PMbook-竞品数据如何找?
5.1、竞品数据如何找?数据产品经理的威力
竞品数据如何找?
小奈:表哥,竞品分析、竞品数据如何找? 大仁:你可以找你们的数据产品经理啊,常见数据来源如下:
- TBI腾讯指数 http://tbi.tencent.com/
- 360指数 https://index.so.com/
- 搜狗指数 http://index.sogou.com/
- 百度指数 http://index.baidu.com/
- Questmobile http://www.questmobile.com.cn/blog.html
- 易观千帆 https://qianfan.analysys.cn/
- 199it http://www.199it.com/
- 艾瑞咨询 http://data.iresearch.com.cn/
- TalkingData http://mi.talkingdata.com/
- 七麦 https://www.qimai.cn/
- 酷传 http://www.kuchuan.com/
- 上市公司的财报 http://www.hkexnews.hk/ https://www.sec.gov/
公众号:产品经理的技术课堂 回复 “数据来源” 可获得链接。
小奈:我们公司没有数据产品经理喔。 大仁:这,那你也可以自己试试啊。 小奈:我不会啊,我现在想要一个xx无人货架的城市分布图,要怎么做? 大仁:我示范下,xx无人货架官网好像有城市bd招聘信息喔,我把这些城市都录入到excel,再生成经纬度,然后就可以了,看下效果。(可用python也可用数据分析平台) 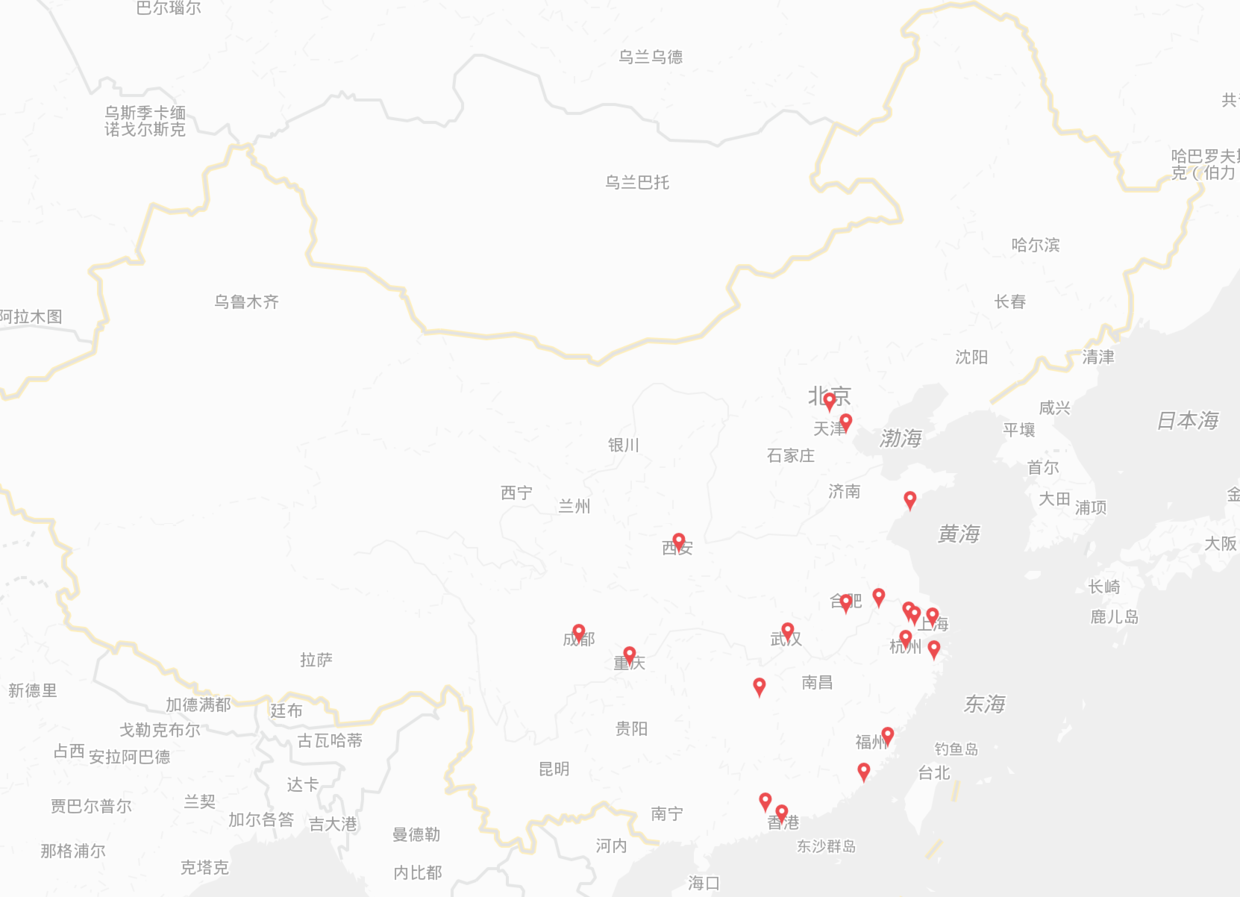
商家、顾客和优惠券
小奈:数据产品经理好像挺神奇的耶。 大仁:是啊,你们公司是电商的对吧,假如你们老板要你们提高净利润(现有系统基础上),你们会怎么做? 来看下数据产品经理怎么做:
假设一瓶牛奶成本3元,定价6元时,50人会接受此价格。定价10元时,有30人会接受此价格,前者利润为(6-3)×50=150元,后者利润为(10-3)×30=210元。 但商家不想放弃另外20个支付意愿较低的消费者,于是决定用4元优惠券来吸引他们,同时对剩下那30个对价格不敏感的消费者依然维持10元的原价销售。
通过用户画像、优惠券来提高销售利润,这就是数据产品经理干的事之一,如何才能做到呢? 首先得有自己的bi系统,或者说得有用户画像,什么事用户画像呢?
