《数据思维》
作者简介: 王汉生
北京大学光华管理学院商务统计与经济计量系教授、博导、系主任,北京大学商务智能研究中心主任,微信公众号“狗熊会”创始人。美国统计学会Fellow(2014),国家杰出青年基金获得者(2016),美国统计学会会刊《JASA》、美国商业与经济统计学杂志《JBES》、泛华统计学会会刊《SINICA》、《中国科学:数学》等多个国际学术期刊的编委(Associate Editor)。
注:引擎再强大的车,碰到摸不着北的司机,照样开不到目的地。大数据也一样,如果不具备将业务问题转变为数据可分析问题的数据思维,再怎么神话大数据都无法创造商业价值。
一、朴素的数据价值观
1.什么是数据
凡是可以被电子化记录的都是数据。
这不局限于数字,还包括语音输入的声音,数码相机拍下的照片,手机录制的视频等被电子化记录的内容。该定义看似狭隘,但是能帮助我们更好的理解数据产业的变迁,培养数据的时代观。
注:文字存在数千年了,但30年前的文字都还不是数据,而当文字成为了数据之后就有了产生数据价值的可能,同样的情况正如声音、图像、位置等等过往不是数据的存在正在逐渐变成数据,随之而来的数据价值机会正是当下大数据产业趋之若鹜的起因,这就是数据的时代观。如果用在对未来数据产业方向的战略判断,则就应该关注当下哪些数据未被很好的利用而未来3~5年可以被挖掘出价值,更长远的关注5~10年还将会有哪些存在将被数据化。
2.数据有什么用
数据之于个人的价值,一定关乎自身业务的核心诉求。只有说清楚了数据的商业价值,客户才容易为数据买单,数据企业才容易产生收入,数据产业中才不会有那么多的困惑。
那么,数据的价值是什么呢?商业的朴素根本就是“利润 = 收入 – 支出”,然后在可控风险下长久运行,我们可以从收入、支出、风险三个方面简单的看数据的价值:
- 收入。最典型的是百度付费搜索广告,它通过对用户搜索数据的深入分析,进行精准匹配,为广告主带去一大波流量,它所创造的收入增长就是数据的价值。
- 支出。根据物联网技术采集到的信息,电视生产商发现某一款电视机的用户中,仅1%的用户还在使用老式的VGA视频接口。于是,他们决定取消这一接口设置,该决定为企业每年节省了上亿元成本。这也是数据分析带来的价值。
- 风险。很多商业银行都有网上申请系统,风险普遍高于线下面签。数据分析可以帮助它们更加准确地区分哪些线上申请者是好人,哪些是坏人。这是以降低商业风险的方式,数据为公司所带来的间接价值。
什么是数据思维
回归分析,即确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
古人云:以道驭术,以术驱道。
在“道”的层面上,回归分析是一种思维方式,在它的指导下,我们可以把“业务问题”定义成“数据可分析问题”。
在“术”的层面,回归分析又是一种可以运用的数据分析工具。
什么样的问题可以被看作数据可分析问题?你需要找到两种变量:
●因变量Y:因为别人的改变而改变的变量,这是业务的核心诉求。
●自变量X:用来解释因变量Y的相关变量,通俗点说,自变量X的改变,影响了因变量Y的变化。X表现了数据分析者对业务的洞见。
数据思维是把“业务问题”定义成“数据可分析问题”,具体的做法就是在乱成一锅粥的业务问题中,准确定位业务的核心诉求(因变量Y),并找到影响核心诉求的相关因素(自变量X),然后利用各种数据分析工具进一步研究。
注:所谓的数据思维就是回归分析的道与术。
假设A君向你借一万元钱,你也许会从A君平时的为人开始分析,顺便考虑你俩关系够不够铁、是否签下借条、A君的家境情况等等各种因素,依此衡量A君还钱的可能性。
数据思维就是道上把A君还钱的可能性看作因变量Y,而为人、关系、借条、家境都是自变量X;而术上去找到一个数学模型 F 去计算 Y = F(X)
二、 大数据到底是什么
在不了解数据分析的情况下,我们很容易神话大数据,认为它拥有多么神奇的魔力。实际上,大数据没那么神秘,它与许多人接触过的统计学有着千丝万缕的关系。
“预测不准是常态,预测准确是变态。”
相关性与因果性
- 相关关系:客观现象存在的一种非确定的相互依存关系。例子:公鸡叫,太阳升起来。
- 因果关系:第一个事件(因)和第二个事件(果)之间的作用关系,其中后一事件被认为是前一事件的结果。例子:按下开机键,电脑亮了。
统计学研究中包括了大量的相关关系,其中只有极小一部分非常稀有的因果关系,但是因果关系的重要性依旧无法取代。
我们经常会混淆这一对概念,甚至有些时候连相关关系都不算的事件A和事件B,由于它们常相伴发生,我们便迷信地以为两者具有因果关系,闹下不少的笑话。
因此,鉴别相关关系和因果关系这一对概念,不仅是我们了解大数据的金钥匙,也是培养科学素养——对伪科学说不——所要迈出的关键一步!
