“想要创造未来的交互吗?想要的话就去书里找吧,我把所有的一切都放在了书里!”
原文:https://mp.weixin.qq.com/s/k9TcZJXZmbUekOZO-Qvnhw
既然来了,说些什么?