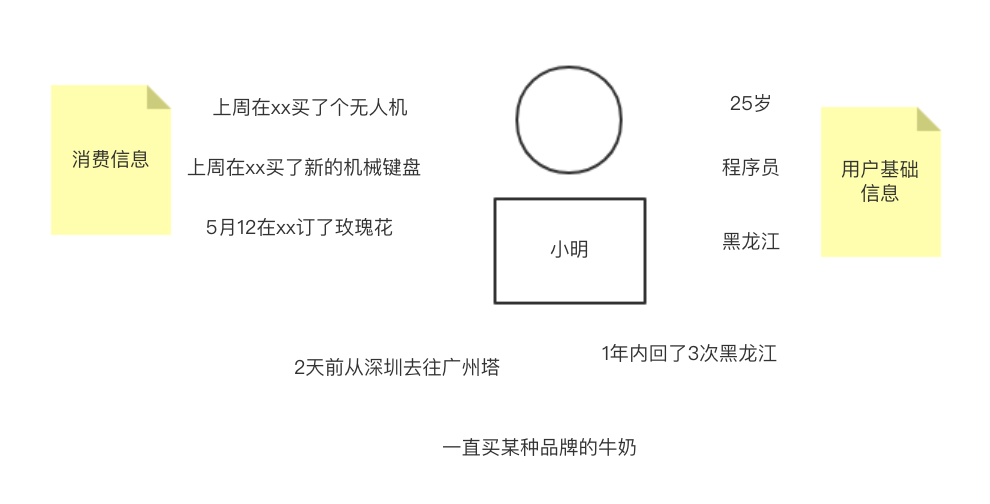
有了用户画像,知道哪些用户对价格不敏感,哪些用户不反感车的广告,再进行推送,大大提高转化率,净利润得到有效增长。那么用户标签体系该如何搭建? 业务需求促进标签体系建立,具体从老板战略目标、功能、业务。 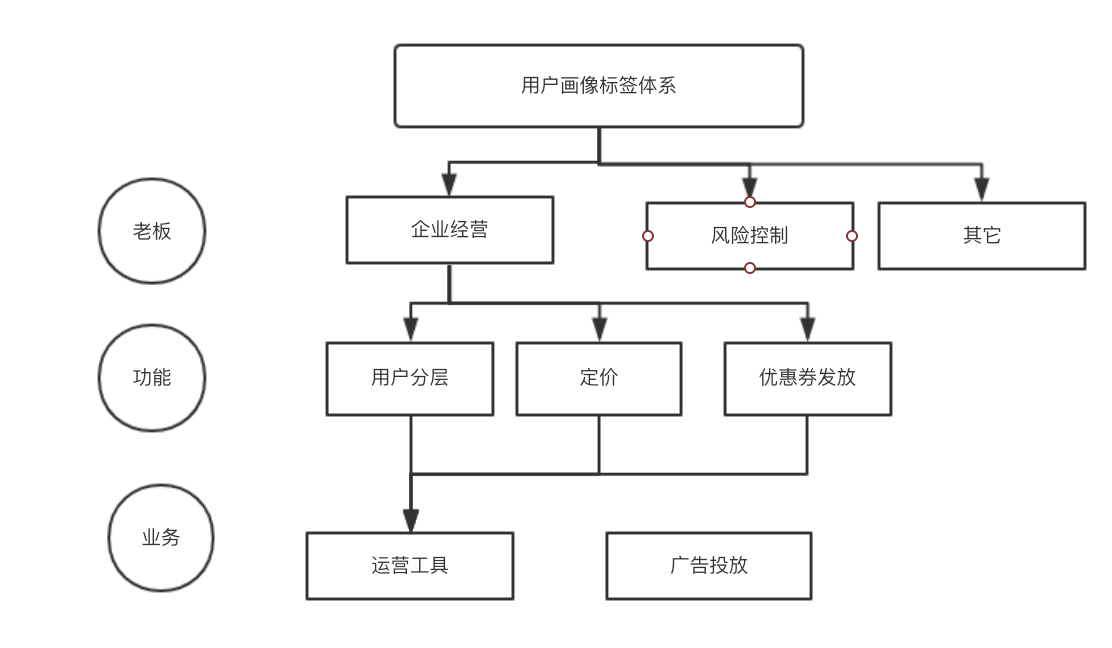
数据产品经理需要结合业务建立标签体系,背后真正的分析工作则由数据分析师来,数据分析该如何入门呢?
数据分析
数据分析可由数据产品经理+数据分析师一起完成,也可以数据产品经理+数据分析平台(bdp、神策等)。数据分析该如何入门和培养意识呢?
数据分析基础
想学习数据分析的同学不妨先从Excel开始,从熟悉excel的函数开始,掌握一些统计学基础。
- 均值:平均值, =AVERAGE(B2:B19),B2:B19为数据范围;
- 中位数:先将数据升序排列,若为数据个数为单数,则为中间那个数,若为偶数,则为取中间两个数据的平均值,=MEDIAN(B2:B19);
- 众数:出现次数最多的数,=MODE(B2:B19);
- 方差:用来计算每一个变量(观察值)与总体均数之间的差异,=VAR(B2:B19)
- 标准差:方差开根号后为标准差,用于评估数据稳定性,=STDEV.S(B2:B19)
- 标准误差:是描述对应的样本统计量抽样分布的离散程度及衡量对应样本统计量抽样误差,=STDEV(B2:B19)/SQRT(COUNTA(B2:B19))