三、人人应有数据思维
数据思维是一种必备的素养。因为生活在信息时代的我们,或多或少都会和数据扯上点关系,不具备数据思维,我们就会像不懂经济学知识炒股的人一样,容易被征智商税啊!
提高沟通效率
我们在工作中,经常遇到这样的情况:数据专家说的是技术语言,需求部门说的是业务问题(其中包括数据可分析的和不可分析的),双方的沟通总是难以顺利进行。
要解决这个问题,这不仅需要专业人士摆脱自己知识的诅咒,也需要需求部门克服对于数据的恐惧感,公司内部自上而下都有必要培养数据思维。决策者要认识到哪些事与数据相关,需求部门应该有将核心诉求讲清楚的能力。
段子,“张口就能点出回锅肉”
抓住商业机会
另一方面,数据思维对于创业者来说也可能有帮助,尤其在那些与数据有着紧密联系的创业项目中。具备数据思维,能帮助创业者抓住商业机会,但这需要经过以下三个步骤:
- 我所在的创业方向,数据是否能帮助我?
- 如果数据很重要,将业务中的因变量Y和自变量X梳理清楚。
- 在战略层面上,保证Y和X的高质量供给、长时间积累。
生活中的数据思维
假如一个人既不是创业者,所涉及业务问题又和数据分析八竿子打不着,培养数据思维又有什么用呢?事实上,生活中的大部分小事,数据思维都可以给你启发,关键看你怎么用?
首先,培养数据思维帮你养成一种思考有的放矢的习惯:分析的目的是什么?核心诉求是什么?因变量Y是什么?
其次,搞清楚目的后,你就能将注意力聚焦在相关的自变量X上,就不会陷入“放眼望去都是重点”的迷乱状态中。
最后,你可以尝试最简单的分析,专业的建模暂且不说,至少可以区分一下哪些是相关关系、哪些是因果关系。
四、 各种数据分析方法
回归分析
在“术”的层面,回归分析就是各种各样的统计学模型。它主要有五种类型:线性回归、0-1回归、定序回归、计数回归以及生存回归。
- 线性回归,更严格地说是普通线性回归,其主要特征是:因变量Y必须是连续型数据,而对解释性变量X没有太多要求。在数据世界中,线性回归可以应用于股票投资、客户终身价值、医疗健康等领域。
- 0-1回归就是因变量Y是0-1型数据(只有两个可能取值)的回归分析模型。例如,性别只有“男”或“女”。购买决策只有“买”或“不买”。癌症诊断只有“得癌症”或“不得癌症”。0-1回归可以应用于互联网征信、个性化推荐、社交好友推荐等。
