登顶全球最权威AI性能基准评测,百度飞桨给分布式训练创造了标杆
大模型时代,飞桨产业级平台的优势开始显现。
从问答、翻译、作画再到写论文,最近一段时间,实现各种神奇能力的 AI 总有个「大模型」的称号。
在工业界,大模型也被视为重要的发展方向,它既可以减少机器学习训练对数据标注的需求,又无需手写专家知识,降低了 AI 应用的行业门槛。在业界和一些科学领域,人工智能已经进入了「炼大模型」的新阶段。
然而天下没有免费的午餐,大模型带来了 AI 能力的突破,也对算力提出了无穷无尽的需求。芯片制造商和科技公司都在寻找提升 AI 训练效率的方法。国内 AI 技术领先的百度,最近展示了真正的技术。
11 月 10 日,机器学习基准测试平台 MLPerf 放出了最新一期榜单,在 BERT 模型训练排行榜上,百度使用飞桨框架提交的 8 机 64 卡配置在同等 GPU 配置下获得第一名[1]。而 BERT 模型中的 Transformer 结构正是目前主流大模型的基础架构。
百度提交的方案中,64 块 GPU 在 149 秒内训练了 BERT 模型。在国际权威基准测试中取得领先,体现了飞桨框架在分布式训练性能上的优势,其中用到的技术也已成为百度业务创新的重要组成部分。
在最权威的基准平台打榜
MLPerf 是目前国际公认的权威 AI 性能评测基准,由图灵奖得主大卫 · 帕特森(David Patterson)联合学术机构和企业在 2018 年 5 月创立。它通过一套规则和最佳实践,解决了一直以来机器学习系统化评估困难的问题。

该基准覆盖计算机视觉、自然语言处理、推荐系统、强化学习等方向。要求参与者在指定数据集上训练经典算法达到一定精度,同时对提交的处理细节进行仔细标注,另外还要开源代码,公布包括算力设施,CPU、GPU 等处理器型号数量,使用的机器学习框架甚至加速库等信息,以确保可复现性。
由于严谨客观的标准,MLPerf 一直以来吸引了芯片厂商和科技公司不断将最新、最强大的软硬件解决方案提交到榜单中互相比较。
在最新的 MLPerf v2.1 版本上,百度参与的自然语言处理赛道要求训练 BERT Large 模型,比较语言模型准确率(Masked Language Model Accuracy)训练至 72% 的端到端时间。作为 NLP 领域的知名模型之一,BERT 使用的 Transformer 架构正是如今很多大规模预训练模型的基础。