- 最大值:=MAX(B2:B19)
- 最小值: =MIN(B2:B19)
- 峰度:=KURT(B2:B19)
- 偏度:=SKEW(B2:B19)
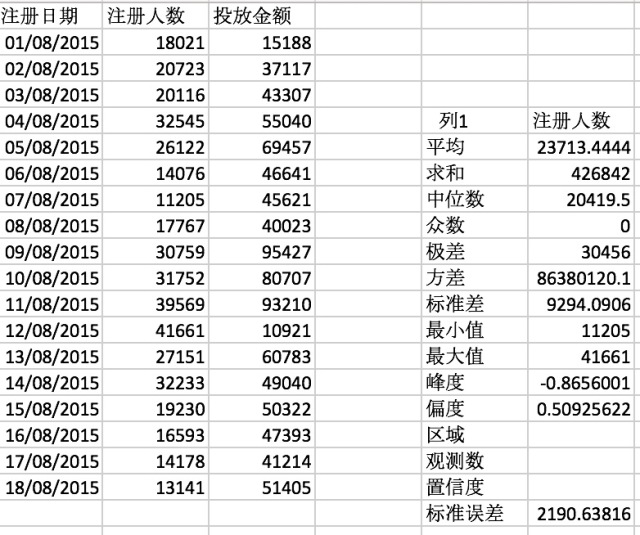
小作业,熟悉下excel的函数,微信公众号回复 “统计学基础” 可获得答案 (excel原文件)。
数据指标
什么是数据指标,炒股的人都会关注上证指数,互联网以用户为主,有着自己的指标。有个用户生命周期运营模型AARRR(Acquisition、Activation、Retention、Revenue、Refer),从新用户到流失的不同阶段。 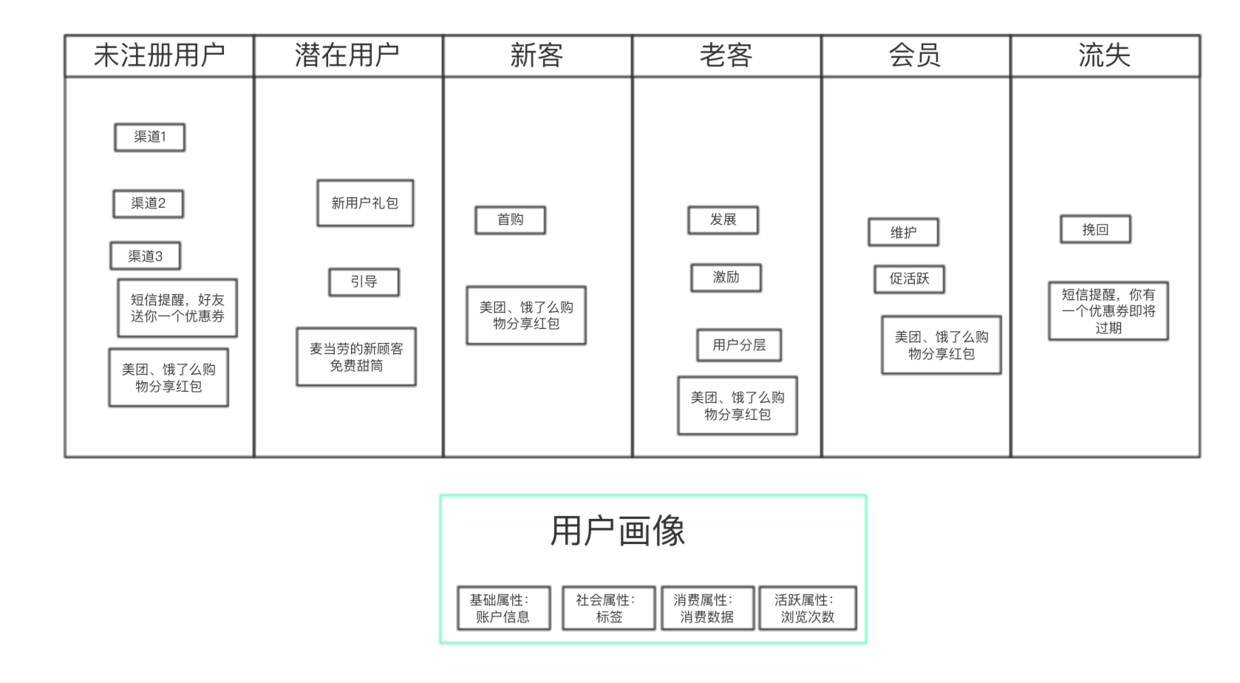
MAU:月度活跃 DAU:日活跃
透视表
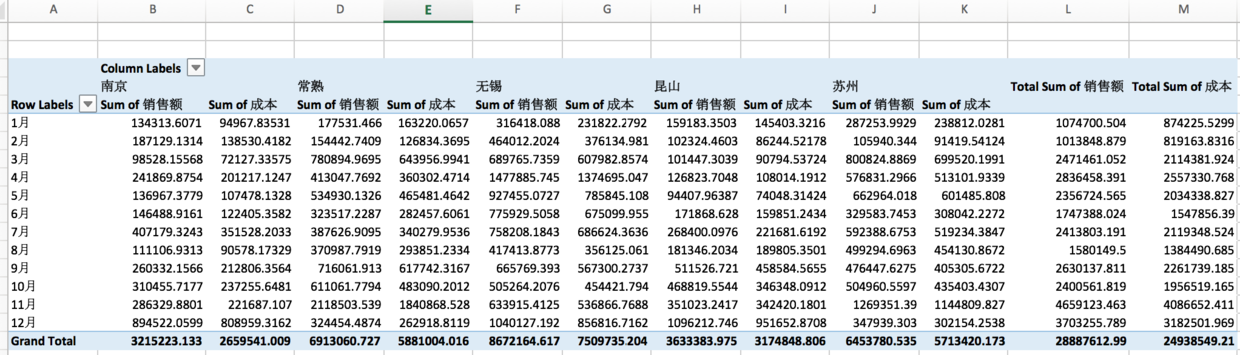
然后就是透视表了,生成透视表实际上是一个数据分析过程。而且百万数据内都可以用excel的数据透视表来分析。 举个例子,如何从1000条数据里清晰的看到每个月不同地区的销量情况,分析出每个月的利润呢? 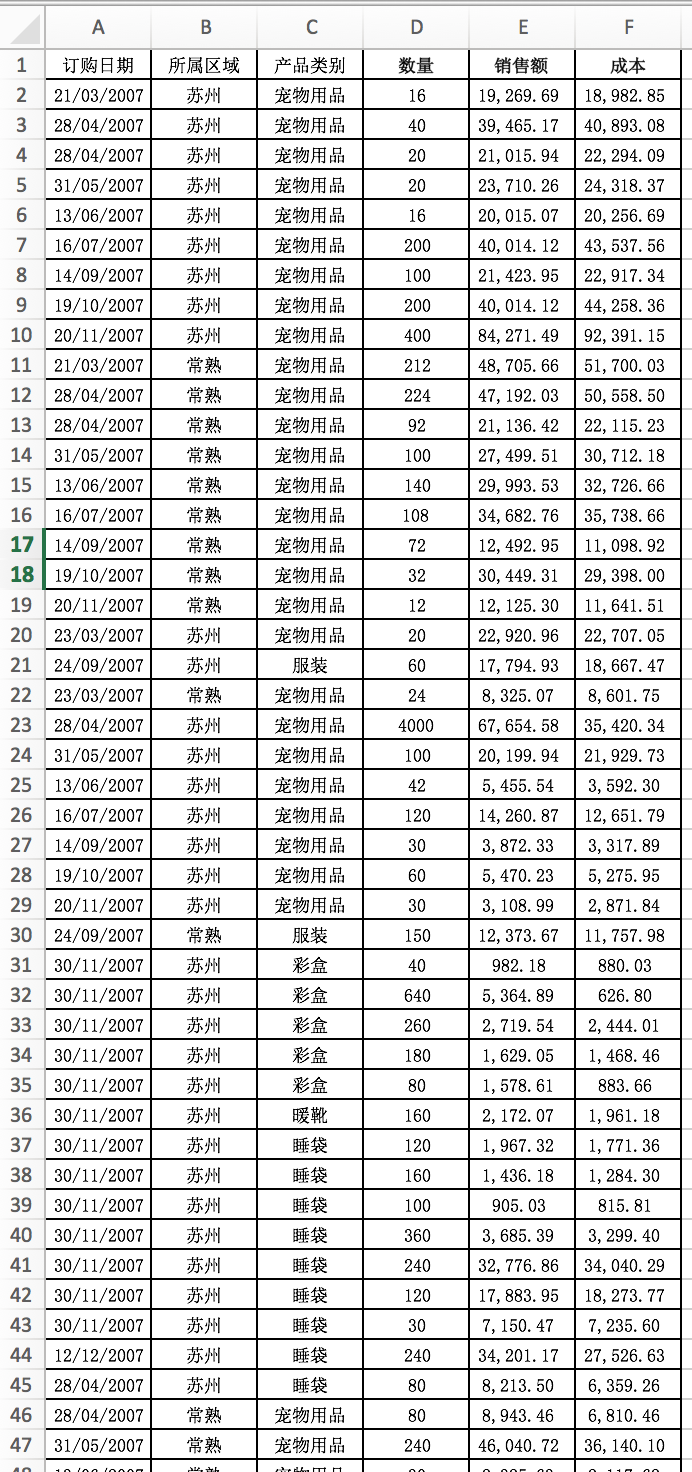
学习python

利用Python进行数据分析.pdf 下载地址 Python数据分析与挖掘实战

心理学
数据分析要结合心理

大数据“杀熟”?