- 定序回归就是因变量Y为定序数据(关乎顺序的数据)的回归分析模型。举个例子,现在请各位书友为本期作者光临打分,根据喜好程度:1表示非常喜欢,2表示有点喜欢,3表示感觉一般,4表示有点不喜欢,5表示非常不喜欢。这就是一种定序数据。定序回归常见的应用场景有:电影的打分评级(15星);电商产品的满意度评分(15星)等。
- 计数回归,如果因变量Y是一个计数数据(非负整数),那么对应的回归分析模型就是计数回归。计数回归常被应用于:客户关系管理中的RFM模型,即一定时间内客户到访的次数;二胎政策研究中,一对夫妻选择生育孩子的数量等。
- 生存回归是生存数据回归的简称,即因变量Y为生存数据(刻画一个现象或个体存续生存了多久)的回归分析模型,例如人的寿命、电子产品使用年限、创业公司存续时间。
数据可视化
最基础的数据可视化方法就是统计图,而一张好的统计图应该满足四个标准:准确、有效、简洁、美观。常见的统计图有:柱状图、堆积柱状图、饼图、直方图、折线图、散点图、箱线图、茎叶图等。
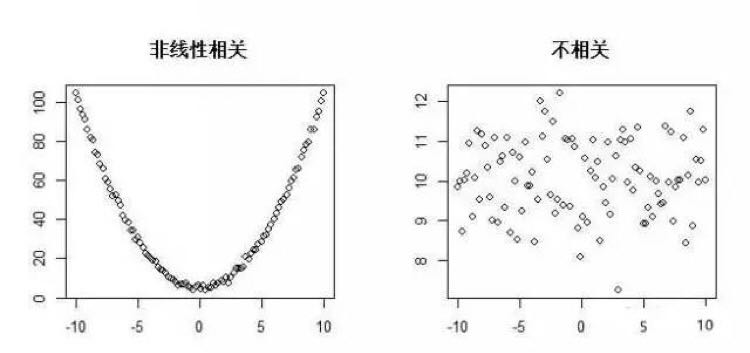
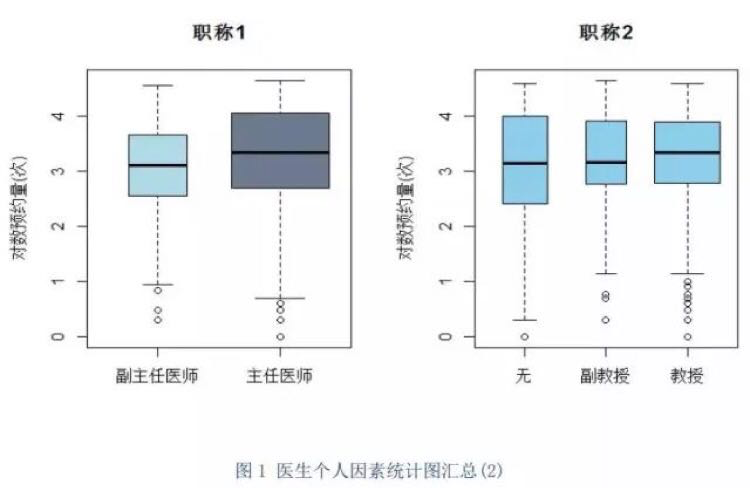
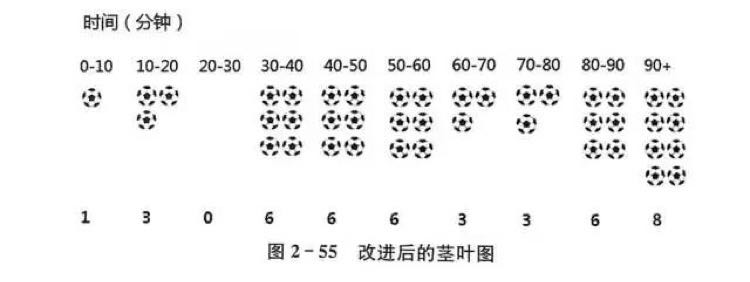
机器学习
机器学习代表着一大类优秀的数据模型分析方法,是立志成为数据科学家的书友们的必修课。它主要涉及的方法有:朴素贝叶斯、决策树(含随机森林)、神经网络(含深度学习)、K均值聚类。
非结构化数据
数据是结构化的还是非结构化的,这是一个相对的、主观的概念。当然,其中也有一些达成了共识,公认的非结构化数据包括中文文本、数据结构、图像等。
案 例
非结构化的文本数据,并不表示我们不能对它进行数据分析。以《倚天屠龙记》为例,张无忌到底最爱谁,是赵敏吗,是周芷若吗,还是殷离或者小昭?本书利用数据分析的方法,得到了答案!
第一步,把小说的主要人物和他们的称谓提取出来。接下来,要确定分析单位,这里取的是自然段。那么张无忌爱谁这样的问题,到底怎么定义为数据可分析问题呢?本书中从人物出场频次、出场时间、亲密程度等不同角度进行分析,这里简单说一下最重要的亲密程度分析,这是通过她们与张无忌出现在同一自然段的次数(同时出场)刻画的:所谓日久见真情,从这一个侧面看张无忌与赵敏亲密接触的机会最多,他最有可能爱上的是赵敏。
说明:本案例详情,可从微信公众号狗熊会(ID:CluBear)获得。
to be continue…
手动点赞