本次评测共有 21 个公司和机构参与。百度提出的方法在端到端训练时间和训练吞吐两个指标上均超越了同等 GPU 配置下的所有对手。
百度工程师表示,模型训练不仅需要考虑纯粹的 GPU 算力,还与深度学习前向、反向计算的速度,以及数据 IO 和通信效率有很大关联。除了硬件和服务器组织结构之外,此类任务也对于软件框架提出了很高的要求。
这并不是百度第一次在 MLPerf 上出成绩:在 6 月 30 日发布的 v2.0 榜单中,飞桨在 8 卡 GPU 单机配置下已经实现了 BERT 模型训练性能排名第一,比其他提交结果速度快了 5% 到 11% 不等[2]。
百度在 v2.1 中提交的多机评测结果进一步印证了飞桨分布式训练的性能表现,其提供的方案,在同等 GPU 配置下端到端训练收敛时间比其它提交结果快 1% 到 20%,在训练吞吐量上比其他提交结果要快 2% 到 12%。
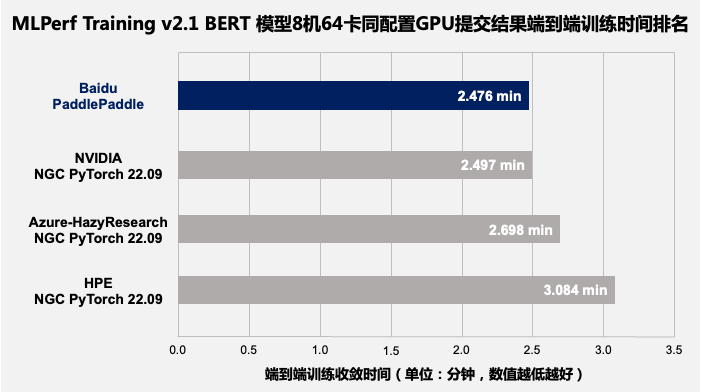
MLPerf Training v2.1 BERT 模型端到端训练收敛时间排名(8 机 64 卡 GPU)。
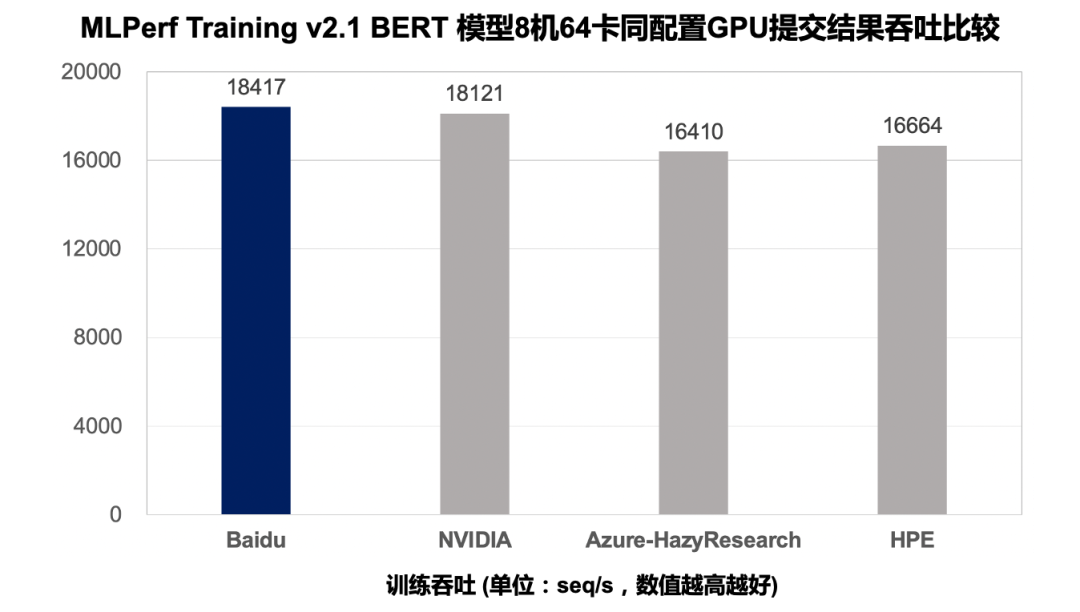
MLPerf Training v2.1 BERT 模型提交结果吞吐量比较(8 机 64 卡 GPU)。
值得一提的是,这个成绩还超过了 GPU 厂商英伟达使用自身高度定制化的 NGC PyTorch 框架跑出的性能数据。
让 8 块 GPU 跑出等效 8.2 的算力
MLPerf 基准测试上获得的高速度,得益于飞桨框架在分布式训练核心技术上的持续探索和创新。
本次百度参加的是多节点分布式训练的赛道。在跨设备并联计算的情况下,飞桨解决了一些此前单机训练时无法遇到的挑战,优化范围包括设备间的负载均衡,以及 CPU、GPU 等异构算力的负载均衡。在跨设备通信的问题上,飞桨还使用了全局通信与分层次通信相结合的方法提高通信效率。
首先,为了提高 AI 模型的训练效率,系统需要对数据和模型进行切分,并制定策略让多个处理器分别计算其中的一部分。针对大规模稠密参数模型高效训练问题,飞桨在业内首创了 4D 混合并行训练策略,其包括张量模型并行、流水线模型并行、参数分组切片的数据并行和纯数据并行。