微博网友“x师傅”讲述,他经常通过某旅行服务网站订某个特定价格酒店的房间,长年价格在380元到400元左右。 偶然一次,通过前台他了解到,淡季的价格在300元上下。他用朋友的账号查询后发现,果然是300元;但用自己的账号去查,还是380元。
5.2 小明的宠物-人工智能时代下崛起逆袭的Python
小奈:其实你们写的代码好像有不同派系的? 大仁:你是说编程语言?我来介绍下吧,我们来看下GitHub(程序员同城交友、代码协作平台)的数据,看下各种编程语言 Pull Requst的数据, Javascript的提交量最高,前端的鼎盛时期,python则处于飞速上升中,很有潜力。Java一直很稳,常年占据了后端主流编程语言第一。 
python热度为何持续上涨?

python可以用来干什么呢?
- 后端开发语言,常见开发架构django;
- 数据分析,常用库,pandas;
- 爬虫,scrapy;
- 人工智能,tensorflow。
人工智能和数据分析,近年来需求持续攀升,这方面人才待遇也是水涨船高,既然python那么能干,热度自然飞速上涨。
爬虫
说到数据分析,我们不得不说下数据来源,一般是内部数据,也有外部数据,外部数据的获取有很多种,最常见的方式就是爬虫了。 爬虫基于robots协议可以公开爬去网络上的信息。
python的工作原理
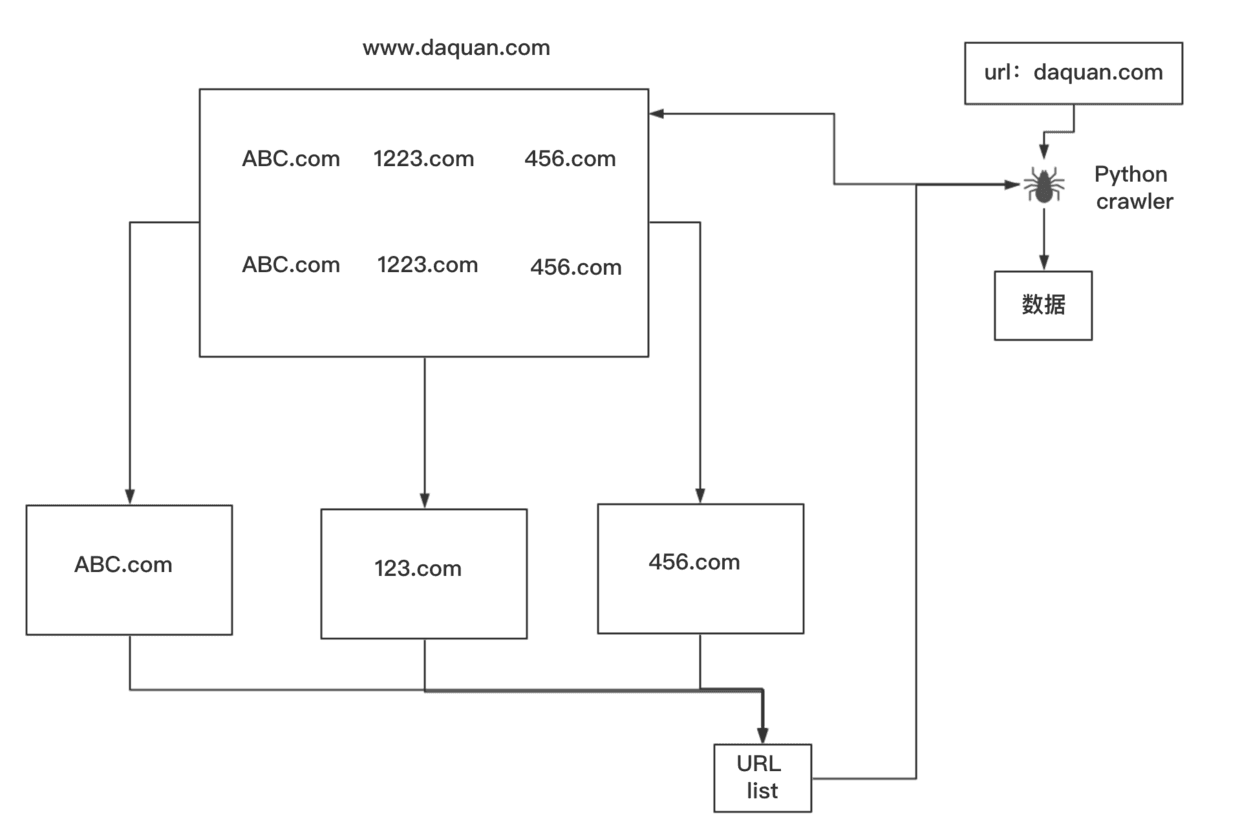
python中有成熟的爬虫框架(scrapy、bs4),只要你给爬虫一个网址,它就可以去爬取,和输入url类似却又不同,不同的是爬虫会把这些html文件里有用的信息抓取回来,而且爬虫可以爬取该网站相关的其它链接,像是daquan里的abc、123、456等。
小奈:爬取别人的信息会不会违法? 大仁:看你怎么爬取,其实有个爬虫协议(robots),每个网站都可以声明,其实就是声明那些文件可以、那些不可以,下面以淘宝网的robots.txt为例:
User-agent: Baiduspider Allow: /article Allow: /oshtml Disallow: /product/ Disallow: /
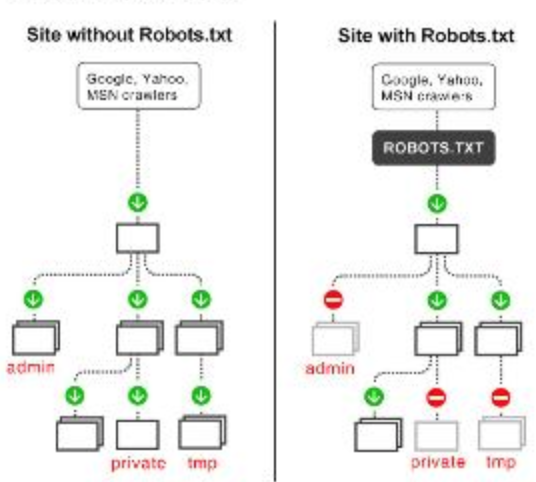
遵循robots协议后,爬取的数据不用于商用,基本上没事,商用的话目前还是灰色地带,混沌蛮荒阶段。
淘宝对百度的屏蔽
当年还可以在百度里搜索到淘宝商品信息,后来淘宝决定对搜索引擎实施不同程度的屏蔽,那时候淘宝体量还没那么大,屏蔽百度,会少了很多站外流量。但是这个关键性的决定,让用户心智统一(淘宝里才可以搜索商品),后面现金流般的淘宝广告就更不说了,站在当时,很考验产品决策人。
搜索引擎
爬虫似乎和搜索引擎密切相关,是的,是时候来科普下,搜索引擎的工作原理。 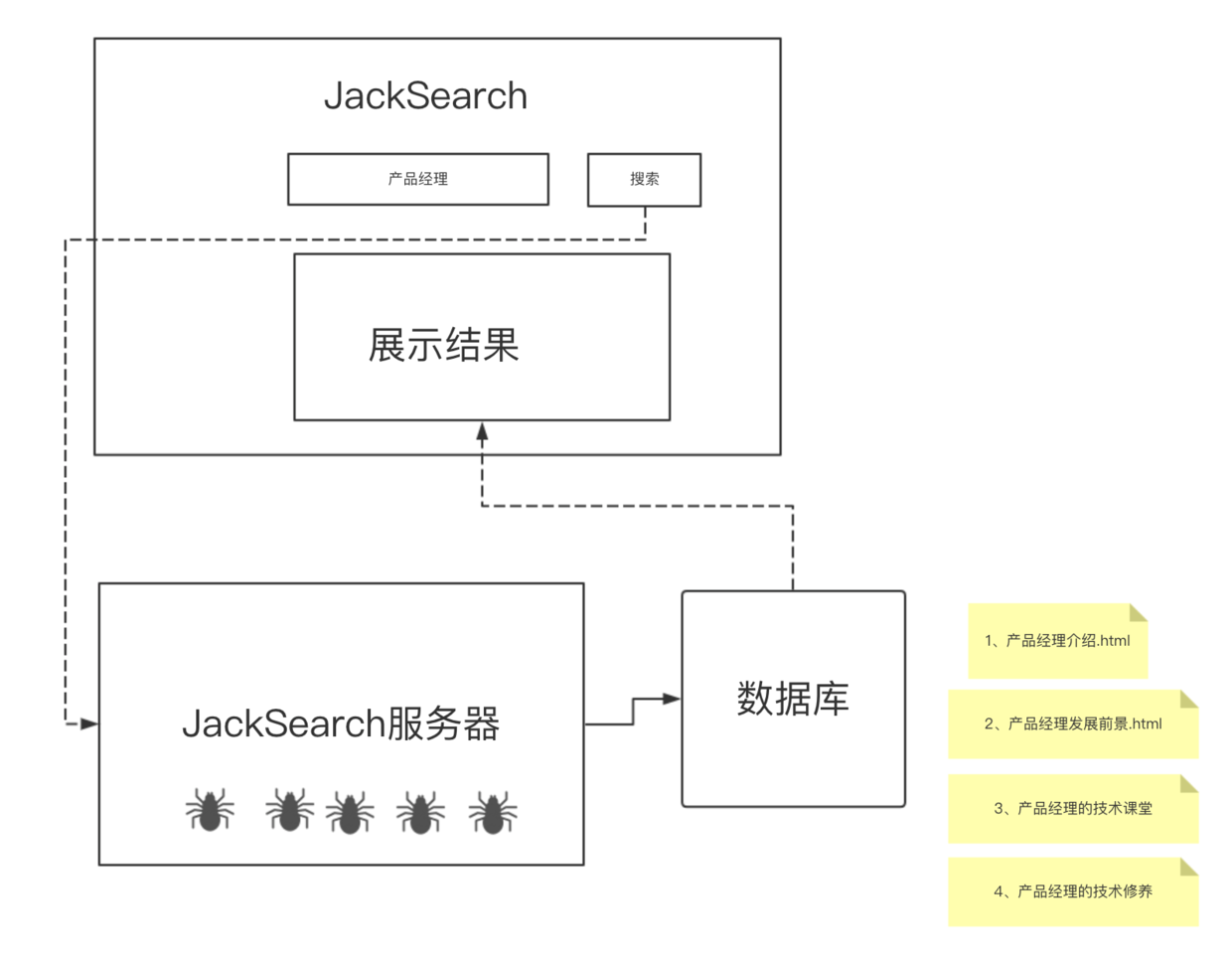
假如你在“JackSearch”,这个搜索引擎里,输入“产品经理”,那么当你点击搜索时,服务器就会去数据库查找,返回相关的文件信息,那么你就会问,这些文件是哪来的? 是爬虫们去网页世界里爬取的。
当然,搜索引擎远比这个复杂,爬虫抓取回来的信息,还需要存储,建立索引,这个推荐一本书,luence. 
ide

爬虫框架scrapy
Scrapy: Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。

数据存储
又双叒叕到了520

天龙八部
大家好,不知道大家看过,天龙八部没? “天龙八部”是哪八部?“天龙八部”都是“非人”,包括八种神道怪物,因为以“天”及“龙”为首,所以称为“天龙八部”。 八部者,一天,二龙,三夜叉,四乾达婆,五阿修罗,六迦楼罗,七紧那罗,八摩呼罗迦。