飞桨支持的重计算策略,在使用混合并行训练千亿级模型时可以用来增大 batch size。另一方面,作为一个独立通用的策略,重计算不依赖多卡并行。人们可以根据实际业务模型大小,及集群上的总卡数独立调节两个维度来达到更快训练大模型的目的。
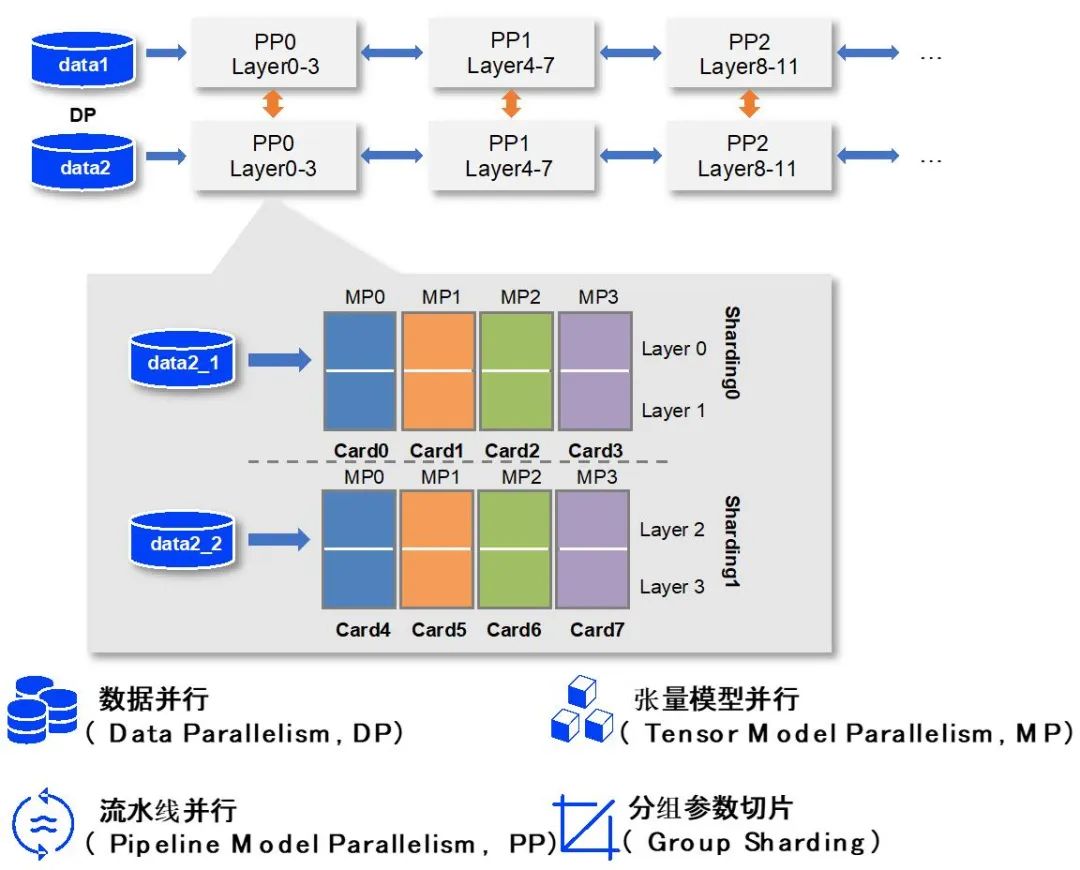
4D 混合并行策略示意图。
在 MLPerf BERT 模型训练任务上,基于飞桨的混合并行策略,百度的 8 机 64 卡相对于单机的扩展效率达到了 94%,实现了接近线性的性能增长。
针对分布式训练调优困难的问题,飞桨提出了端到端自适应分布式训练架构,其可以将异构算力资源转化成统一的集群资源视图,通过端到端代价模型建模选择最优策略,然后使用异步流水运行的机制开始训练。如果部分设备出现故障或增减算力时,弹性资源管理机制可以触发训练架构各个模块自动做出反应。
在 MLPerf BERT 模型训练任务上,飞桨根据集群通信拓扑特点并结合 NCCL SHARP 协议,使用全局通信与分层次通信结合的方式降低整体通信耗时,有效提升了模型训练性能。
针对分布式训练经常出现的负载不均、数据加载速度瓶颈等问题,飞桨利用异构设备混合负载均衡方案,根据不同设备的特点把任务分配到效率最高的算力上。在 MLPerf 训练任务上,飞桨通过使用 GPU 高带宽通信解决了模型训练启动时的数据加载慢问题,又用 CPU 异构设备通信实现了模型训练过程与数据负载均衡间的重叠,提高了模型训练效率。
另外,飞桨框架还在 Transformer 类模型底层提供了专门的高性能支持,对数据的输入、模型结构、算子实现等方面实现了优化。
值得一提的是,在数据并行优化的基础上,百度的方案在 8GPU 的机器上实现了超过 8 的效率——用框架的优化跑出了超过等效物理芯片数量的速度。
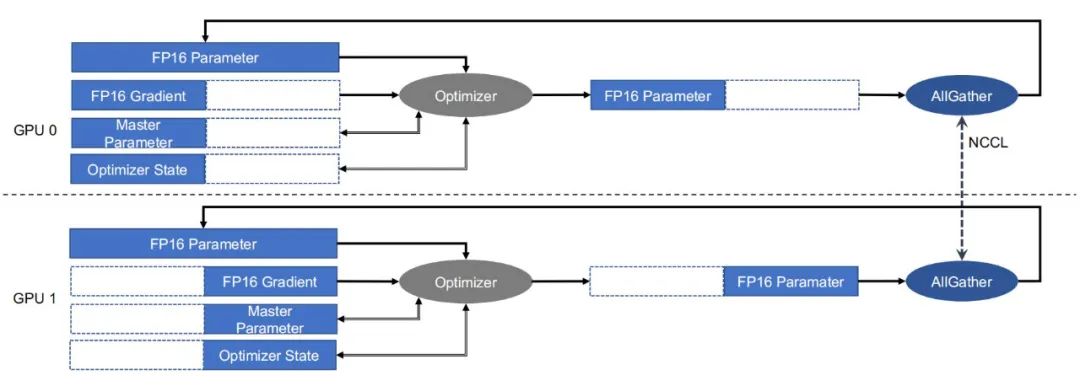
飞桨的分组参数切片混合并行策略示意图。
在多 GPU 计算单元机器学习并行运算时,各 GPU 的优化器计算部分是冗余重复的。飞桨优化了冗余重复计算的部分,让每张卡只需计算参数梯度的一部分,然后再进行聚合同步更新;在此基础上,结合分层参数切分与通信、跨 step 通信 – 计算重叠、多流并发参数广播、底层算子深度优化等方式,进一步提升分布式训练极致性能,实现了 1+1 大于 2 的效果。
发挥 AI 大模型全部潜力