看完介绍,还是不懂,没关系,今天主要讲的是,用数据分析,天龙八部里,高频词语,人物关系,以及为什么你还是单身?
自己?
看到下面的词云,为什么”自己“这个词,那么高频?

乍看之下,段誉词频(1551)最高。其实要结合“业务”,实则乔峰才是正主。要从乔峰的身世说起,开头中,乔峰是丐帮帮主,后身世揭破,契丹人也,改名萧峰。 所以乔峰的词频(1900+)=乔峰(963)+萧峰(966)
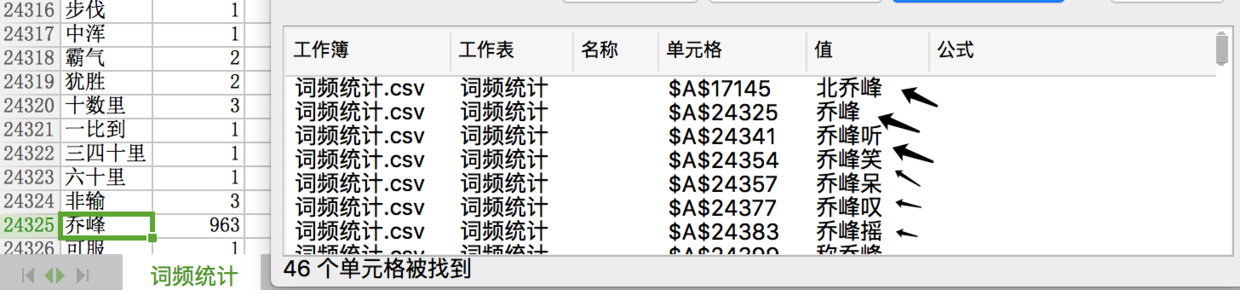
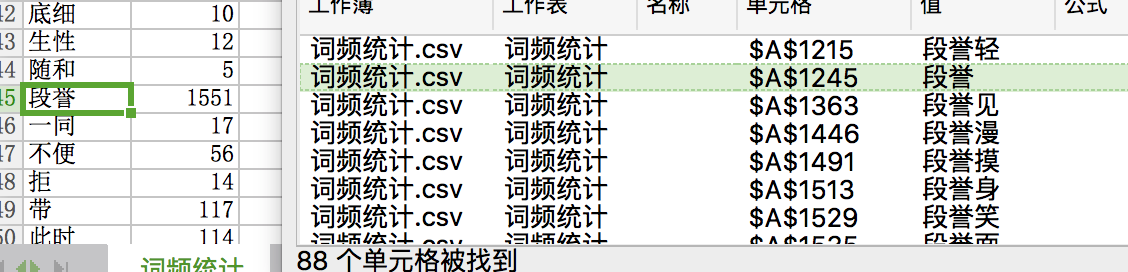
从词语中,我们可以看出,写作手法,乔峰(段誉)听/笑/呆/动词,所以人物+动词。
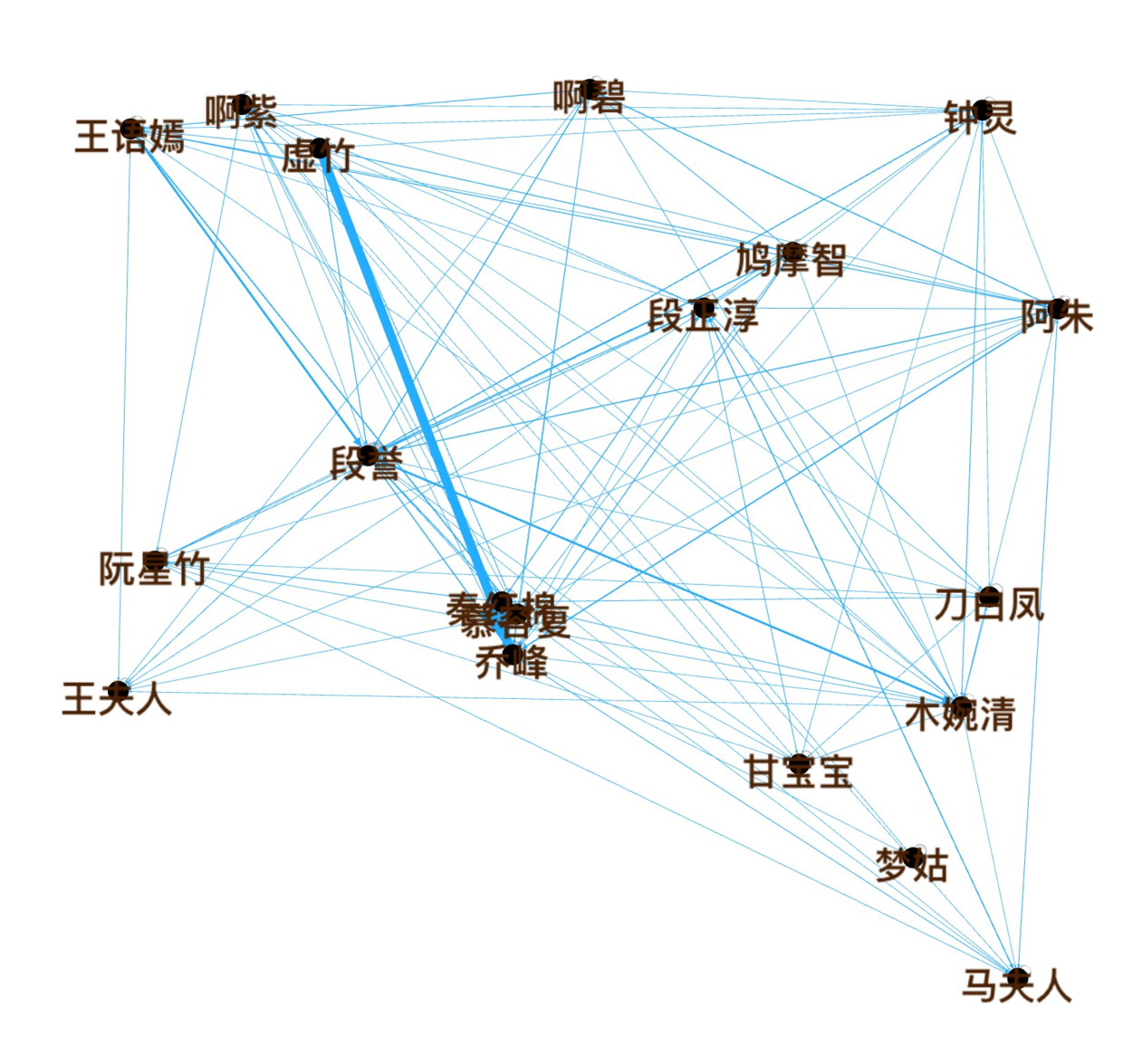
人物关系图
故事有好多条主线。 一、寻仇:其中虚竹和乔峰,为什么关系最亲密?因为虚竹的爸是杀死乔峰的爸的带头大哥,寻仇是小说的主线之一。
二、段正淳恋爱史:从另一角度看,可以说是,大理镇南王,段正淳恋爱史,他和几位女人谈恋爱,并生下的都全都是女儿,女儿再一个个,和段誉谈恋爱,搞得段誉很痛苦,最后发现自己,不是亲生的故事。 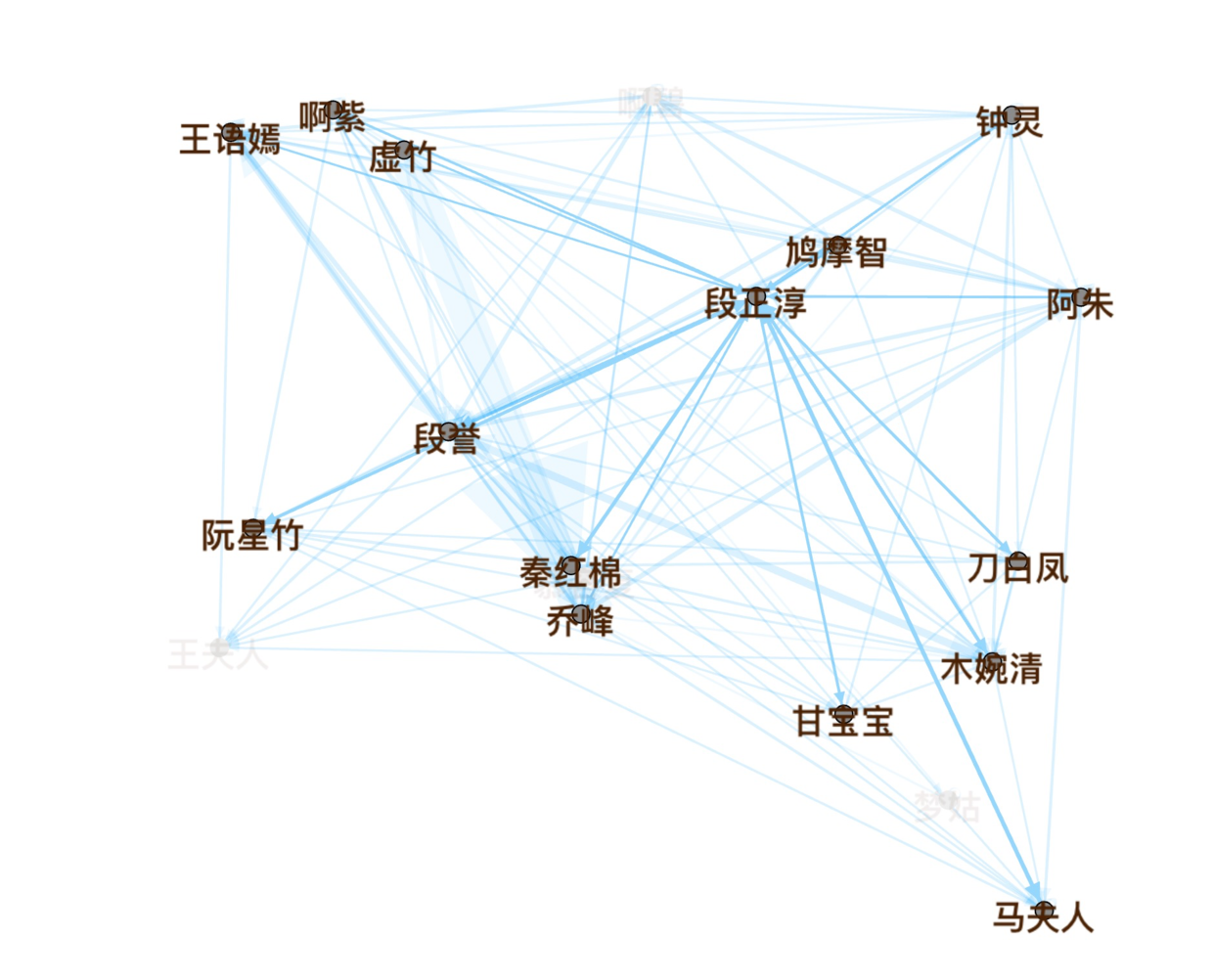
总结来说
故事是由“慕容博”和“段正淳”,两位大Boss挑起的,各负责一条主线。

慕容博想光复燕国,才策划杀死萧家,企图引起两国战乱,引起萧父报仇;
镇南王,则是负责拈花若草,一身情债,一个人很爽,搞得很多人很痛苦,最后自杀,搞得王夫人、马夫人,各种痛苦,阿朱得替父挡仇,被乔峰错手打死,乔峰痛苦,和段誉谈恋爱有都是自己的妹妹,妹妹、段誉都很痛苦,最后发现自己不是亲生的,释然了。
520又到了,为什么你还单身?

- 段正淳:拈花若草,大boss,没你就没那么多破事了,魅力指数10000。
- 虚竹:憨厚老实,杀人有艳福,从和尚到灵鹫宫主到附马,屌丝逆袭的故事,艳福指数1000;
- 段誉:始终如一,追了王姑娘,几十集电视剧,最后真情打动王语嫣,另一角度看,有点“备胎上位”的感觉,对么?幸福指数,500;
- 王语嫣:从小爱慕表哥,最后被拒,被段誉打动,幸福指数,400;
- 乔峰:丐帮帮主,侠之大者,身世悲惨,想和阿朱牧马放羊,却一掌错杀阿朱,为和平而死,幸福指数,100;
- 阿朱:小婢,从小没有父爱、母爱,一直崇拜乔峰,大英雄,为父挡仇,为“孝”牺“爱”,幸福指数,100;
- 啊紫:执着,只爱乔峰一人,最后很痛苦就是了,痛苦指数5000;
看了那么多故事,依然谈不好恋爱,你们呢?
实战分割线
一、词云
这里主要用到了两个库,jieba分词用的,wordcloud词云用,matplib显示用。
- 下载小说txt文件;
- 准备一张mask(遮罩)图片;
- 字体; “`
coding:utf-8
from os import path from collections import Counter import jieba from PIL import Image import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud, STOPWORDS
if name==’main‘:
#读取文件
d = path.dirname(__file__)
pardir = path.dirname(d)
pardir2 = path.dirname(pardir)
cyqf = path.join(pardir2,'tlbbqf/')
text = open(path.join(d,'tlbb.txt'), encoding="utf-8", errors="surrogateescape").read()
jieba_word = jieba.cut(text, cut_all=False) #cut_all 分词模式
data = []
for word in jieba_word:
data.append(word)
dataDict = Counter(data)
with open('./词频统计.csv', 'w', encoding='utf-8') as fw:
for k,v in dataDict.items():
fw.write("%s,%d\n" % (k,v))
mask = np.array(Image.open(path.join(d, "mask.png")))
font_path=path.join(d,"font.ttf")
stopwords = set(STOPWORDS)
wc = WordCloud(background_color="white",
max_words=2000,
mask=mask,
stopwords=stopwords,
font_path=font_path)
# 生成词云
wc.generate(text)
# 生成的词云图像保存到本地
wc.to_file(path.join(d, "wordcloud.png"))
# 显示图像
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()
#二、人物关系图
- 统计词频
text = open(path.join(d,’tlbb.txt’), encoding=”utf-8″, errors=”surrogateescape”).read() jieba_word = jieba.cut(text, cut_all=False) #cut_all 分词模式 data = [] for word in jieba_word: data.append(word) dataDict = Counter(data)
“`
计算人物之间矩阵关系
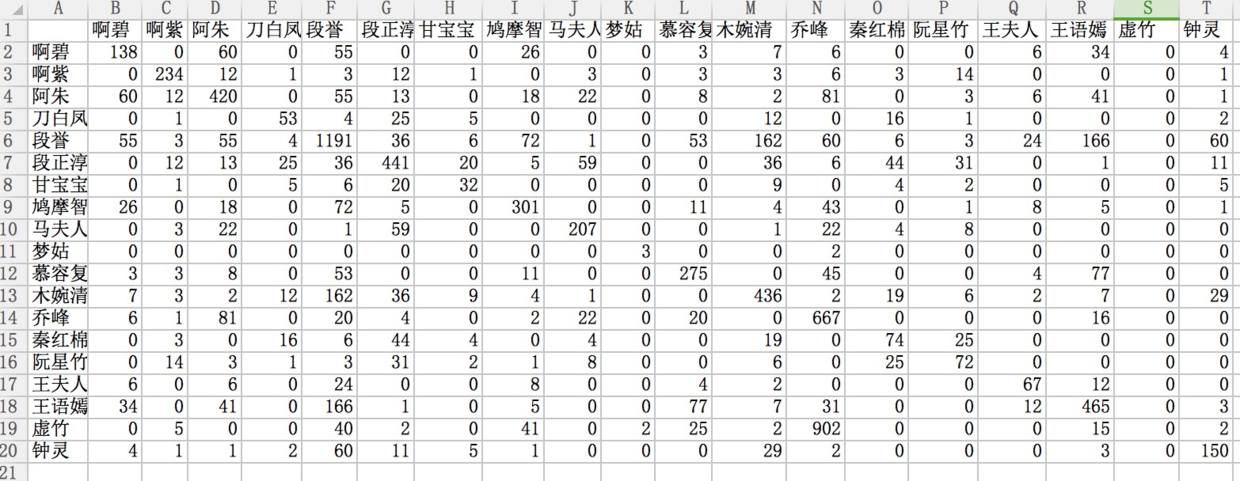
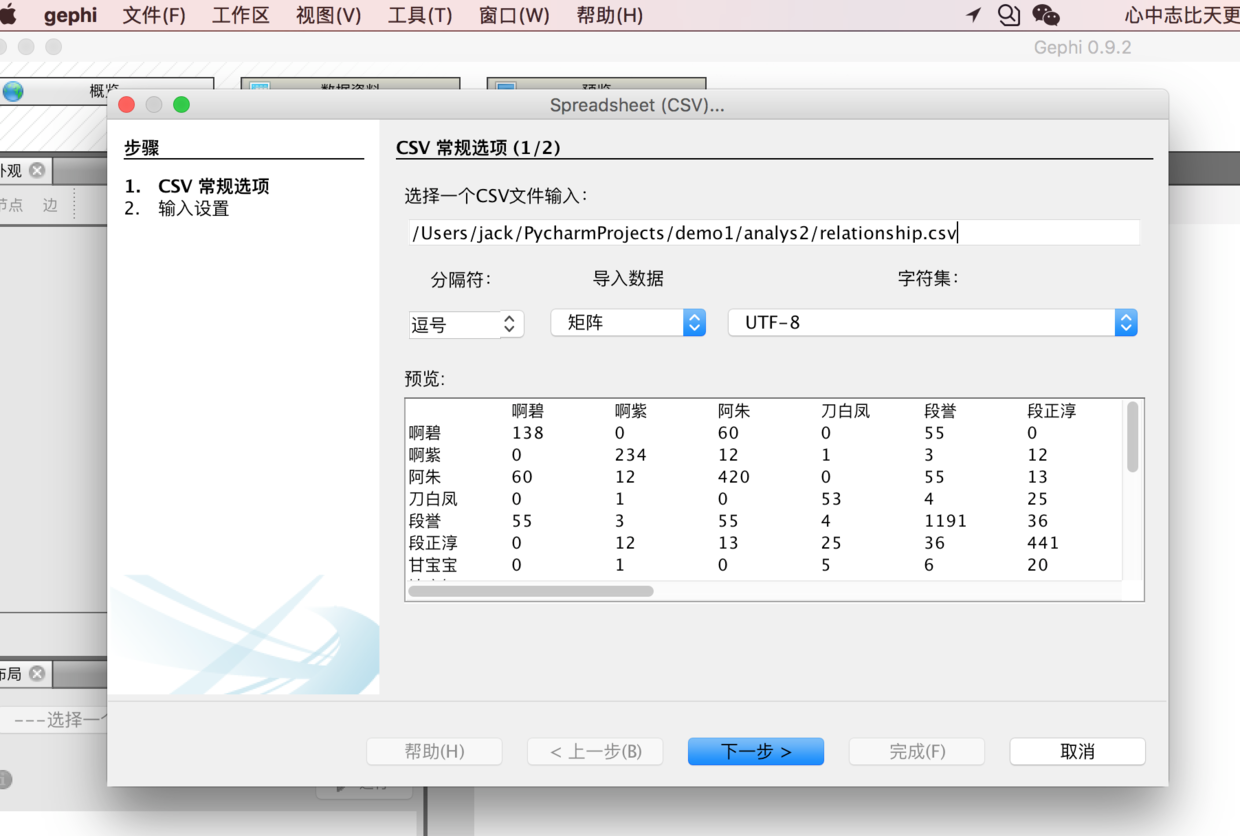
用gephi画出人物关系 首先是导入关系图,逗号、矩阵、utf-8;
然后就是箭头,第一个是显示节点信息,第二、三是调整连线的粗细、颜色;
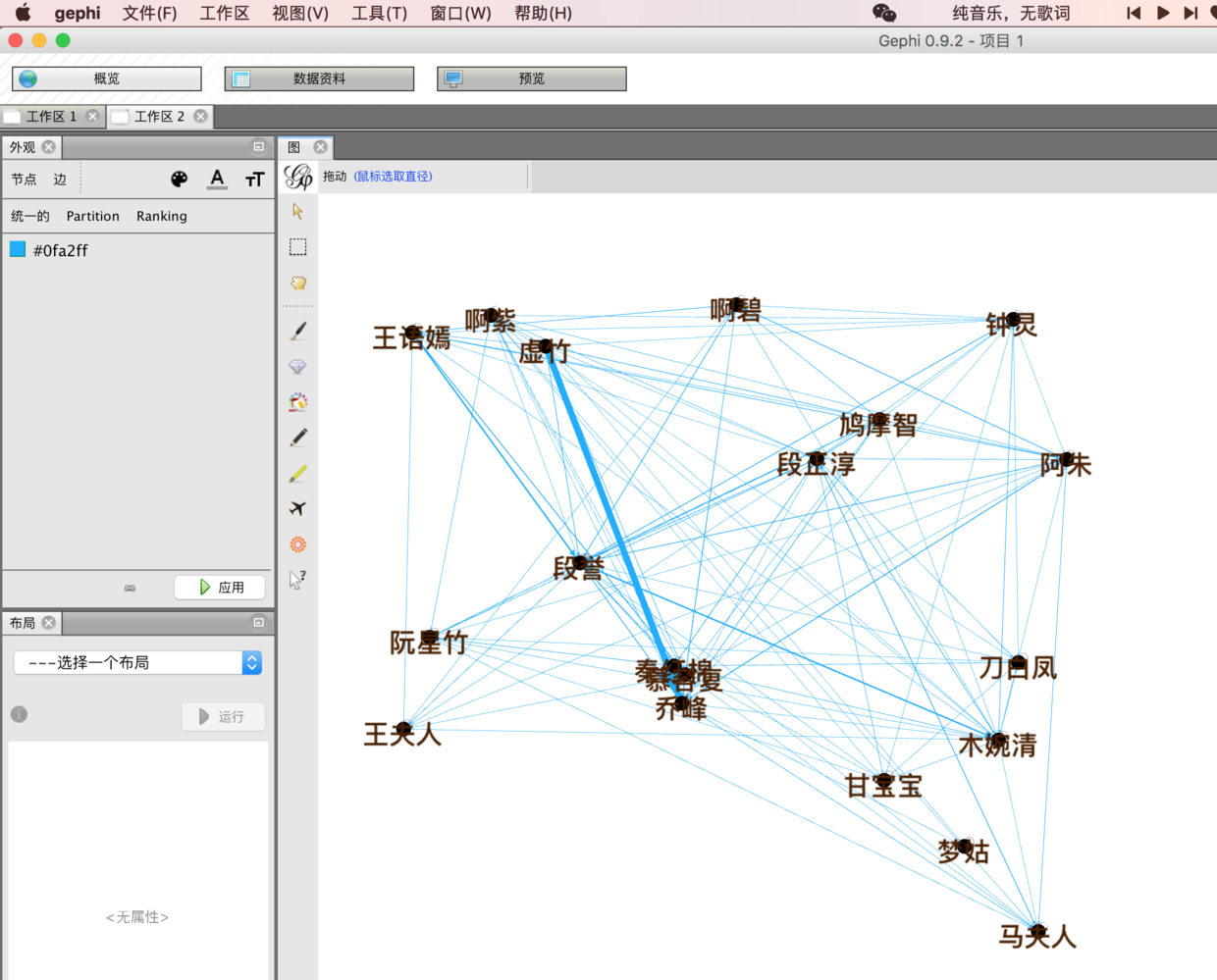
 点击某个节点,例如段誉,可以侧重显示他的人物关系。
点击某个节点,例如段誉,可以侧重显示他的人物关系。
来源:PMskill产品社区 http://www.pmskill.net/techbook
既然来了,说些什么?