在 AI 训练任务上,芯片决定了算力的理论上限,服务器和集群的整合可以保证基础的运行效率,而最终能充分发挥计算潜力的是深度学习框架。
百度飞桨在 MLPerf 上连续两次第一的成绩其实源于一次小尝试。早在半年前,飞桨就已实现了目前的多机分布式优化能力,但并没有直接向 MLPerf 提交多服务器的成绩,只用单机优化成绩就拿到了第一。
据介绍,上一次没有提交多机分布式训练结果的部分原因在于百度内部算大模型的需求太大,一时计算资源过于紧张——在百度内部每时每刻都有训练大模型的需求。
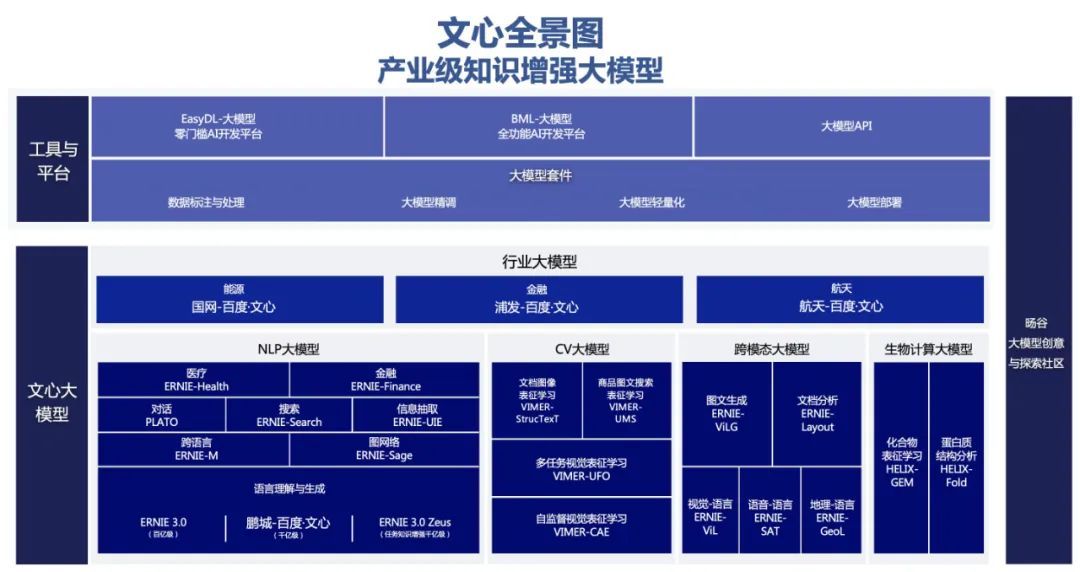
如今的「文心大模型」已经覆盖了从 NLP、CV、跨模态到生物计算等领域二十多个大模型,而飞桨一直在为大模型的训练和推理提供技术支撑。这正是飞桨所擅长的工作:作为面向生产环境的深度学习平台,飞桨因大规模 AI 计算而生,自诞生以来一直在百度业务实践中被不断改进,基础训练性能也一路提升。
结合计算机视觉、自然语言处理、科学计算等领域的应用,飞桨研发了异构硬件下的低存储和高性能训练技术,相继发布了业界首个通用异构参数服务器架构、4D 混合并行训练策略、端到端自适应分布式训练架构等多项领先技术成果。
它们支持了百度在大模型领域的快速迭代,百度在此基础上相继发布了全球首个知识增强千亿大模型「鹏城 – 百度 · 文心」[3]、全球首个百亿参数中英文对话预训练生成模型 PLATO-XL、全球规模最大中文跨模态生成模型 ERNIE-ViLG、业界规模最大的多任务统一视觉大模型 VIMER-UFO。
目前,文心已发布 20 多个大模型,覆盖自然语言处理、计算机视觉、跨模态、生物计算等领域,赋能工业、能源、城市、金融等千行百业。
而飞桨在硬件生态上也已携手超过 30 家硬件厂商完成了深度融合优化,与英伟达、英特尔、瑞芯微、Arm、Imagination 等多家伙伴厂商展开了合作,针对不同应用场景和产品,共同推出了飞桨生态发行版、开源开放模型库,还包括一系列面向开发者的课程。
MLPerf 打榜之外,飞桨的自适应分布式训练架构在多个场景下得到了验证。在 GPT-3 千亿模型 GPU 训练场景下,经测试,飞桨训练性能达到训练硬件峰值性能的 51.3%,在同等实验环境下超越业界同类实现(DeepSpeed/Megatron-LM);而在「鹏城 – 百度 · 文心」千亿大模型的训练上,飞桨支持的性能达到同规模、非自适应架构下的性能的 2.1 倍[3]。
此外,在蛋白质结构预测领域,飞桨创新性地提出了「分支并行 – 动态轴并行 – 数据并行」的混合并行策略,性能提升 36% 以上[4],并在国产硬件集群上将 AlphaFold2 千万级别蛋白 initial training 阶段从 7 天压缩到了 2.6 天。在稀疏门控混合专家并行领域,飞桨提出了 Task MoE 分布式训练架构和基于 Task 的负载均衡机制,同等实验环境下训练性能比 PyTorch 提升 66%,有力支撑文心 VIMER-UFO 2.0 大模型高效训练。
AI 对于大规模计算的需求仍在不断增长,在不久的将来,我们可能会见证全新架构的芯片和算法出现。百度的工程师们表示,期待未来能够出现算法、硬件和框架能够出现高度协同的设计,让 AI 在设计之初就充分考虑可计算性,从基础上充分优化性能。
与此同时,飞桨正在软硬协同性能优化和大规模分布式训练、推理等方向持续创新,为广大用户提供广泛适配、性能优异的产业级深度学习平台。
最新的消息是:在 11 月 30 日即将举行的 Wave Summit + 深度学习开发者峰会上,飞桨即将发布新版本,并推出有关大模型的全新工具。
大模型的大规模产业应用,离我们越来越近了。
参考文献
[1]MLPerf Training v2.1 Results. https://mlcommons.org/en/training-normal-21/
[2]MLPerf Training v2.0 Results. https://mlcommons.org/en/training-normal-20/
[3]ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation. Shuohuan Wang, et al. arXiv preprint arXiv: 2112.12731, 2021.
[4]Efficient AlphaFold2 Training using Parallel Evoformer and Branch Parallelism. Guoxia Wang, et al. arXiv preprint arXiv: 2211.00235, 2022.
原文:https://mp.weixin.qq.com/s/x1-VzhYJ4X9PxSnoeEaseQ
既然来了,说些什么?